Click on the above “Beginner Learning Visuals” to select “Star” or “Pin”

Author: Wang Bo Kings, Sophia
Overview of the Content of This Article: Wang Bo Kings’ Recent Learning Notes on Transformer
-
Background Knowledge
-
High-Level Understanding
-
Understanding Tensor Through Examples
-
Encoding
-
High-Level Understanding of Self-Attention
-
Details of Self-Attention
-
Self-Attention Matrix Multiplication
-
Multi-Headed Enhancement
-
Overall Process
-
Using Positional Encoding
-
Encoding Rules
-
Residual Neural Network Residuals
-
Decoder
-
Linear and Softmax Layers
-
Review Training Process
-
Loss Function
-
Target Model Outputs
-
Trained Model Outputs
1. Background Knowledge
-
Transformer was proposed in Google’s paper “Attention is All You Need”
-
Google open-sourced a third-party library based on TensorFlow called Tensor2Tensor
-
Harvard University deeply interpreted this paper using PyTorch: http://nlp.seas.harvard.edu/2018/04/03/attention.html
2. High-Level Understanding
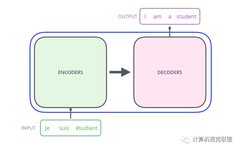
First, understand the Transformer as a black box; the function of the black box is translation. You input a statement, and it performs a translation operation on your input.

The black box can be expanded, consisting of two parts: Encoders and Decoders
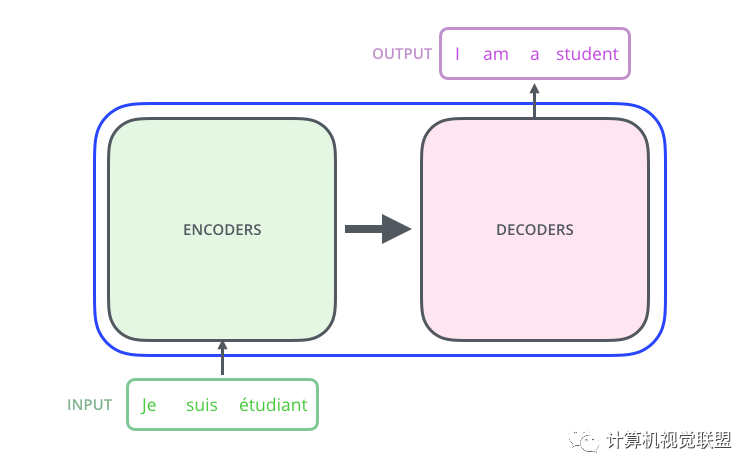
Further refinement of the black box reveals that it consists of 6 Encoders and 6 Decoders
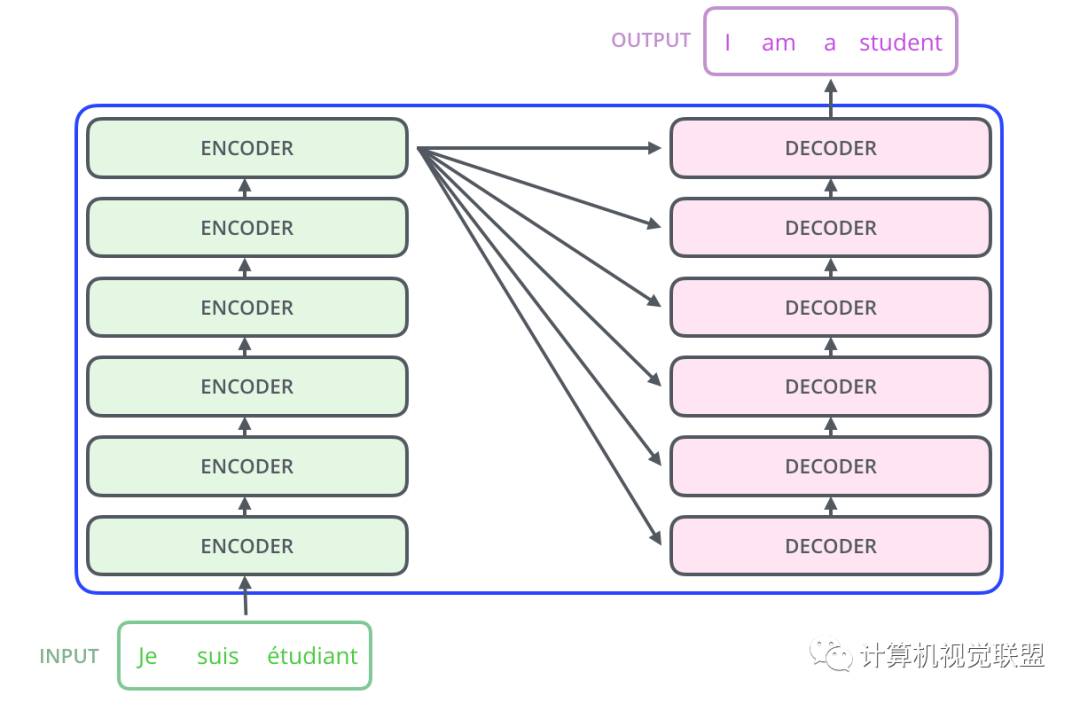
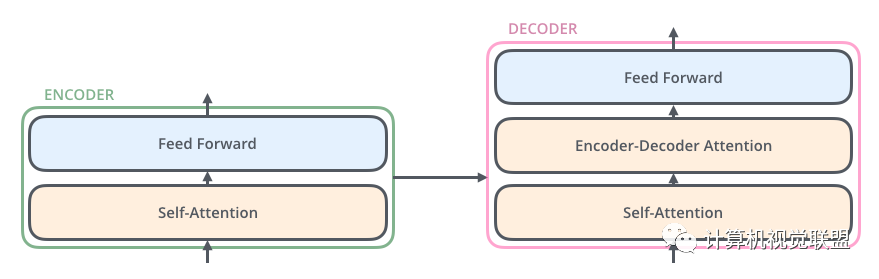
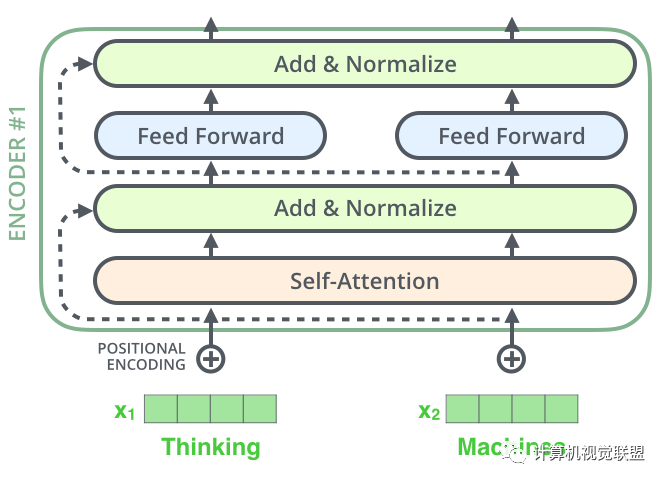
Each Encoder has the same structure, but the weights are not shared. Each layer consists of two parts: self-supervision + fully connected
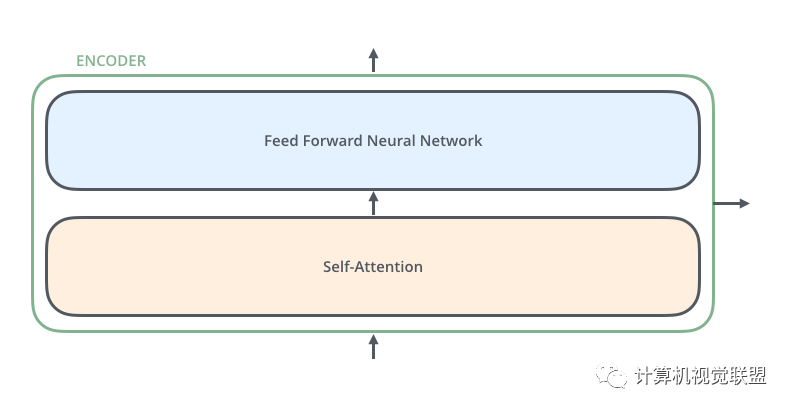
The input of Self-attention is fed into a fully connected feed-forward neural network. The parameters of each encoder’s feed-forward neural network are the same, but their functions are independent.
