
1. Overview
Natural Language Processing (NLP) is one of the hottest fields in Artificial Intelligence (AI), now primarily referring to large language models. This is thanks to applications that people are enthusiastic about, such as text generators that can write stories, chatbots that can deceive people, and text-to-image programs that produce photo-realistic images. In recent years, the ability of computers to understand human language, programming languages, and even biological and chemical sequences similar to language (such as DNA and protein structures) has undergone a revolution. The latest AI models are unlocking these areas to analyze the meaning of input text and generate meaningful and impactful outputs (you know what I mean).

Natural Language Processing (NLP) has evolved from computational linguistics, which uses computer science to understand language principles. However, NLP is not about developing theoretical frameworks; it is an engineering discipline aimed at building technologies to accomplish useful tasks. NLP can be divided into two overlapping subfields: Natural Language Understanding (NLU), which focuses on semantic analysis or determining the intended meaning of text; and Natural Language Generation (NLG), which focuses on machine-generated text. NLP is separate from speech recognition but is often used in conjunction, where speech recognition aims to parse spoken words into text.
2. Task List
NLP is used for various language-related tasks, including answering questions, classifying text in various ways, and conversing with users.
Here are the tasks that NLP can address:
Sentiment Analysis: This is the process of classifying the emotional intent of text. Generally, the input to a sentiment classification model is a piece of text, and the output is the probability that the expressed sentiment is positive, negative, or neutral. Typically, this probability is based on manually generated features, word n-grams, TF-IDF features, or using deep learning models to capture long-term and short-term dependencies. Sentiment analysis is used to classify customer reviews on various online platforms.
Toxicity Classification: This is a branch of sentiment analysis that aims not only to classify hostile intent but also to classify specific categories such as threats, insults, obscenity, and hatred against certain identities. The input to this model is text, and the output is usually the probability of each category of toxicity. Toxicity classification models can be used to moderate and improve online conversations by suppressing aggressive comments, detecting hate speech, or scanning documents for defamation.
Machine Translation: This can automatically translate between different languages. The input to this model is text in a specified source language, and the output is text in a specified target language. Google Translate is perhaps the most famous example, although Baidu Translate (specifically for English to Chinese) seems to have higher accuracy in recent years.
Named Entity Recognition: This is used to extract entities from a piece of text into predefined categories such as names, organizations, locations, and quantities. The input to this model is usually text, and the output is various named entities along with their start and end positions. Named entity recognition is very useful in applications such as summarizing news articles and combating misinformation.
Spam Detection: This is a common binary classification problem in NLP, aiming to classify emails as spam or non-spam. Spam detectors take the text of the email along with various other contextual elements such as the subject line and sender’s name as input. Their goal is to output the probability that the email is spam. Many email providers use such models to provide a better user experience by detecting unsolicited and unwanted emails and moving them to designated spam folders.
Grammar Error Correction: Models encode grammar rules to correct grammar in text. This is primarily viewed as a sequence-to-sequence task, where the model is trained with ungrammatical sentences as input and correct sentences as output.
Topic Modeling: This is an unsupervised text mining task that takes a corpus of documents and discovers abstract topics within that corpus. The input to a topic model is a collection of documents, and the output is a list of topics that define the words for each topic and the distribution of each topic in the documents. Latent Dirichlet Allocation (LDA) is one of the most popular topic modeling techniques, which attempts to view documents as a collection of topics and topics as a collection of words. Topic modeling is commercially used to help lawyers find evidence in legal documents.
Text Generation: More formally known as Natural Language Generation (NLG), it generates text that is similar to human-written text. These models can be fine-tuned to generate different types and formats of text, including articles, blogs, and even computer code. Text generation is performed using Markov processes, LSTM, BERT, GPT-2, LaMDA, and other methods. It is particularly useful for autocomplete and chatbots.
Autocomplete Functionality: This can predict the next word to appear, and various levels of autocomplete systems are used in some chat applications. Search engines use autocomplete to predict search queries. GPT-2 is one of the most famous autocomplete models, which has been used to write articles, lyrics, and more.
