
This work was mainly completed by me and Hu Jie, the author of SENet. I would also like to thank my two mentors at HKUST, Chen Qifeng and Zhang Tong, for their discussions and suggestions.

Summary
Our contributions can be summarized as follows:
(1) We propose a new neural network operator (operator or op) called involution, which is lighter and more efficient than convolution, and is more concise than self-attention in form, achieving both accuracy and efficiency improvements in various visual task models.
(2) Through the structural design of involution, we are able to understand the classical convolution operation and the recently popular self-attention operation from a unified perspective.
-
Paper link: https://arxiv.org/abs/2103.06255
-
Code and model link: https://github.com/d-li14/involution
This part mainly comes from the original text Section 2, Section 3
Convolution
 , where
, where  and
and  are the number of output and input channels, respectively, and
are the number of output and input channels, respectively, and  represents the kernel size,
represents the kernel size,  is generally not written, indicating that the same kernel is shared across
is generally not written, indicating that the same kernel is shared across  pixels, i.e., spatial invariance, while each channel C has its own corresponding kernel, which is called channel specificity. The operation of convolution can be expressed as:
pixels, i.e., spatial invariance, while each channel C has its own corresponding kernel, which is called channel specificity. The operation of convolution can be expressed as:
 is the input tensor,
is the input tensor,  is the output tensor, and
is the output tensor, and  is the convolution kernel.
is the convolution kernel.-
Spatial Invariance
 , 2. Translation equivariance, which can also be understood as producing similar responses to similar patterns in space. Its shortcomings are also very evident: the features extracted are relatively single and cannot flexibly adjust the parameters of the convolution kernel based on different inputs.
, 2. Translation equivariance, which can also be understood as producing similar responses to similar patterns in space. Its shortcomings are also very evident: the features extracted are relatively single and cannot flexibly adjust the parameters of the convolution kernel based on different inputs. , where the number of channels C is often hundreds or even thousands, to limit the scale of parameters and computational load, K is often set to a small value. We have become accustomed to using
, where the number of channels C is often hundreds or even thousands, to limit the scale of parameters and computational load, K is often set to a small value. We have become accustomed to using  sized kernels since VGGNet, which limits the convolution operation’s ability to capture long-range relationships at once and relies on stacking multiple
sized kernels since VGGNet, which limits the convolution operation’s ability to capture long-range relationships at once and relies on stacking multiple  sized kernels, which is less effective for modeling the receptive field compared to directly using larger convolution kernels.
sized kernels, which is less effective for modeling the receptive field compared to directly using larger convolution kernels.-
Channel Specificity
 sized matrix, where the rank of the matrix does not exceed
sized matrix, where the rank of the matrix does not exceed  , indicating that many kernels are approximately linearly dependent.
, indicating that many kernels are approximately linearly dependent.Involution
 , where
, where  indicates that all channels share G kernels. The operation of involution is expressed as:
indicates that all channels share G kernels. The operation of involution is expressed as:
 is the involution kernel.
is the involution kernel. sized image as input, the weights trained cannot be transferred to downstream tasks with larger input image sizes (such as detection, segmentation, etc.). The general form of the involution kernel generation is as follows:
sized image as input, the weights trained cannot be transferred to downstream tasks with larger input image sizes (such as detection, segmentation, etc.). The general form of the involution kernel generation is as follows:
 is an index set of the neighborhood at coordinate (i,j), thus
is an index set of the neighborhood at coordinate (i,j), thus  represents a patch containing
represents a patch containing  on the feature map.
on the feature map. , various design approaches can be explored further. Starting from a simple and effective design concept, we provide a bottleneck structure similar to SENet for experimentation:
, various design approaches can be explored further. Starting from a simple and effective design concept, we provide a bottleneck structure similar to SENet for experimentation: is taken as
is taken as  this single point set, i.e.,
this single point set, i.e.,  is taken as a single pixel at coordinate (i, j) on the feature map, thus obtaining one instantiation of the involution kernel generation.
is taken as a single pixel at coordinate (i, j) on the feature map, thus obtaining one instantiation of the involution kernel generation.
 and
and  are linear transformation matrices, r is the channel reduction ratio, and
are linear transformation matrices, r is the channel reduction ratio, and  is the intermediate BN and ReLU.
