
1. Brief Introduction
Self-Attention: Allows each element in the input sequence to focus on and weight other elements in the entire sequence, generating a new output representation that does not rely on external information or historical states.
-
Self-Attention enables interaction among all elements in the input sequence.
-
It computes attention weights for each element with respect to all other elements and applies these weights to the corresponding element’s representation to obtain a weighted output representation.
-
Self-Attention does not depend on external information or previous hidden states, relying entirely on the input sequence itself.
Self-Attention
Multi-Head Attention: By running multiple Self-Attention layers in parallel and integrating their results, it can simultaneously capture information from different subspaces of the input sequence, thereby enhancing the model’s expressive power.
-
Multi-Head Attention is essentially multiple parallel Self-Attention layers, where each “head” independently learns different attention weights.
-
The outputs of these “heads” are subsequently merged (usually concatenated and then passed through a linear layer) to produce the final output representation.
-
In this way, Multi-Head Attention can simultaneously focus on information from different subspaces of the input sequence.
Multi-Head Attention
2. Workflow
Self-Attention: By generating query, key, and value vectors, it calculates and normalizes attention scores, ultimately performing a weighted sum on the value vectors to obtain a weighted representation for each position in the input sequence.
Self-Attention Workflow
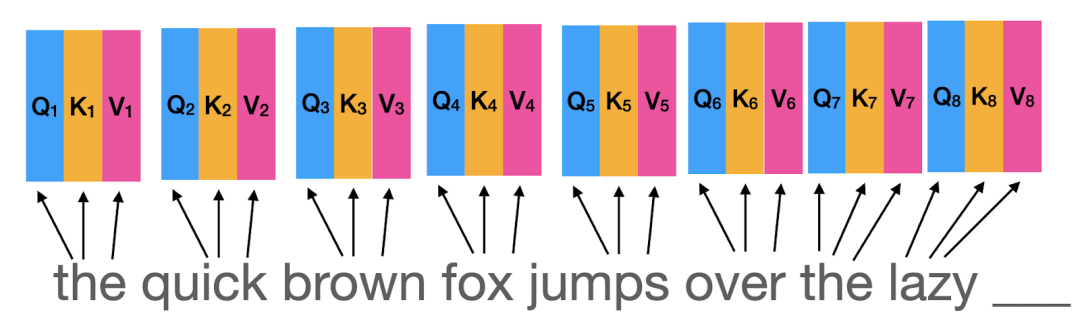
Step 1: Generate Query, Key, and Value
-
Input: Receives an input sequence composed of embedding vectors, which can be word embeddings combined with positional embeddings.
-
Processing: Uses three independent linear layers (or dense layers) to generate query (Q), key (K), and value (V) vectors for each input vector.
-
Query vectors represent the current focus or the information to be retrieved.
-
Key vectors determine the information that matches the query vectors.
-
Value vectors contain the actual information associated with the corresponding key vectors.
Step 1: Generate Query, Key, and Value
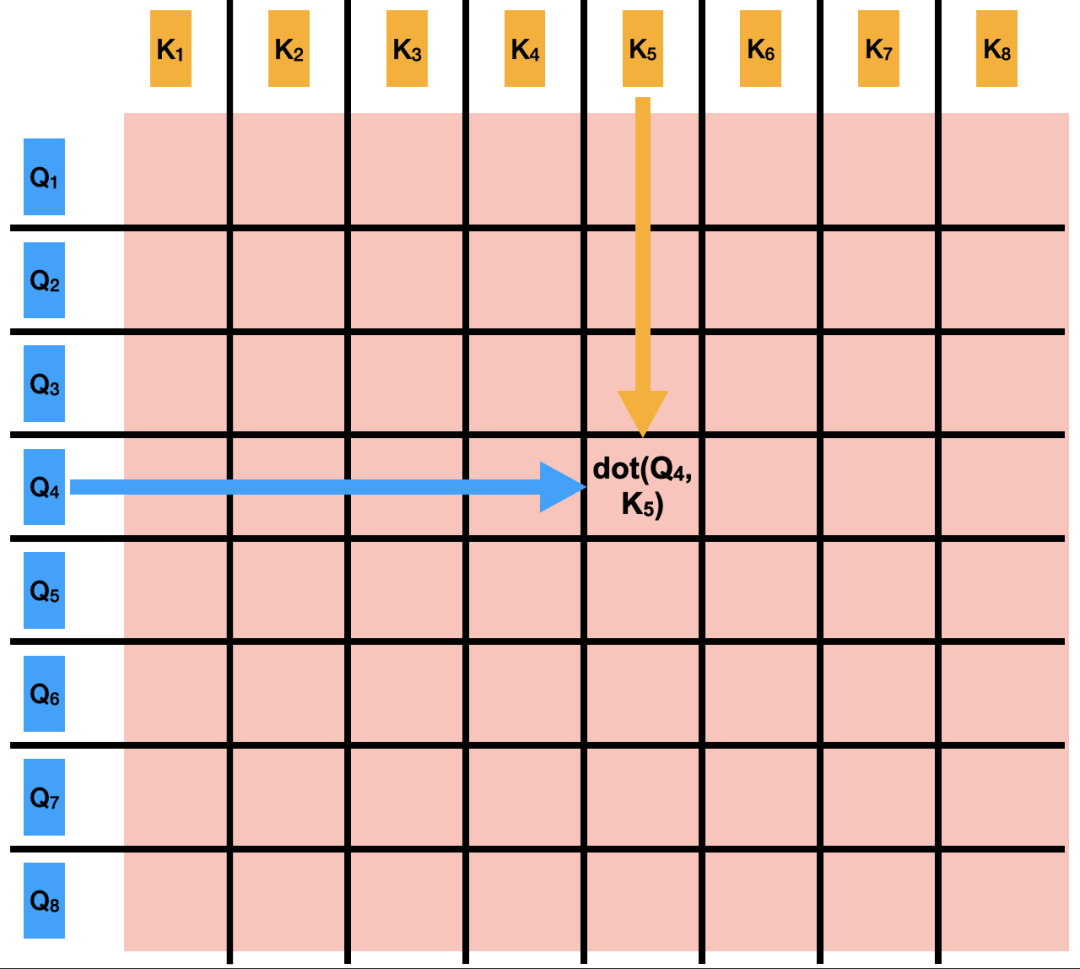
Step 2: Calculate Attention Matrix
-
Processing: Calculates the dot product between the query vectors and all key vectors, forming an attention score matrix.
-
Each element in this matrix represents a correlation score between a query vector and its corresponding key vector.
-
Due to the dot product operation, the scores can be very large or very small.
Step 2: Calculate Attention Matrix
Step 3: Normalize Attention Scores
-
Processing: Applies the softmax function to normalize the attention score matrix.
-
After normalization, the sum of each row equals 1, and each score represents the weight of the corresponding position’s information.