Chatbots: They can be divided into two categories: (1) Database Query: We have a database of questions and answers, and we want users to query it using natural language. (2) Dialogue Generation: These chatbots can simulate conversations with human partners. Some can engage in extensive dialogue. An example is Google’s LaMDA, which provides human-like answers to questions to the extent that one of its developers believes it has feelings.
Information Retrieval: This finds the documents most relevant to a query. This is the problem faced by every search and recommendation system. The goal is not to answer a specific query, but to retrieve the most relevant set from a potentially millions of documents. Document retrieval systems mainly perform two processes: indexing and matching.
In most modern systems, indexing is accomplished through vector space models of two-tower networks, while matching is done using similarity or distance scores.
Search engines integrate their search capabilities with multimodal information retrieval models that can handle text, image, and video data.
Summarization:
This is the task of extracting the most relevant information. Summarization can be divided into two method classes:
(1) Extractive Summarization, which focuses on extracting the most important sentences from long texts and combining them to form a summary. Typically, extractive summarization scores each sentence in the input text and then selects several sentences to form the summary.
(2) Abstractive Summarization generates summaries through paraphrasing. This is similar to writing a summary that contains words and sentences not present in the original text. Abstractive summarization is often modeled as a sequence-to-sequence task, where the input is long-form text, and the output is the summary.
Question Answering:
This involves answering questions posed by humans in natural language. Generally, there are two types of question-answering tasks:
(1) Multiple Choice: A multiple-choice question consists of a question and a set of possible answers. The learning task is to select the correct answer.
(2) Open Domain: In open-domain question answering, the model typically queries a large amount of text to provide answers to questions in natural language without providing any options.
3. How It Works
The way NLP models work is by looking for relationships between components of language, such as letters, words, and sentences in a text dataset. NLP architectures use various methods for data preprocessing, feature extraction, and modeling.
Data Preprocessing: Before a model processes the text for a specific task, preprocessing is often needed to improve model performance or convert words and characters into a format that the model can understand. Data-centric AI is an evolving movement that prioritizes data preprocessing. Various techniques can be used in this data preprocessing:
Stemming and Lemmatization: Stemming is an informal process that uses heuristic rules to convert words to their base forms. For example, “university,” “universities,” and “university’s” might all map to the base “univers.” (One limitation of this method is that “universe” could also map to “univers,” even though “universe” and “university” do not have a close semantic relationship.) Lemmatization is a more formal method that uses a dictionary to analyze the morphology of words to find their roots. Stemming and lemmatization are provided by libraries such as spaCy and NLTK.
Sentence Segmentation: This breaks down large chunks of text into sentence units that have linguistic meaning. This is evident in languages like English, where sentence endings are marked by periods, but it is still non-trivial. Periods can be used to mark abbreviations as well as terminate sentences, in which case the period should be part of the abbreviation itself. For languages that do not have markers for sentence-ending delimiters (e.g., Classical Chinese), the process becomes more complex.
Stop Word Removal: This aims to remove the most frequently occurring words that do not add much information to the text. For example, “the,” “a,” “an,” etc.
TOKENIZERS: These split text into individual words and word segments. The result typically consists of word indices and tokenized text, where words can be represented as numerical tokens for various deep learning methods. Methods to indicate to language models to ignore unimportant tokens can improve efficiency.