The Decoder part also has the same hierarchical structure but includes an Encoder-Decoder-Attention layer in the middle to help focus on the corresponding statement (similar to the Seq2Seq model).
3. Understanding Tensor Through Examples
First, perform an embedding to transform the input words into vectors
For specifics, see this blog: https://blog.csdn.net/qq_41664845/article/details/84313419

The size of the list and the dimension of the word vector can both be set as hyperparameters, generally set to the length of the longest sentence in the training dataset. This example encodes each word as a 512-dimensional vector.
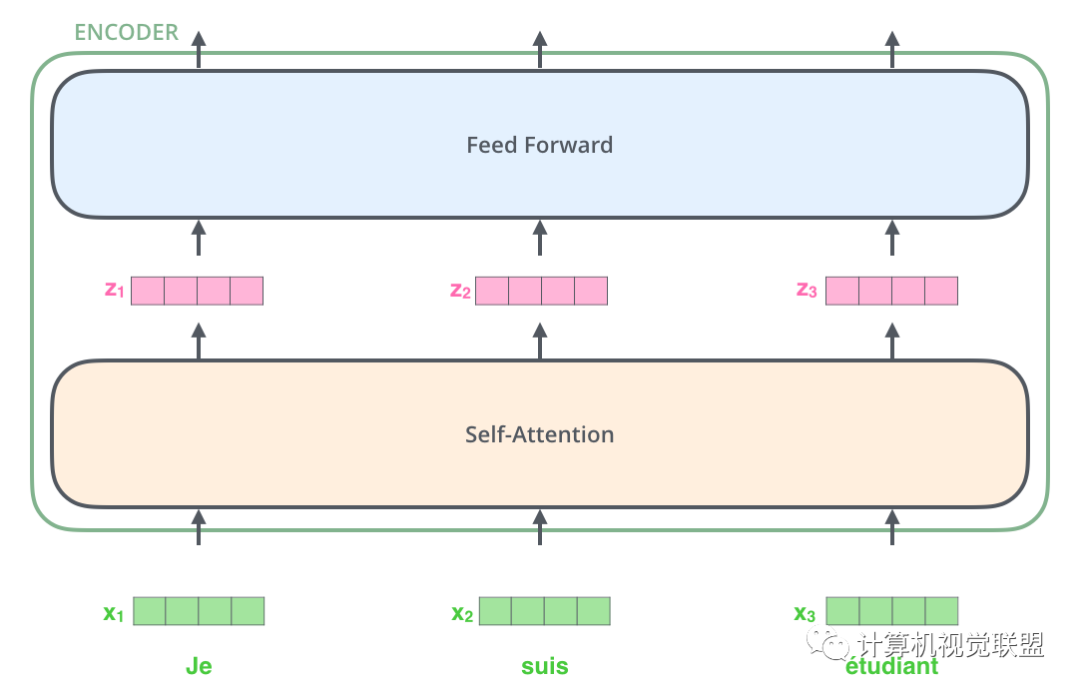
It can be observed that after inputting x1, x2, and x3 through self-attention, z1, z2, and z3 are obtained, which is important to note: z1, z2, and z3 are actually produced collaboratively by x1, x2, and x3.
Encoding
Each Encoder receives a 512-dimensional vector x as input, then passes through Self-Attention, producing an equal 512-dimensional z, which is then passed through a fully connected neural network, resulting in an output r that is also 512-dimensional, then passed to the next encoder.
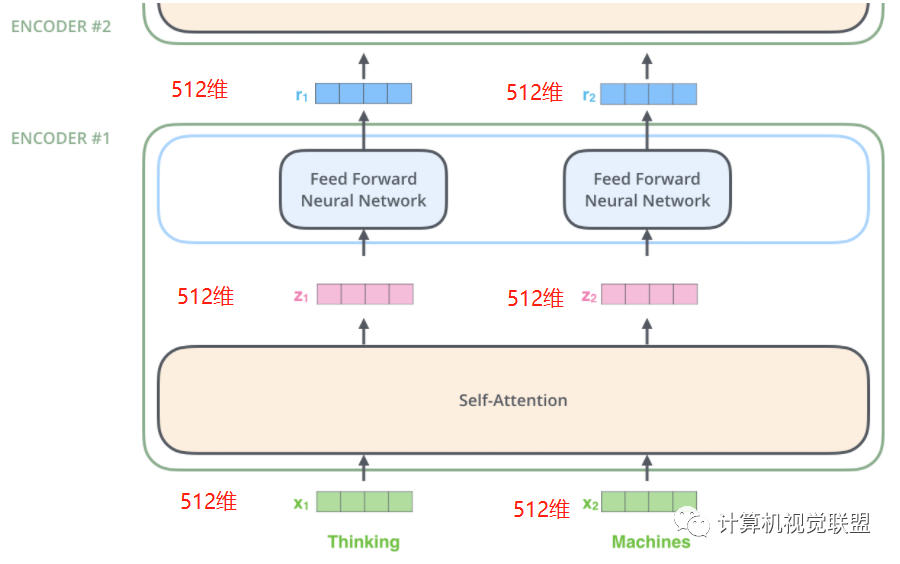
Note that the structure of the feed-forward neural network is actually consistent.
4. High-Level Understanding of Self-Attention
Suppose the input is:
”The animal didn't cross the street because it was too tired”
How does the word “it” relate to “animal” in this sentence?

Details of Self-Attention
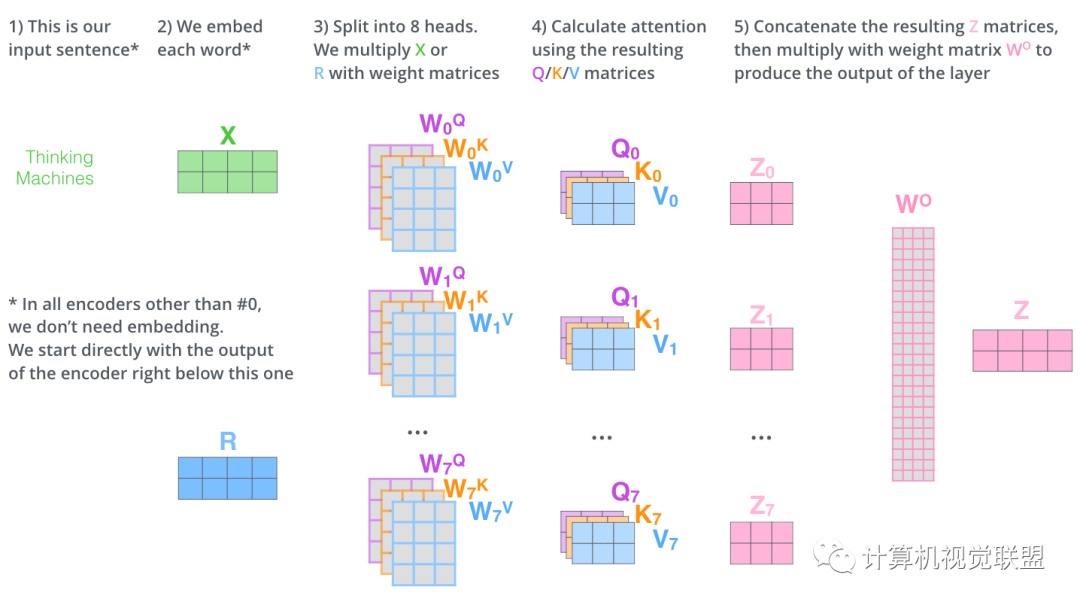
Step 1: Q, K, V Calculation
For each word, we create a Query vector, a Key vector, and a Value vector. These vectors are produced by multiplying the word embeddings by three training matrices created during our training process.