is the intermediate BN and ReLU.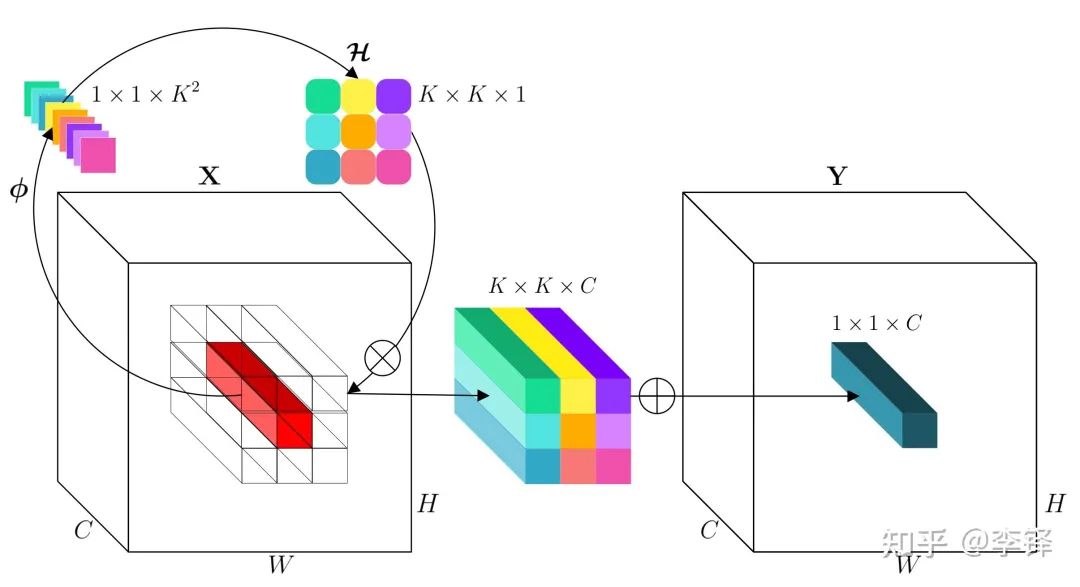
 (FC-BN-ReLU-FC) and reshape (channel-to-space) to expand into the shape of the kernel, thus obtaining the corresponding involution kernel at this coordinate point, then performing Multiply-Add with the feature vector of the neighborhood of this coordinate point on the input feature map to obtain the final output feature map. The specific operation process and tensor shape changes are as follows:
(FC-BN-ReLU-FC) and reshape (channel-to-space) to expand into the shape of the kernel, thus obtaining the corresponding involution kernel at this coordinate point, then performing Multiply-Add with the feature vector of the neighborhood of this coordinate point on the input feature map to obtain the final output feature map. The specific operation process and tensor shape changes are as follows:
 is the neighborhood around the coordinate (i,j). A simple pseudo-code implementation based on PyTorch API is as follows:
is the neighborhood around the coordinate (i,j). A simple pseudo-code implementation based on PyTorch API is as follows:
 , the computational load is divided into kernel generation and Multiply-Add (MAdd) two parts
, the computational load is divided into kernel generation and Multiply-Add (MAdd) two parts  , which is significantly lower than the number of parameters
, which is significantly lower than the number of parameters  and computational load
and computational load  .
.-
Sharing kernels across channels (only G kernels) allows us to use larger spatial spans (increasing K), thus enhancing performance through spatial dimension design while maintaining efficiency through channel dimension design (see ablation in Tab. 6a, 6b). Even if weights are not shared across different spatial positions, it will not lead to a significant increase in the number of parameters and computational load.
-
Although we do not directly share kernel parameters at every pixel in space, we share meta-parameters (meta-weights, i.e., the parameters of the kernel generation function) at a higher level, so we can still share and transfer knowledge across different spatial positions. In contrast, even if we completely relax the restrictions on sharing kernel parameters in space for convolution, allowing each pixel to freely learn its corresponding kernel parameters, such an effect would not be achievable.
[Discussion] Correlation with Self-Attention
This part mainly comes from the original text Section 4.2
Self-Attention
 ,
, are the input
are the input  after linear transformation to obtain query, key, and value, H is the number of heads in multi-head self-attention. The subscript indicates the query-key matching between pixels (i, j) and (p, q),
after linear transformation to obtain query, key, and value, H is the number of heads in multi-head self-attention. The subscript indicates the query-key matching between pixels (i, j) and (p, q),  indicates the range of query(i,j) corresponding to the key, which may be
indicates the range of query(i,j) corresponding to the key, which may be  a local patch (local self-attention), or
a local patch (local self-attention), or  the full image (global self-attention).
the full image (global self-attention).
-
Different heads in self-attention correspond to different groups in involution (split in the channel dimension) -
The attention map of each pixel in self-attention  corresponds to each pixel’s kernel in involution
corresponds to each pixel’s kernel in involution 
 , then self-attention is also a certain instantiation of involution, thus we find that involution is a more general expression form.
, then self-attention is also a certain instantiation of involution, thus we find that involution is a more general expression form. corresponds to the linear transformation before the attention matrix multiplication for
corresponds to the linear transformation before the attention matrix multiplication for  , self-attention operations are generally followed by another linear transformation and residual connection, this structure corresponds exactly to our use of involution to replace the convolution in the ResNet bottleneck structure, where there are also two
, self-attention operations are generally followed by another linear transformation and residual connection, this structure corresponds exactly to our use of involution to replace the convolution in the ResNet bottleneck structure, where there are also two  convolutions for linear transformations before and after.
convolutions for linear transformations before and after. instead of
instead of  (
(  is the position encoding matrix). From our involution perspective, this is merely another form of kernel generation to instantiate involution.
is the position encoding matrix). From our involution perspective, this is merely another form of kernel generation to instantiate involution. ,
,  ), which also highlights that locality in CNN design remains a treasure, because even with global self-attention, the shallow layers of the network struggle to truly utilize complex global information.