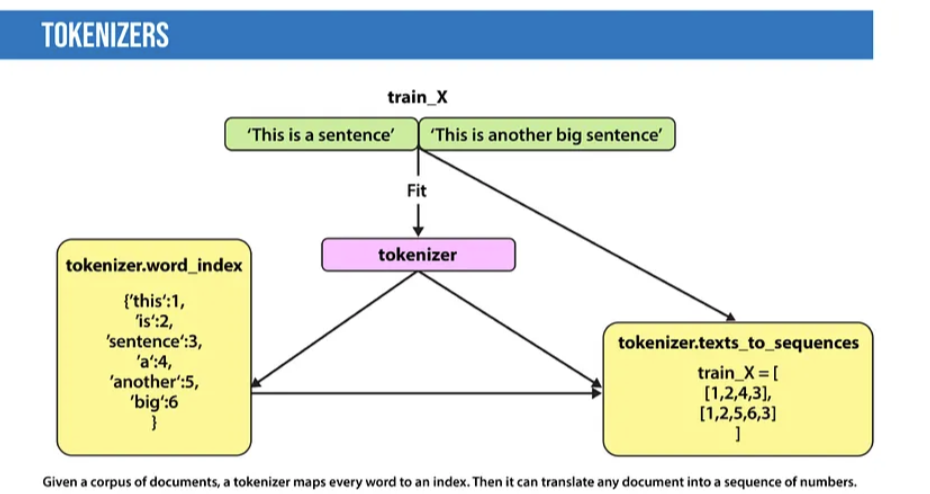
Feature Extraction: Most traditional machine learning techniques are based on features (often numerical that describe the relationship of documents to the corpus containing them), which are created by bag-of-words, TF-IDF, or general feature engineering (e.g., document length), word polarity, and metadata (e.g., if the text has associated tags or scores). Recent techniques include Word2Vec, GLoVE, and learning features during neural network training.
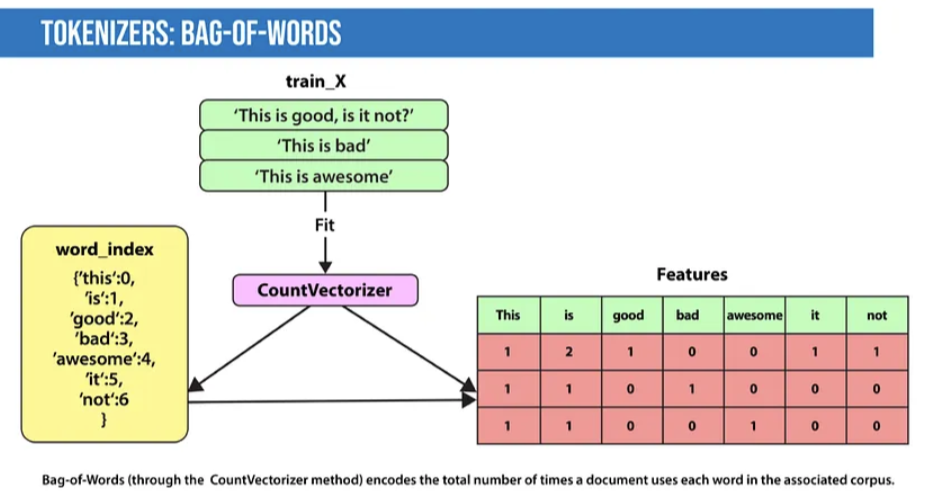
Bag-of-Words: The Bag-of-Words model counts the occurrence of each word or n-gram (a combination of n words) in a document. For example, the following bag-of-words model creates a numerical representation of the dataset based on the number of occurrences of each word in the document according to word_index.
Word2Vec was introduced in 2013 and learns high-dimensional word embeddings from raw text using ordinary neural networks. It has two variants: Skip-Gram (which attempts to predict surrounding words given a target word) and Continuous Bag-of-Words (CBOW) (which attempts to predict the target word from surrounding words). After training, these models take a word as input and output a word embedding, which can be used as input for many NLP tasks. The embeddings from Word2Vec capture context. If specific words appear in similar contexts, their embeddings will be similar.
GLoVE is similar to Word2Vec in that it also learns word embeddings, but it does so using matrix factorization techniques rather than neural learning. The GLoVE model builds a matrix based on global word co-occurrence counts.
Modeling: After data has been preprocessed, it will be input into the NLP architecture, which models the data to accomplish various tasks.