The input vector dimension is 512, and the new vector dimension is 64. The new vector dimension is determined based on practical considerations.
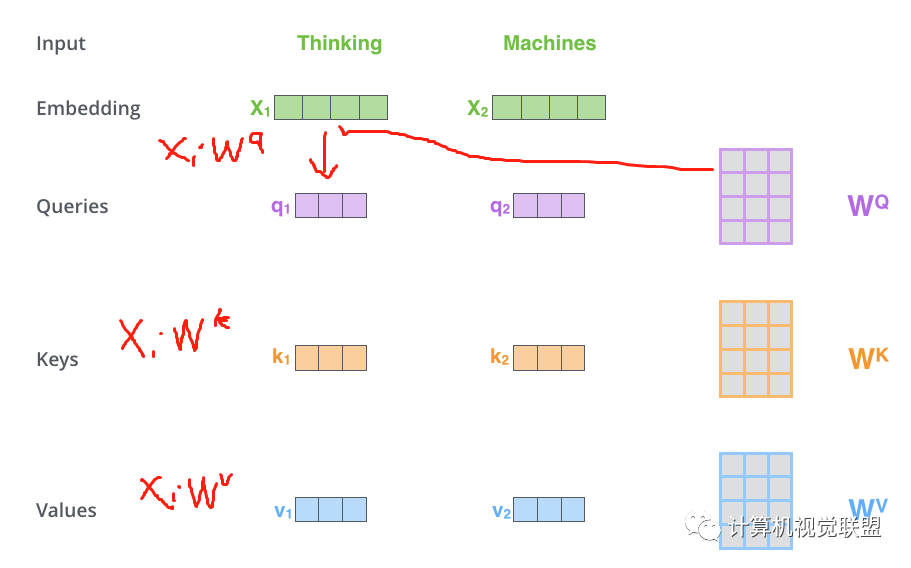
Multiplying x1 by the WQ weight matrix produces q1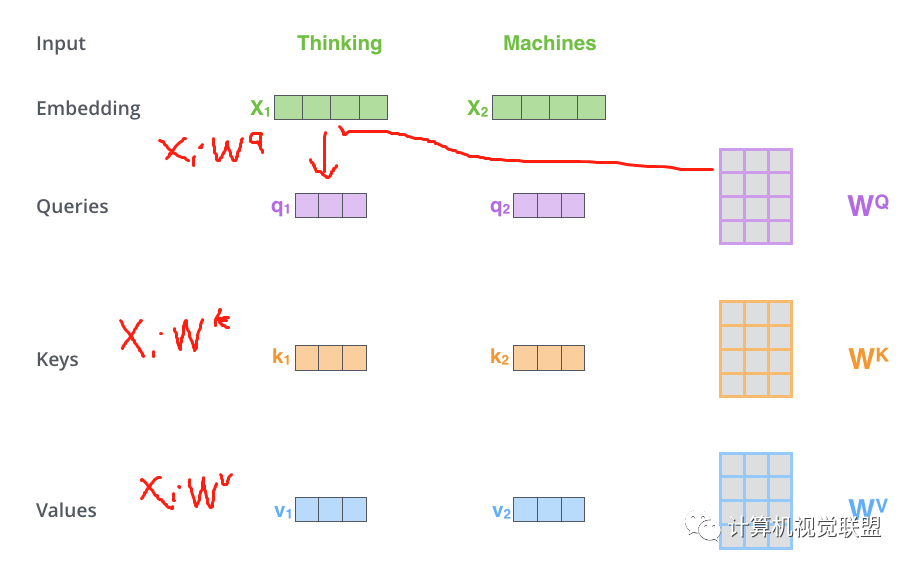
Step 2: Dot Product
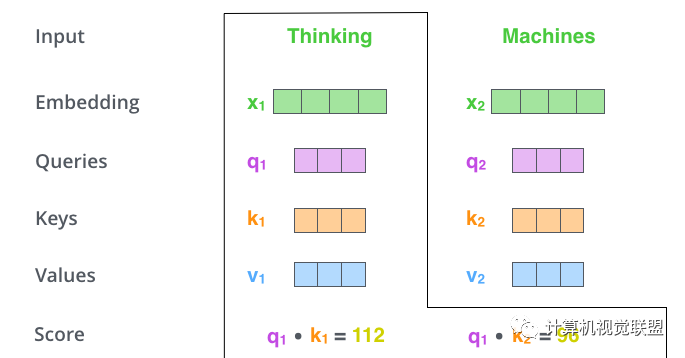
q1 is multiplied by k1, and q1 is multiplied by k2. Note!!! It is q1 and k2! Look carefully, not q2
Steps 3 and 4:
The result of the dot product is divided by sqrt(dk). In this case, the vector is 64, and the square root is 8, so it is divided by 8.
Then, a Softmax operation is performed.
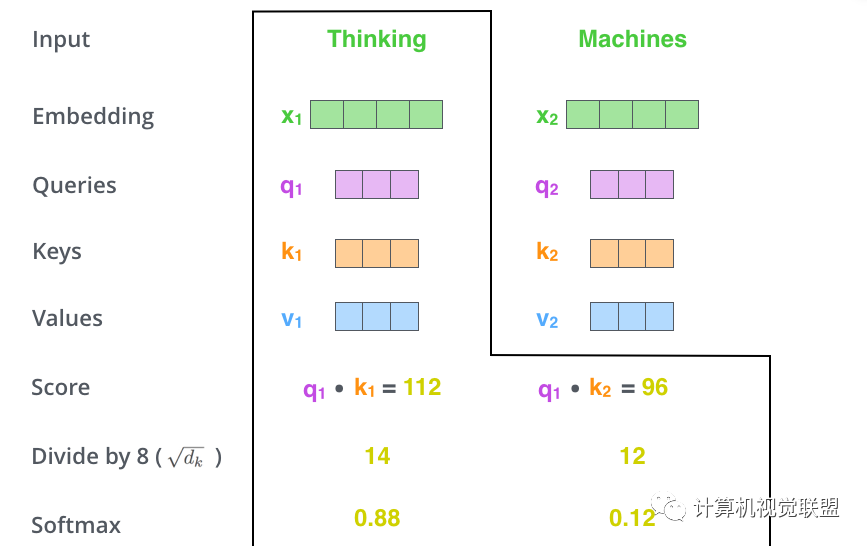
The scores obtained from the Softmax operation represent how much the current word is represented at each unit position in the sentence.
