Abstract: Vision segmentation is a core task in the field of computer vision, aiming to classify pixels in images or video frames to partition them into different regions. Thanks to the rapid development of vision segmentation technology, it plays a critical role in various application areas such as autonomous driving, aerial remote sensing, and video scene understanding. In recent years, vision segmentation technology based on Transformer has attracted significant attention due to its capability of modeling long-range dependencies. With the continuous optimization and iteration of the Transformer model architecture, there is an urgent need to comprehensively understand and recognize the existing advancements and development trends of Transformer in the field of vision segmentation. By identifying the shortcomings and challenges in existing research, we aim to explore the core theories of Transformer in greater depth. This article organizes, reviews, analyzes, and discusses the recent technological advancements in vision segmentation based on Transformer from the perspectives of images and videos. Not only does it summarize the theoretical framework of Transformer, but it also provides some application examples and research hotspots, leading to conclusions and outlooks.
Abstract: Vision segmentation is a core task in the field of computer vision, aiming to classify pixels in images or video frames to partition them into different regions. Thanks to the rapid development of vision segmentation technology, it plays a critical role in various application areas such as autonomous driving, aerial remote sensing, and video scene understanding. In recent years, vision segmentation technology based on Transformer has attracted significant attention due to its capability of modeling long-range dependencies. With the continuous optimization and iteration of the Transformer model architecture, there is an urgent need to comprehensively understand and recognize the existing advancements and development trends of Transformer in the field of vision segmentation. By identifying the shortcomings and challenges in existing research, we aim to explore the core theories of Transformer in greater depth. This article organizes, reviews, analyzes, and discusses the recent technological advancements in vision segmentation based on Transformer from the perspectives of images and videos. Not only does it summarize the theoretical framework of Transformer, but it also provides some application examples and research hotspots, leading to conclusions and outlooks.

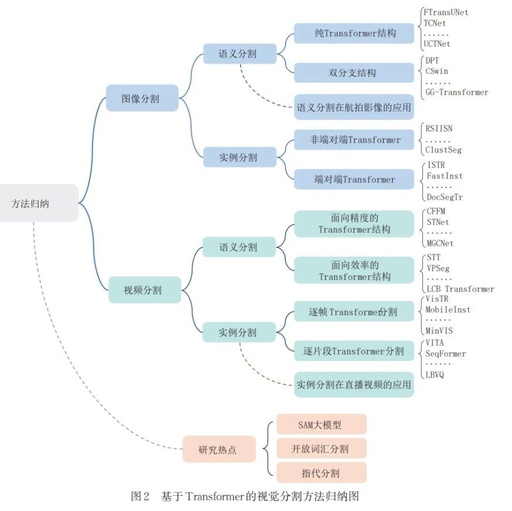
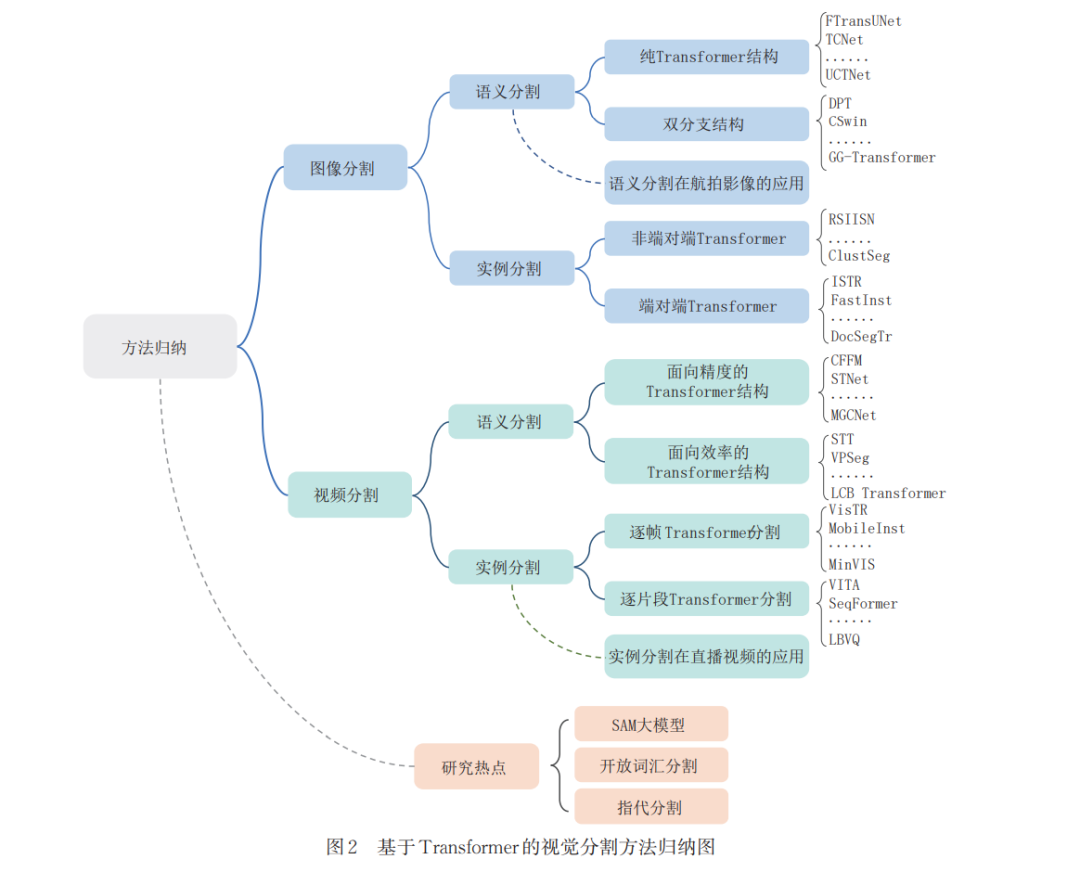
Subsequently, in light of the widespread attention on the SAM large model, open vocabulary segmentation, and referential segmentation in the field of vision segmentation, this article traces and reviews these hotspot issues and methods, hoping to spark new ideas and inspirations in vision segmentation. Finally, although vision segmentation technology based on Transformer has received extensive attention, the scientific problems that exist are gradually becoming prominent, limiting further improvements in model performance and efficiency. This article summarizes the challenges that still need to be addressed when conducting image/video semantic/instance segmentation using Transformer, and provides insights on potential future development directions.
Keywords: Vision Segmentation; Transformer; Semantic Segmentation; Instance Segmentation; Self-Attention Mechanism
For convenient access to specialized knowledge, visit the following website or click “Read the Original” at the bottom
https://www.zhuanzhi.ai/vip/e187ff396d981c6dda4c0e8dc46861b8

Click “Read the Original” to view and download this article.