The numerical features extracted through the aforementioned techniques can be input into various models based on the task at hand. For example, for classification, the output of a TF-IDF vectorizer can be provided to logistic regression, naive Bayes, decision trees, or gradient boosting trees. Alternatively, for named entity recognition, we can use Hidden Markov Models and n-grams.
Deep neural networks typically work without using extracted features, although we can still use TF-IDF or bag-of-words features as input.
Language Models: In very basic terms, the goal of a language model is to predict the next word given a stream of input words.
Deep learning is also used to create such language models. Deep learning models take word embeddings as input and return a probability distribution of the next word at each time state as the probabilities for each word in the dictionary. Pre-trained language models learn the structure of a specific language by processing large corpora (e.g., Wikipedia). They can then be fine-tuned for specific tasks. For instance, BERT has been fine-tuned for tasks ranging from fact-checking to writing headlines.
4. NLP Technologies
1. Traditional Machine Learning NLP Techniques
Logistic Regression is a supervised classification algorithm designed to predict the probability of an event occurring based on certain inputs. In Natural Language Processing, logistic regression models can be used to address problems such as sentiment analysis, spam detection, and toxicity classification.
Naive Bayes is a supervised classification algorithm that uses the following Bayesian formula to find the conditional probability distribution P(label | text):
P(label | text) = P(label) x P(text|label) / P(text)
and makes predictions based on which joint distribution has the highest probability. The naive assumption in Naive Bayes models is that individual words are independent. In NLP, such statistical methods can be used to solve problems like spam detection or finding bugs in software code.
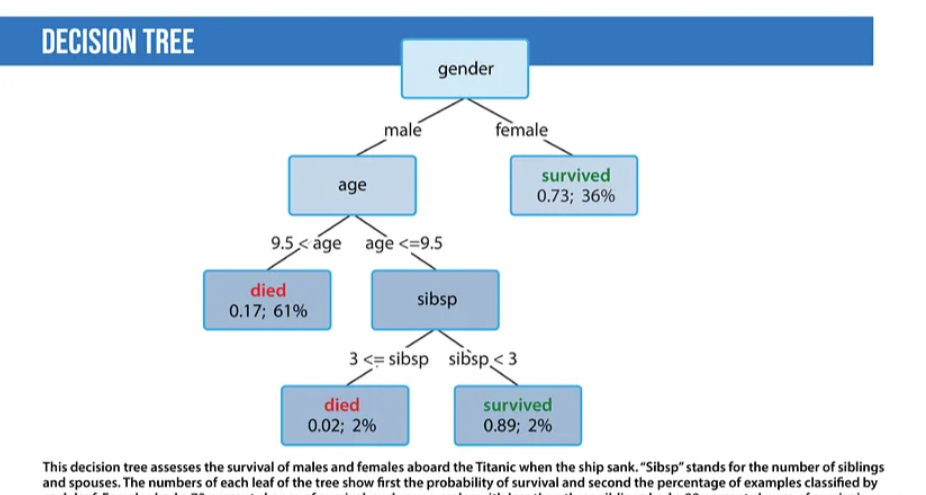
Decision Trees are a class of supervised classification models that segment datasets based on different features to maximize the information gain in those segments.
Latent Dirichlet Allocation (LDA) is used for topic modeling. LDA attempts to view documents as collections of topics and topics as collections of words. LDA is a statistical method. The intuition behind it is that a small portion of words in the corpus can describe any topic.