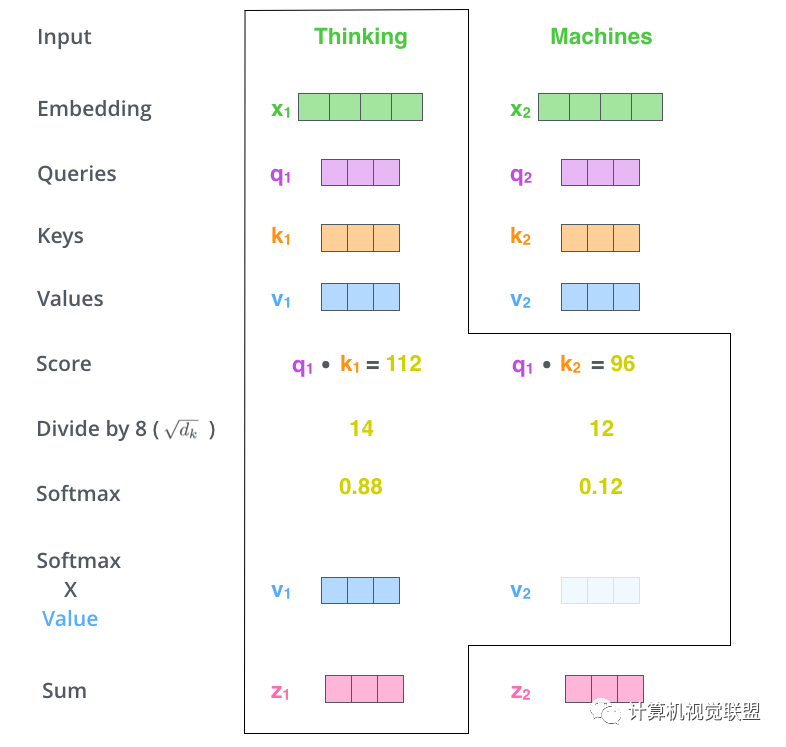
Steps 5 and 6:
The Values are multiplied by the Softmax values to obtain v1, v2, maintaining the attention on the current word while reducing it for unrelated words.
The weighted sum of the vectors yields z1.
Self-Attention Matrix Multiplication
Step one is to calculate the Query, Key, and Value matrices. X is the matrix transformed from x1 and x2.
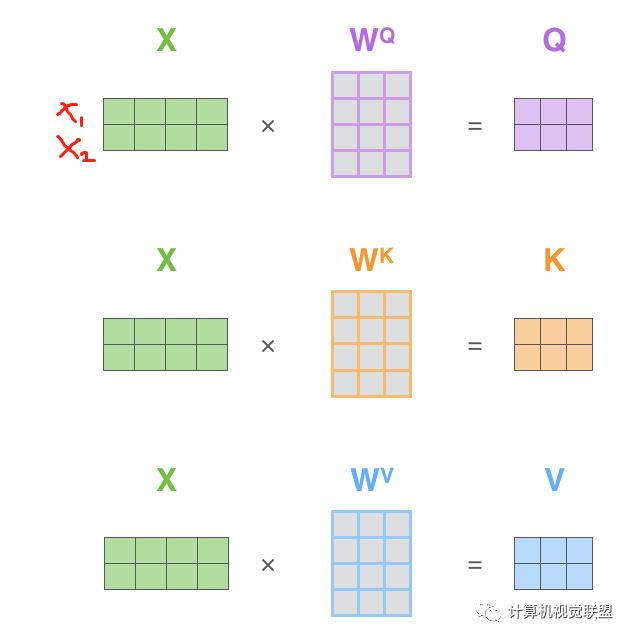
Then, the subsequent Z is obtained through operations.
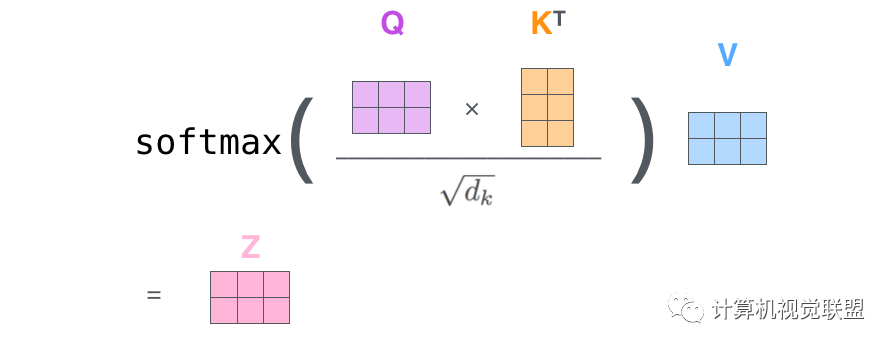
Multi-Headed Enhancement
-
Expands the model’s ability to focus on different positions
-
Provides projections into different subspaces
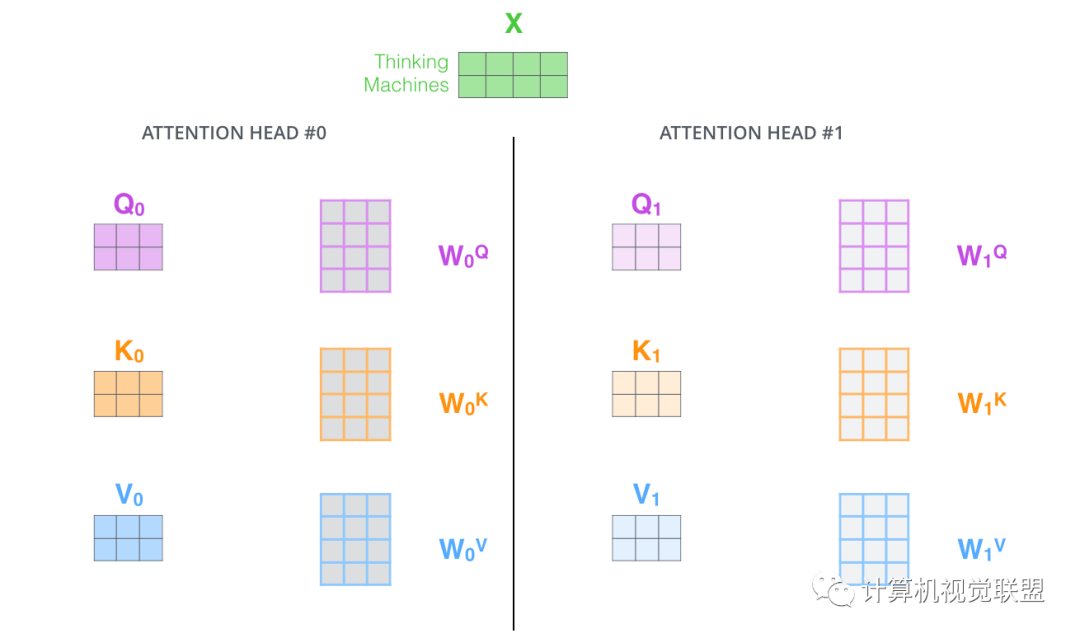
Through multi-headed attention, we independently maintain a set of Q/K/V weight matrices for each “header”.
Using 8 time points to calculate the weight matrices yields 8 different matrices z.
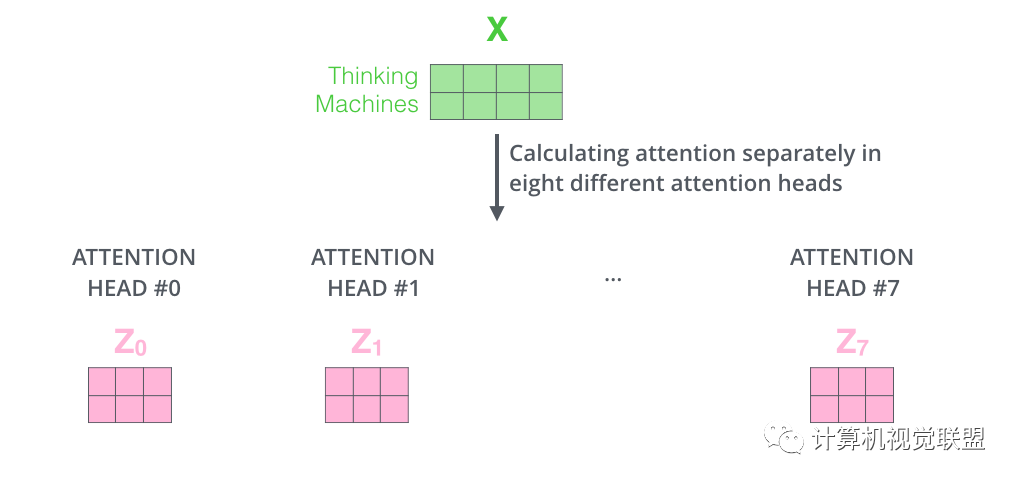
The 8 matrices are concatenated together and then multiplied by the matrix Wo.