-
Before applying softmax, it is common to divide by a scaling factor (like the square root of the dimension of the query or key vectors) to stabilize gradients.
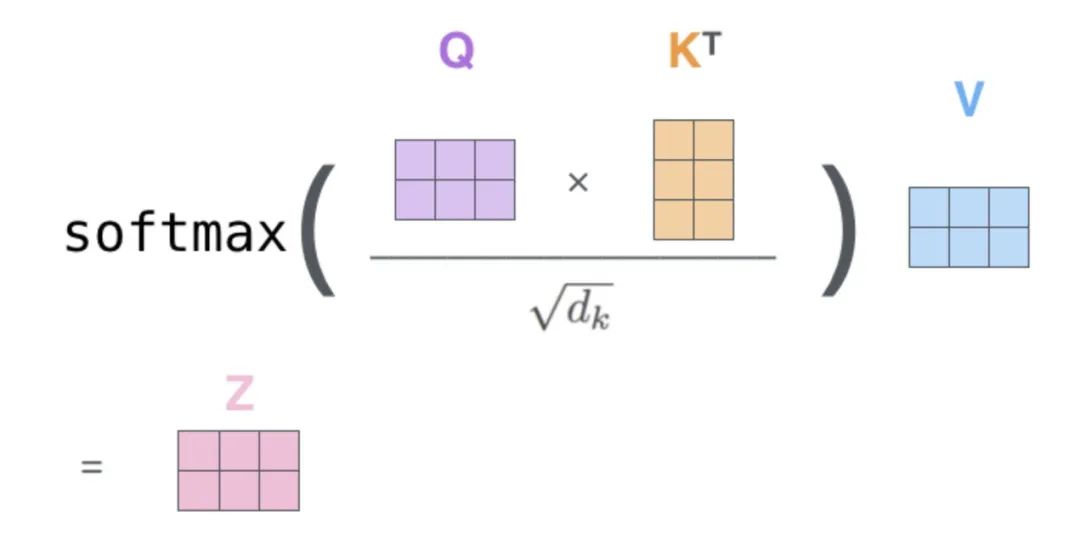
Step 3: Normalize Attention Scores
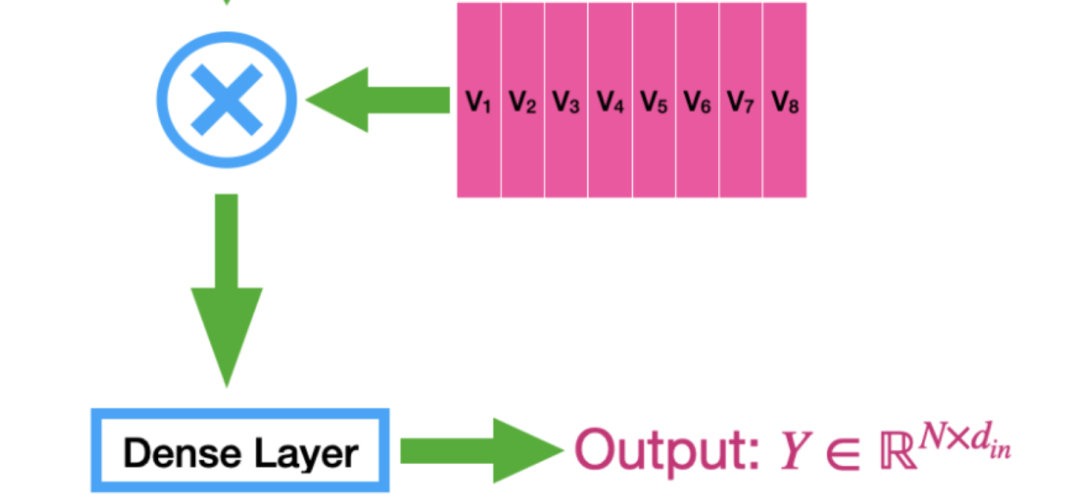
Step 4: Weighted Sum and Output
-
Processing: Uses the normalized attention weights to perform a weighted sum on the value vectors.
-
The result of the weighted sum is the output of the self-attention mechanism, which contains the weighted information from all positions in the input sequence.
-
Each element of the output vector is a weighted sum of the input vectors, with weights determined by the attention mechanism.
Step 4: Weighted Sum and Output
Multi-Head Attention: By splitting the input query, key, and value matrices into multiple heads, independently calculating attention in each head, and concatenating and linearly transforming these outputs, it captures and integrates various interaction information simultaneously in different representation subspaces, enhancing the model’s expressive power.
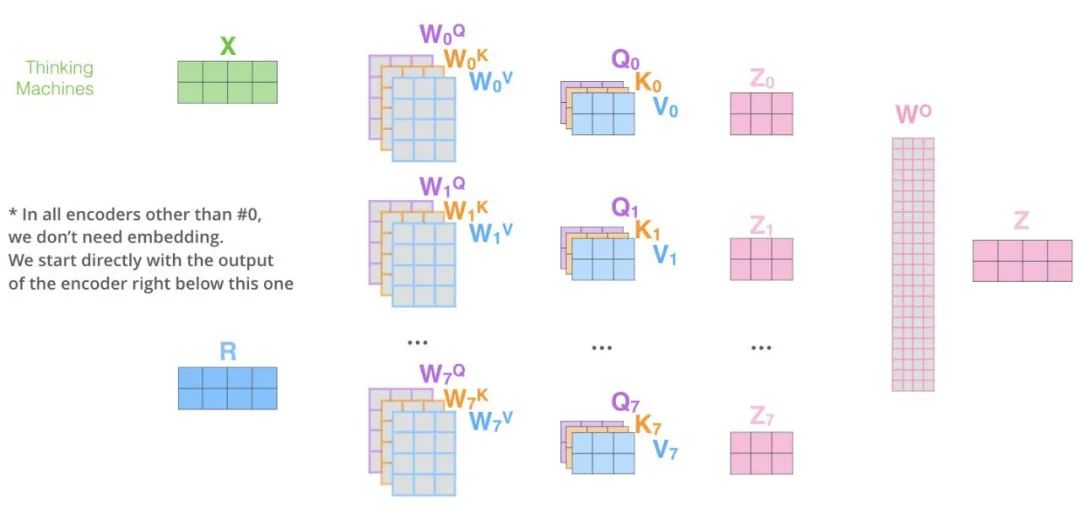
Multi-Head Attention Workflow
-
Initialization: First, initialize necessary parameters, including weights for the query, key, and value matrices, as well as the number of heads in the multi-head attention. These weights will be used for subsequent linear transformations.