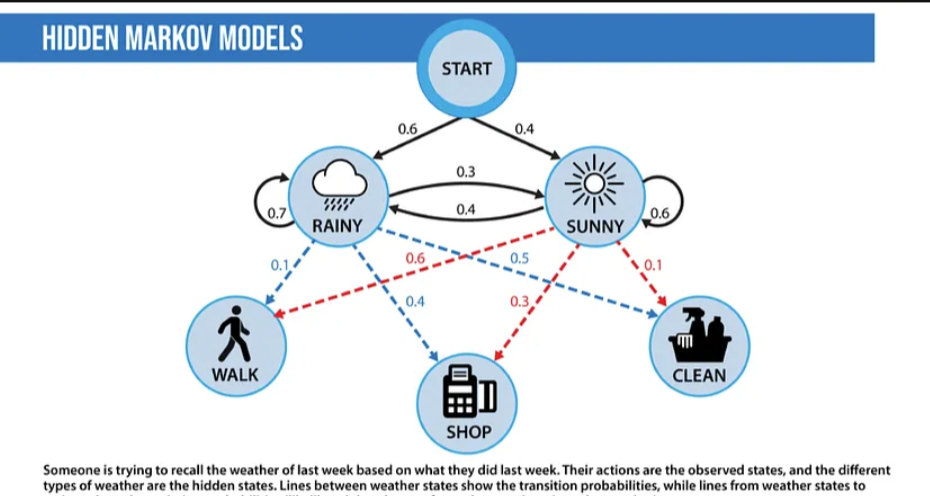
Hidden Markov Models: A Markov model is a probabilistic model that determines the next state of a system based on the current state. For example, in NLP, we might suggest the next word based on the previous word. We can model this as a Markov model, where we might find the transition probability from word1 to word2, i.e., P(word1|word2).
We can then use the product of these transition probabilities to find the probability of a sentence. Hidden Markov Models (HMM) are a probabilistic modeling technique that introduces hidden states into a Markov model. Hidden states are attributes of data that cannot be directly observed. HMM is used for Part-of-Speech (POS) tagging, where the words in a sentence are observed states, and the POS tags are the hidden states. HMM introduces a concept called emission probability; the probability of observation given a hidden state. In the previous example, this is the probability of a word given a particular POS tag. HMM assumes that this probability can be inverted: given a sentence, we can calculate the POS tag for each word based on the likelihood of a word having a specific POS tag and the probability of that specific POS tag. POS tagging follows the POS tags assigned to the previous word. In practice, this is solved using the Viterbi algorithm.
2. Deep Learning NLP Techniques
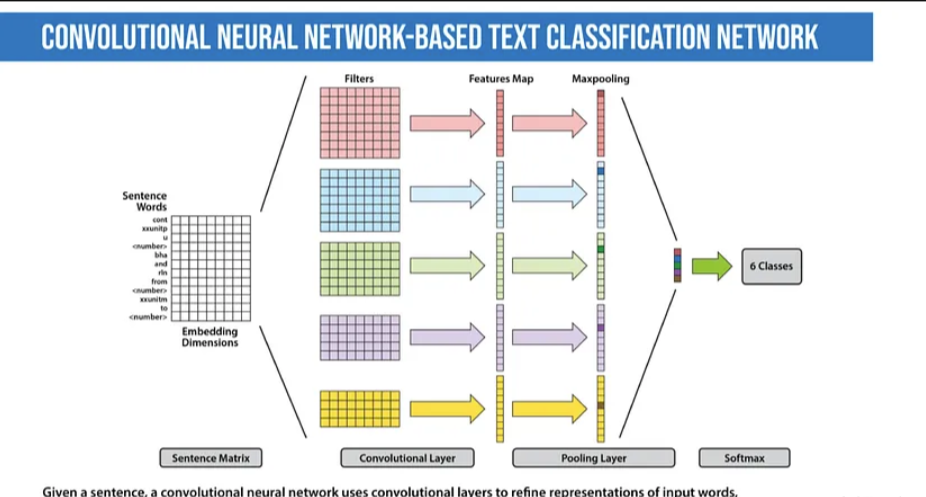
Convolutional Neural Networks (CNN): The idea of using CNN for text classification was first proposed in Yoon Kim’s paper “Convolutional Neural Networks for Sentence Classification.” The core intuition is to treat documents as images. However, the input is not pixels but sentences or documents represented as word matrices.