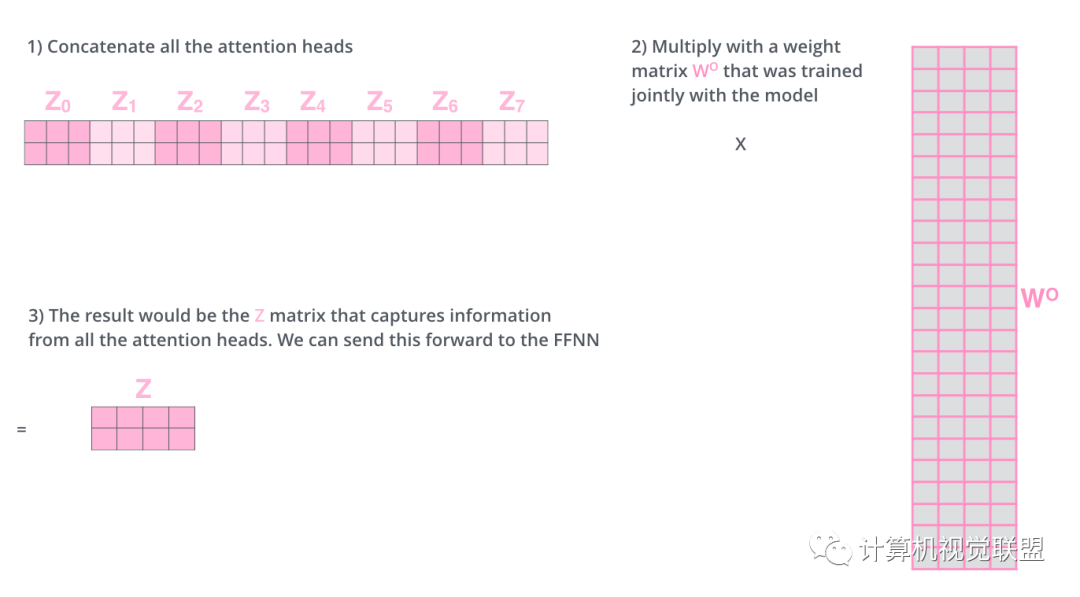
Overall Process
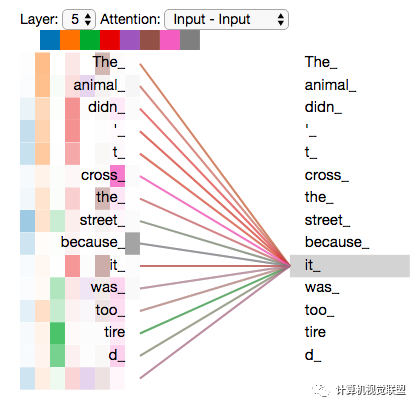
We randomly examine two different attention headers (8 columns, taking columns 2 and 3 from the image below) to see what differences in focus there are.

At these two timestamps, it is found that “it” focuses most on two: “animal” and “tired”.
Adding all the attention to the image may not make it easy to understand the meaning.
5. Using Positional Encoding
The input sequence must also consider the order of the words.
The transformer embeds a new positional vector for each input word.
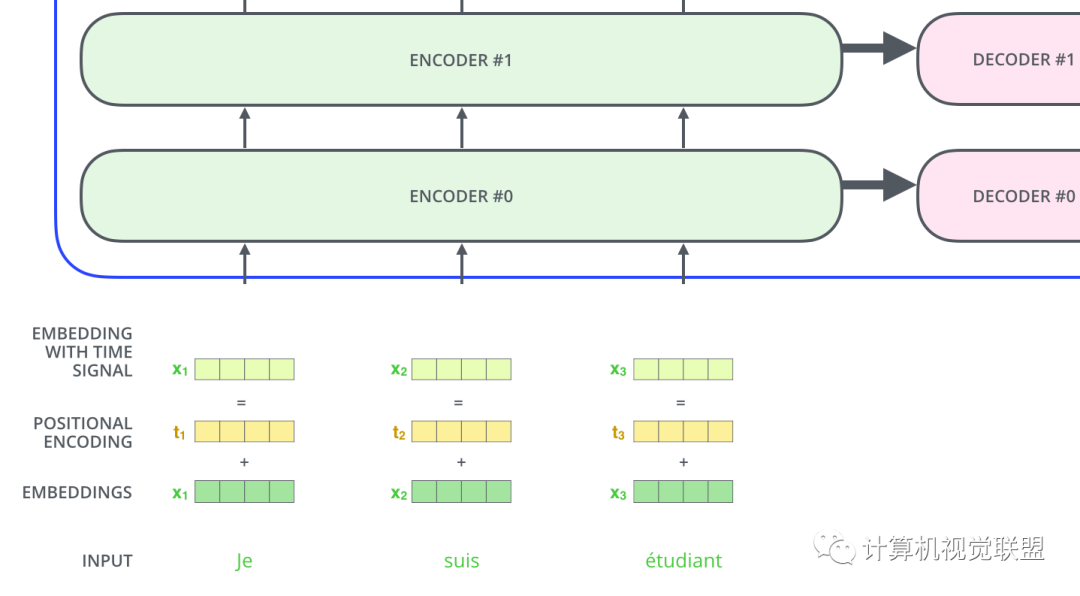
To let the model know the order of the words, the positional encoding vector information is generated directly through rules.
For example, if the embedding dimension is 4, the actual encoding effect is as follows:
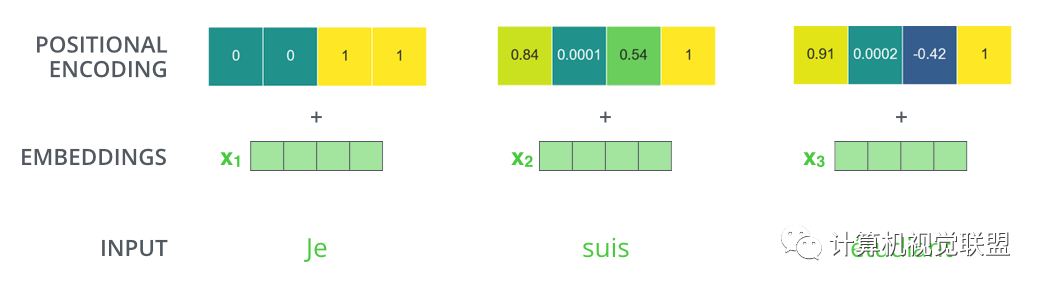
Encoding Rules
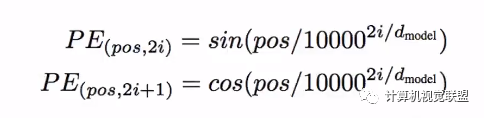

For example, if there are 20 words, each word is encoded as a 512-dimensional vector.