-
Linear Transformation: Perform linear transformations on the input query, key, and value matrices. These transformations are achieved by multiplying with the corresponding weight matrices. The transformed matrices will be used for subsequent multi-head attention calculations.
-
Splitting and Projection: Split the linearly transformed query, key, and value matrices into multiple heads. Each head has its own query, key, and value matrices. Then, independently calculate attention scores in each head.
-
Scaling and Softmax: Scale the attention scores for each head to avoid gradient vanishing or exploding issues. Then, apply the Softmax function to normalize the attention scores, ensuring that the sum of weights for each position equals 1.
-
Weighted Sum: Perform a weighted sum on the value matrix using the normalized attention weights to obtain the output matrix for each head.
-
Concatenation and Linear Transformation: Concatenate the output matrices from all heads to form a large output matrix. Then, perform a linear transformation on this output matrix to obtain the final output.
3. Comparison of the Two
Core Differences:Self-Attention focuses on the importance of each position in the sequence relative to all other positions, while Multi-Head Attention allows the model to simultaneously capture and integrate contextual information from different aspects by calculating attention in multiple subspaces in parallel, enhancing its ability to model the intrinsic structure of complex data.
-
Self-Attention: The core of the self-attention mechanism is to learn a weight distribution for each position in the input sequence, allowing the model to know which positions’ information is more important when processing the current position. Self-Attention specifically refers to the attention calculation performed within the sequence, where each position interacts with all other positions.
-
Multi-Head Attention: To allow the model to simultaneously focus on information from different positions, the Transformer introduces Multi-Head Attention. Its basic idea is to split the representation of the input sequence into multiple subspaces (heads), then independently compute attention weights within each subspace, and finally concatenate the results from each subspace. The benefit of this approach is that the model can capture different contextual information across different representation subspaces.
Case Comparison: In the example “I love AI”, Self-Attention calculates the correlation weights between each word and other words, while Multi-Head Attention splits the embedding space and calculates these weights in multiple subspaces in parallel, allowing the model to capture richer contextual information.
Self-Attention (Self-Attention Mechanism):
-
Input: The sequence “I love AI” is passed through an embedding layer, where each word (e.g., “I”) is mapped to a 512-dimensional vector.
-
Attention Weight Calculation:
-
For the word “I”, the Self-Attention mechanism calculates the attention weights with respect to all other words in the sequence (“love”, “A”, “I”).
-
This means that for the 512-dimensional embedding vector of “I”, we calculate its attention scores with the embedding vectors of “love”, “A”, and “I”.
Output: Based on the calculated attention weights, the input sequence’s word vectors are summed with weights to obtain the output vector processed by the self-attention mechanism.
Multi-Head Attention:
-
Subspace Splitting:
-
The original 512-dimensional embedding space is split into multiple subspaces (e.g., 8 heads, so each subspace is 64-dimensional).
-
For the word “I”, its 512-dimensional embedding vector is correspondingly split into 8 sub-vectors of 64 dimensions each.
Independent Attention Weight Calculation:
-
In each 64-dimensional subspace, the attention weights between “I” and “love”, “A”, and “I” are calculated independently.
-
This means that in each subspace, there is a separate set of attention scores for calculating the weighted sum.
Result Concatenation and Transformation:
-
The attention outputs calculated from each subspace are concatenated to form a larger vector (in this example, 8 concatenated 64-dimensional vectors form a 512-dimensional vector).
-
Through a linear layer, this concatenated vector is transformed back to the original 512-dimensional space, obtaining the final output of Multi-Head Attention.