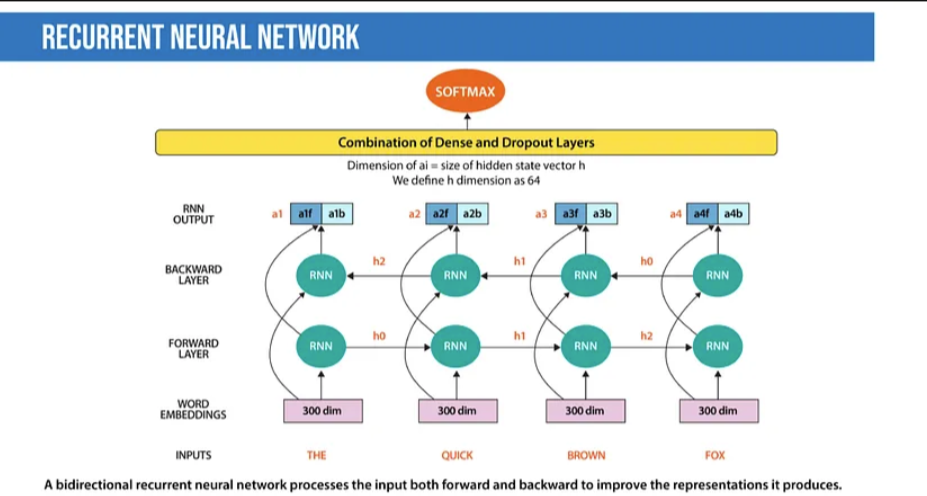
Recurrent Neural Networks (RNN): Many text classification techniques using deep learning utilize n-grams or windows (CNN) to process adjacent words. They can treat “New York” as a single instance. However, they cannot capture the context provided by specific text sequences. They do not learn the sequential structure of the data, where each word depends on the previous word or words in the previous sentence. RNNs use hidden states to remember previous information and connect it to the current task. Architectures called Gated Recurrent Units (GRU) and Long Short-Term Memory (LSTM) are types of RNNs designed to remember information over long periods. Additionally, bidirectional LSTM/GRU retains contextual information from both directions, which aids in text classification. RNNs have also been used to generate mathematical proofs and translate human thoughts into text.
Autoencoders: These are deep learning encoder-decoder models that approximate a mapping from X to X, i.e., input = output. They first compress the input features into a low-dimensional representation (sometimes called latent codes, latent vectors, or latent representations) and learn to reconstruct the input. The representation vectors can be used as input for separate models, so this technique can be used for dimensionality reduction. Among many other fields, geneticists have applied autoencoders to discover mutations associated with diseases in amino acid sequences.
Encoder-Decoder Sequence-to-Sequence: The encoder-decoder seq2seq architecture is an adaptation of autoencoders specialized for tasks like translation and summarization. The encoder encapsulates the information in the text into an encoding vector. Unlike autoencoders, the decoder’s task is not to reconstruct the input from the encoding vector but to generate different desired outputs, such as translations or summaries.
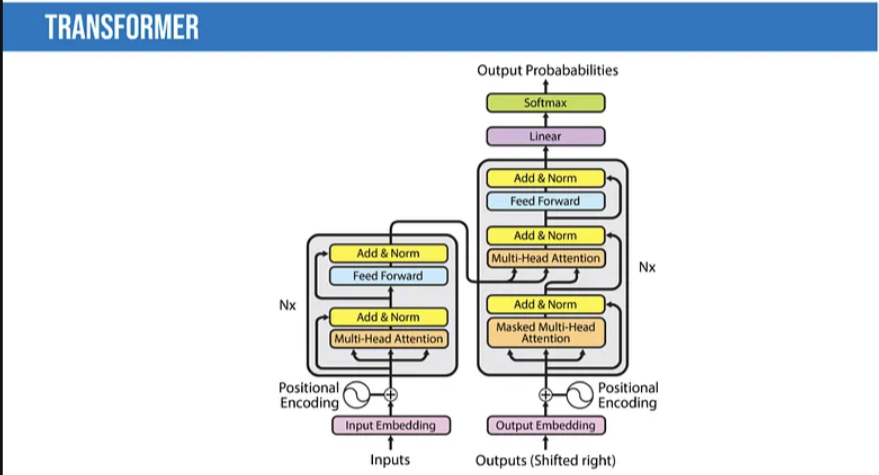
Transformers: The Transformer is a model architecture first described in the 2017 paper “Attention Is All You Need” (Vaswani, Shazeer, Parmar, et al.) that abandons recursion and relies entirely on self-attention mechanisms to map the global dependencies between input and output. Because this mechanism processes all words at once (rather than one at a time), it reduces training speed and inference costs compared to RNNs, especially since it is parallelizable. In recent years, the Transformer architecture has revolutionized NLP, producing models like BLOOM, Jurassic-X, and Turing-NLG. It has also been successfully applied to various visual tasks, including creating 3D images.