In total, there are 20 rows, and each row represents a word vector containing 512 values, each value between -1 and 1. Visualization shows:
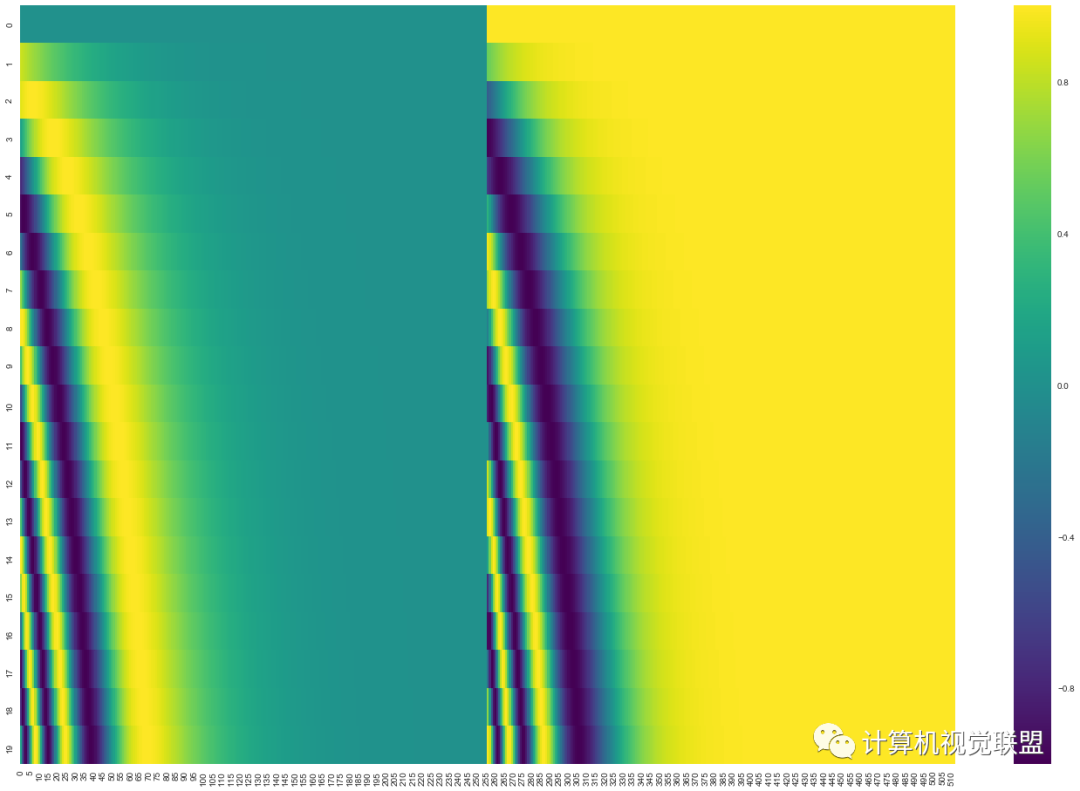
The center position is divided into two, with half generated by sine and the other half by cosine.
If there are slight changes in the above Transformer to Transformer, it is shown as follows:

import numpy as np
import matplotlib.pyplot as plt
# https://github.com/jalammar/jalammar.github.io/blob/master/notebookes/transformer/transformer_positional_encoding_graph.ipynb
# Code from https://www.tensorflow.org/tutorials/text/transformer
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return pos * angle_rates
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model) # apply sin to even indices in the array; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2]) # apply cos to odd indices in the array; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return pos_encoding
tokens = 10
dimensions = 64
pos_encoding = positional_encoding(tokens, dimensions)
print (pos_encoding.shape)
plt.figure(figsize=(12,8))
plt.pcolormesh(pos_encoding[0], cmap='viridis')
plt.xlabel('Embedding Dimensions')
plt.xlim((0, dimensions))
plt.ylim((tokens,0))
plt.ylabel('Token Position')
plt.colorbar()
plt.show()6. Residual Neural Network Residuals