), which also highlights that locality in CNN design remains a treasure, because even with global self-attention, the shallow layers of the network struggle to truly utilize complex global information.Vision Transformer
Experimental Results
ImageNet Image Classification
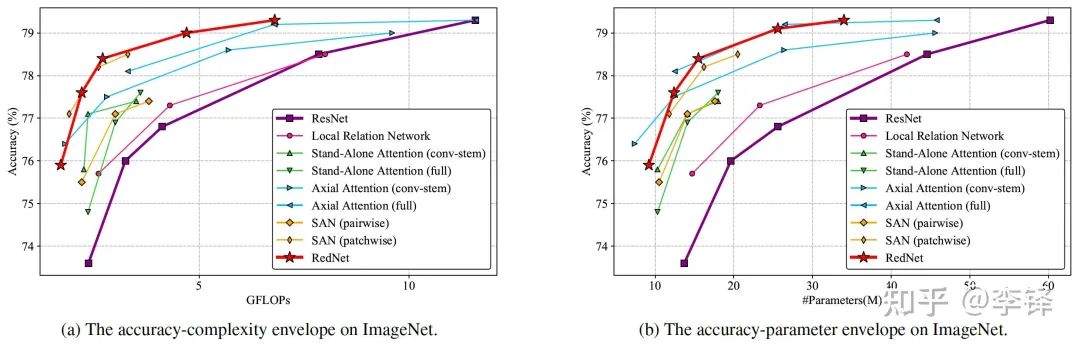
 convolution in the ResNet bottleneck block with involution to obtain a new family of backbone networks called RedNet, which outperforms ResNet and other SOTA models using self-attention as ops in terms of performance and efficiency.
convolution in the ResNet bottleneck block with involution to obtain a new family of backbone networks called RedNet, which outperforms ResNet and other SOTA models using self-attention as ops in terms of performance and efficiency.COCO Object Detection and Instance Segmentation
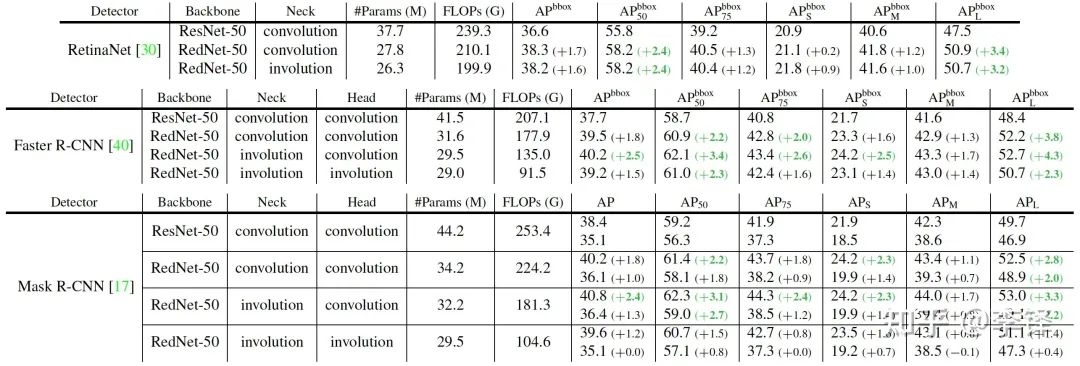
 40% while maintaining similar or improved performance.
40% while maintaining similar or improved performance.Cityscapes Semantic Segmentation

 improved the most (3%-4%), and in the Cityscapes segmentation task, the single-class IoU for large objects (such as walls, trucks, buses, etc.) also saw significant improvements (up to 10% or even more than 20%), which also verifies the significant advantage of involution over convolution in dynamically modeling long-range relationships in space.
improved the most (3%-4%), and in the Cityscapes segmentation task, the single-class IoU for large objects (such as walls, trucks, buses, etc.) also saw significant improvements (up to 10% or even more than 20%), which also verifies the significant advantage of involution over convolution in dynamically modeling long-range relationships in space.-
Further exploration of the kernel generation function space in generalized involution; -
Like deformable convolution, adding offset generation functions to enhance the flexibility of this op space modeling capability; -
Combining NAS technology to search for convolution-involution hybrid structures (original text Section 4.3); -
We discussed that self-attention is just one expression form, but hope that (self-)attention mechanisms can inspire us to design better visual models, similarly, many good works in the detection field have also benefited greatly from the DETR architecture.
Chinese NLP: 2021 Haihua AI Challenge is Open for Registration!
The “2021 Haihua AI Challenge: Chinese Reading Comprehension” jointly organized by the Haihua Research Institute and Tsinghua University’s Institute of Cross-Information Research is ongoing. In the previous finals defense ceremony, Academician Yao Qizhi delivered a heartfelt speech, and all award-winning participants received certificates signed by Mr. Yao.
This year, the competition retains two tracks: the middle school group and the technical group, with a total prize pool of 300,000 yuan. Poetry AI, Smart Chinese, click to read the original text or scan the code to register now!

© THE END
For reprinting, please contact this public account for authorization
Submissions or inquiries: [email protected]