5. Six Important NLP Models
Eliza was developed in the mid-1960s, attempting to solve the Turing Test; that is, to deceive people into thinking they were conversing with another person rather than a machine. Eliza used pattern matching and a set of rules but did not encode the language context.
Tay was a chatbot launched by Microsoft in 2016. It tweeted like a teenager and learned from conversations with real users on Twitter. The bot adopted phrases from users who posted sexist and racist comments, and Microsoft soon disabled it. Tay confirmed some points raised in the “Random Parrot” paper, particularly the dangers of not eliminating data biases.
The BERT Series: Many deep learning models in NLP are named after Muppet characters, including ELMo, BERT, Big BIRD, ERNIE, Kermit, Grover, RoBERTa, and Rosita. Most of these models excel at providing contextual embeddings and enhanced knowledge representations.
The Generative Pre-trained Transformer 3 (GPT-3) is a model with 175 billion parameters that can write original prose at a level of fluency comparable to humans based on input prompts. This model is based on the transformer architecture. The previous version, GPT-2, was open-source. Microsoft obtained exclusive licensing to access the underlying model of GPT-3 from its developer OpenAI, but other users can interact with it through an application programming interface (API). Several organizations, including EleutherAI and Meta, have released open-source interpretations of GPT-3.
The Dialogue Application Language Model (LaMDA) is a conversational chatbot developed by Google. LaMDA is a transformer-based model trained on dialogue rather than the usual web text. The system is designed to provide intelligent and specific responses to conversations. Google developer Blake Lemoine began to believe that LaMDA was sentient. Lemoine had detailed conversations with the AI about its rights and personhood.
In one of these conversations, the AI changed Lemoine’s perspective on Isaac Asimov’s Third Law of Robotics. Lemoine claimed that LaMDA was sentient, but this idea was met with skepticism by many observers and commentators. Subsequently, Google placed Lemoine on administrative leave for disseminating proprietary information and eventually fired him.
Mixture of Experts (MoE): While most deep learning models use the same set of parameters to process each input, MoE models aim to provide different parameters for different inputs based on efficient routing algorithms to achieve higher performance. The Switch Transformer is an example of the MoE approach, aiming to reduce communication and computation costs.
6. Programming Languages, Libraries, and Frameworks for NLP
Natural Language Toolkit (NLTK) is one of the earliest NLP libraries written in Python. It provides easy-to-use interfaces for corpora and lexical resources (such as WordNet). It also offers a suite of text processing libraries for classification, tokenization, stemming, parsing, and semantic reasoning.
spaCy is one of the most general-purpose open-source NLP libraries. It supports over 66 languages. spaCy also provides pre-trained word vectors and implements many popular models such as BERT. spaCy can be used to build production-ready systems for named entity recognition, part-of-speech tagging, dependency parsing, sentence segmentation, text classification, lemmatization, morphological analysis, entity linking, and more.
Hugging Face provides open-source implementations and weights for over 135 state-of-the-art models. Models can be easily customized and trained.
Gensim provides vector space modeling and topic modeling algorithms.
R: Many early NLP models were written in R, and R is still widely used by data scientists and statisticians. Libraries for NLP in R include TidyText, Weka, Word2Vec, SpaCyR, TensorFlow, and PyTorch.