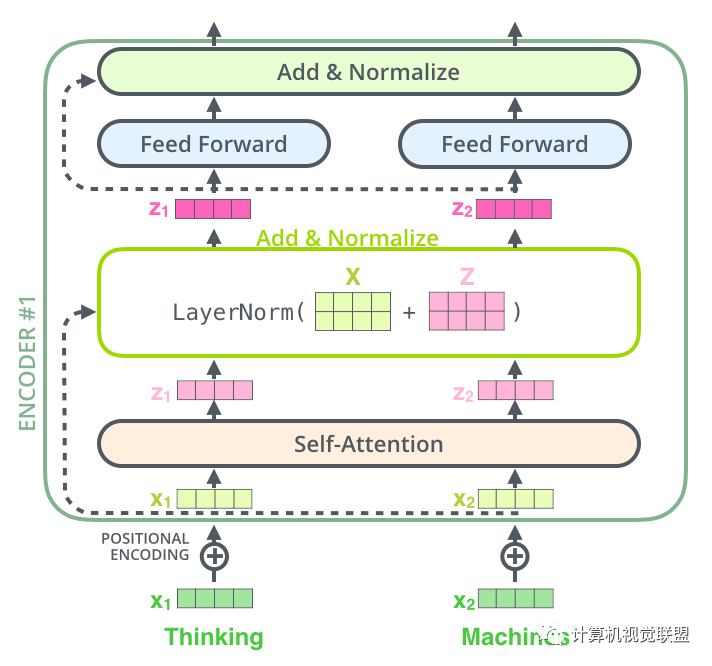
Layer normalization steps
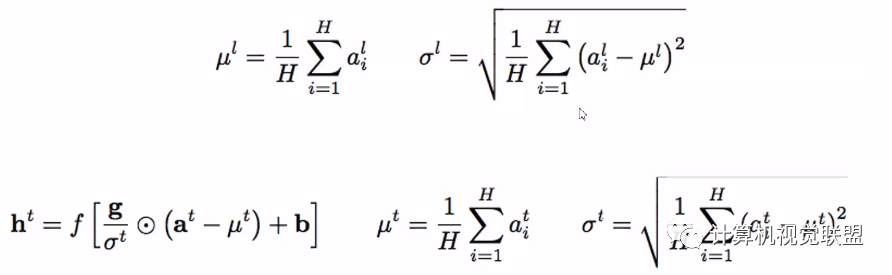
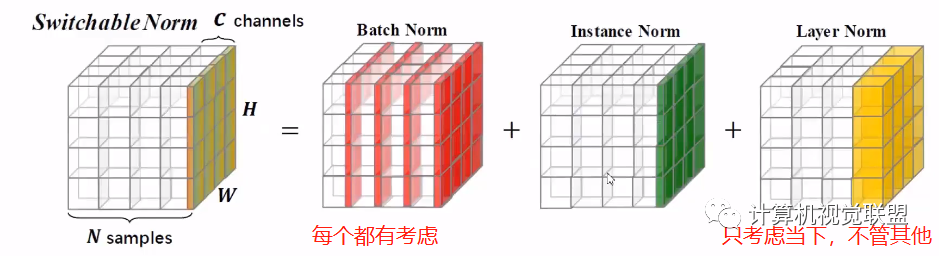
Further visualization
The Decoder part is the same as this. We stacked 2 Encoders and 2 Decoders
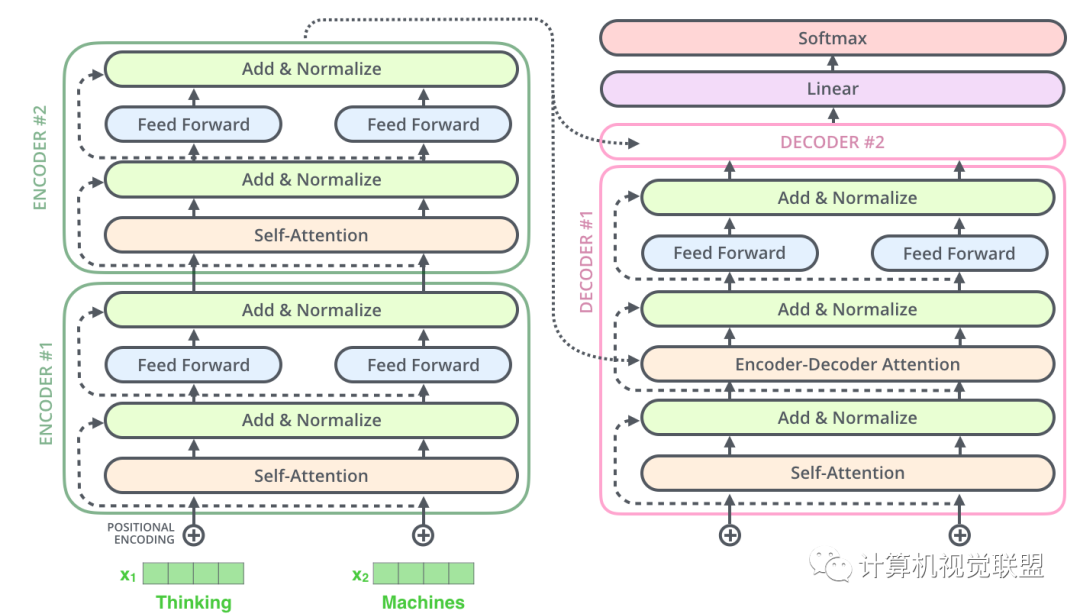
7. Decoder
The Encoder transforms it into a collection of attention (K, V)
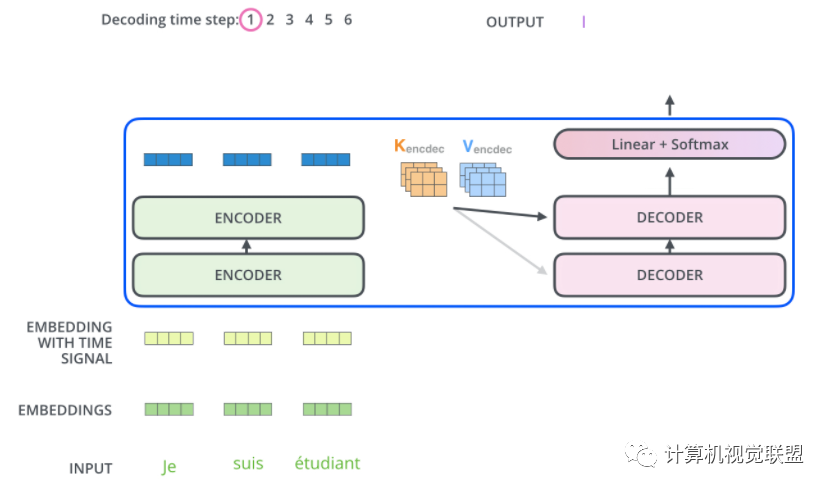
8. Linear and Softmax Layers
The linear layer is a simple fully connected neural network that projects the vector produced by the Decoder into a larger vector, becoming the logit vector.
Assuming the experimental model’s vocabulary consists of 10,000 English words, the logits vector represents 10,000 small grids, each representing a word.
After the linear layer is a Softmax layer, which converts the scores into probabilities, selecting the highest probability as the index, and then finding the word through the index as output.
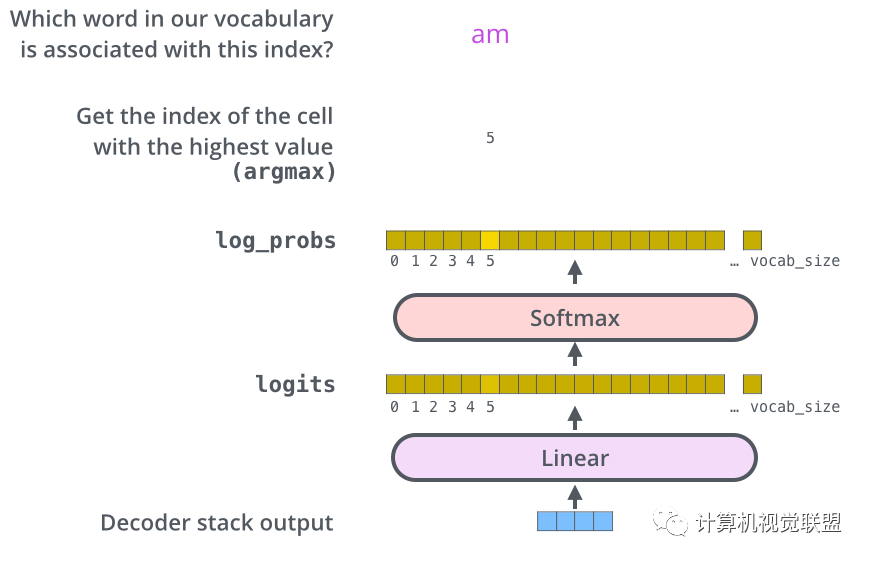
9. Review Training Process
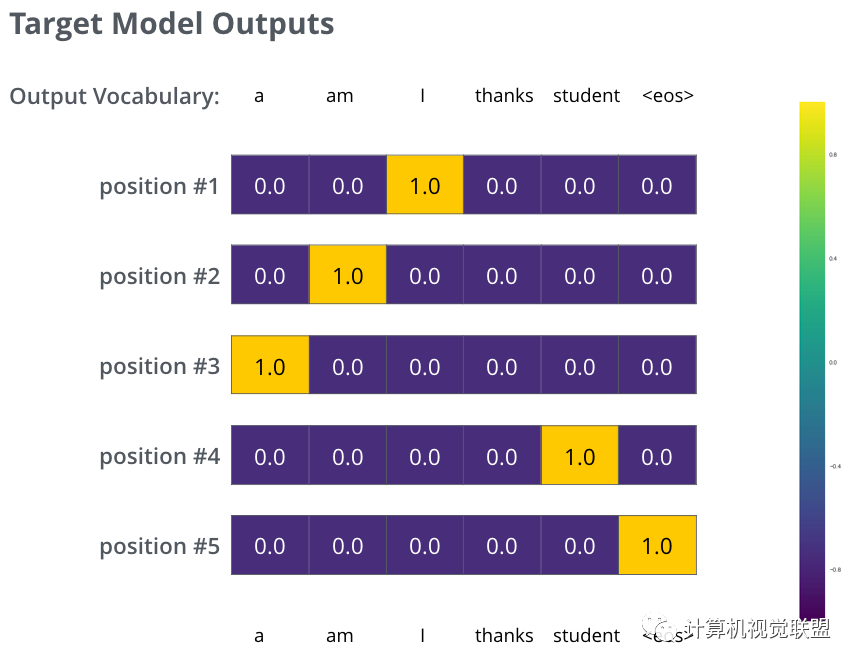
Assuming the output vocabulary only includes “a”, “am”, “I”, “thanks”, “student”, “<eos> end symbol”
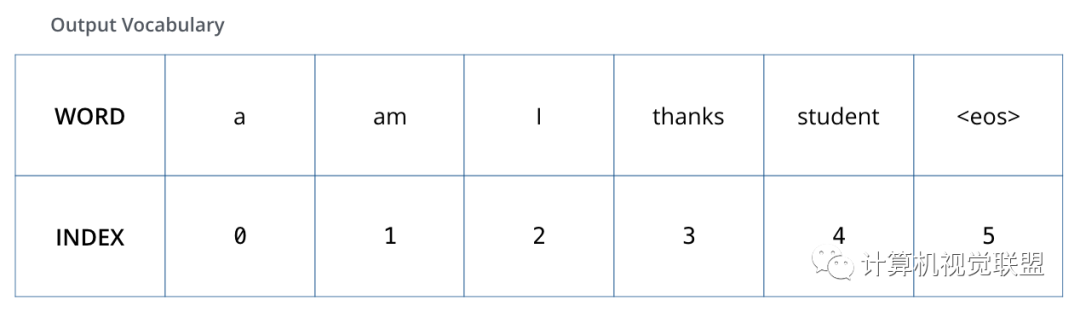
Once the output vocabulary is determined, the same-width vector can be used to represent the words in the vocabulary, known as one-hot encoding.
For example, in the sentence, the one-hot encoding for “am” is:
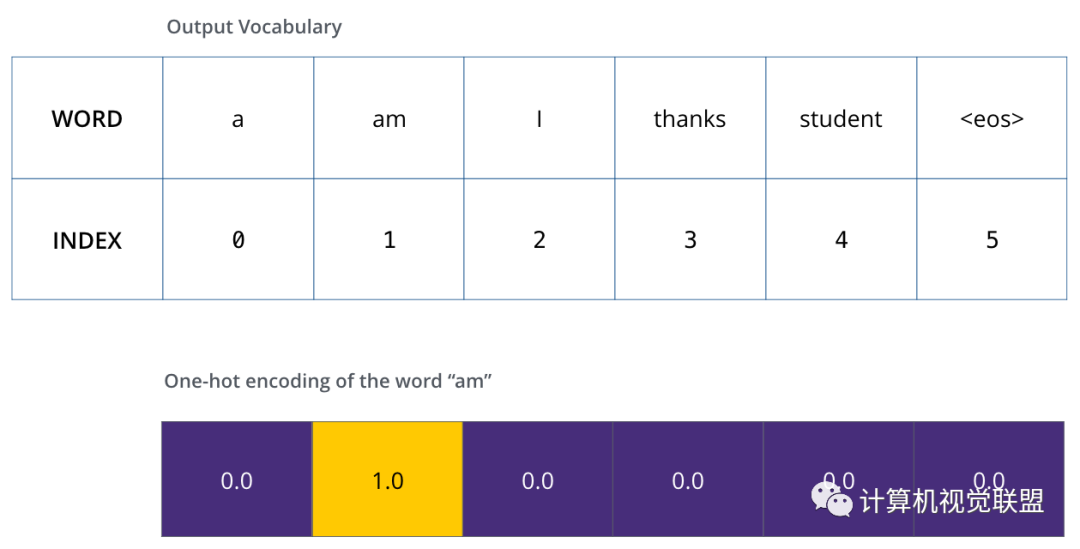
Loss Function
The model’s parameter weights are randomly initialized.
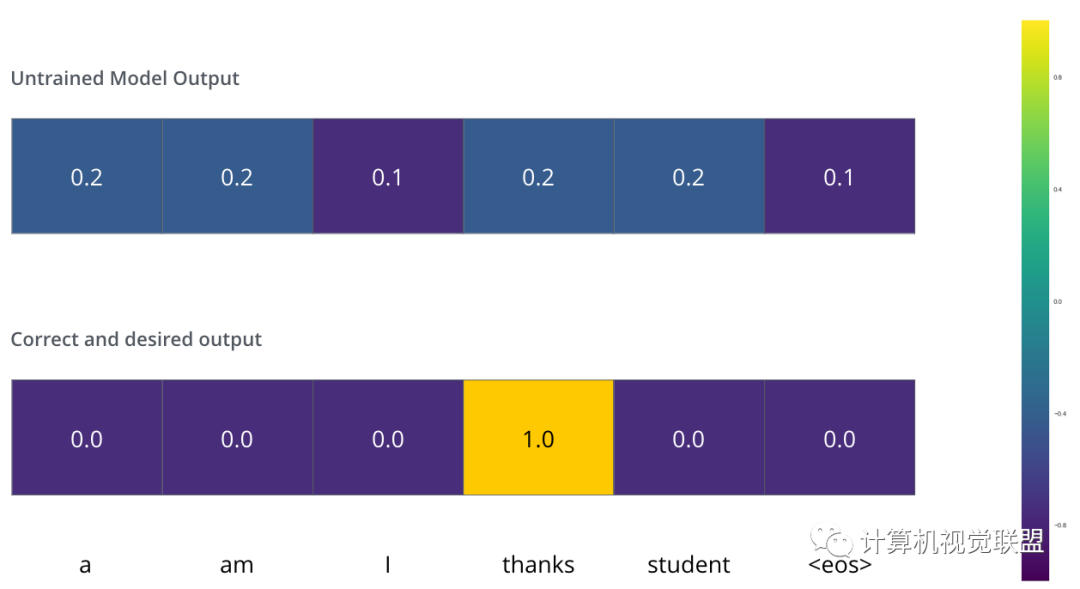
In practice, a simple subtraction suffices.
Target Model Outputs
Trained Model Outputs
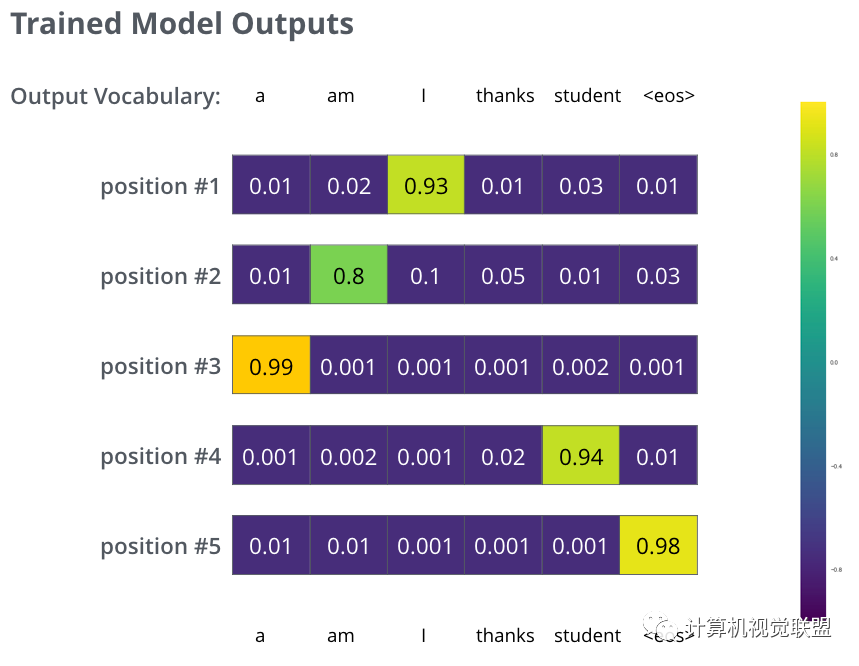
Although not very accurate, it is possible to find the maximum probability value through comparison.
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of "Beginner Learning Visuals" public account to download the first OpenCV extension module tutorial in Chinese on the internet, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than 20 chapters of content.
Download 2: Python Visual Practice Project 52 Lectures
Reply "Python Visual Practice Project" in the backend of "Beginner Learning Visuals" public account to download 31 visual practice projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the backend of "Beginner Learning Visuals" public account to download 20 practical projects based on OpenCV to advance OpenCV learning.
Communication Group
Welcome to join the reader group of the public account to exchange with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually subdivide in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiaotong University + Visual SLAM". Please follow the format; otherwise, it will not be approved. After successful addition, you will be invited into the relevant WeChat group based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding~