
Click on the above “Beginner’s Guide to Vision“, choose to add “Star” or “Pin“
Important content delivered first

This article is reproduced from Zhihu, with the author’s permission.
https://zhuanlan.zhihu.com/p/146130215
Previously, I was looking at the self-attention in the DETR paper, and combined with the attention mechanism often mentioned in the lab meetings, I spent time this week organizing the attention mechanism and reading relevant source code to understand its implementation mechanism.
The attention mechanism can be regarded as a resource allocation mechanism, which can be understood as reallocating resources originally distributed evenly based on the importance of the attention object. Important units get a bit more, while unimportant or poor units get a bit less. In the design of deep neural network structures, the resources that attention needs to allocate are basically weights.
Visual attention is divided into several types, the core idea is to find the correlation between existing data and highlight certain important features. There are channel attention, pixel attention, multi-level attention, etc., and self-attention from NLP is also introduced.
References: http://papers.nips.cc/paper/7181-attention-is-all-you-need
Reference Material: https://zhuanlan.zhihu.com/p/48508221
GitHub: https://github.com/huggingface/transformers
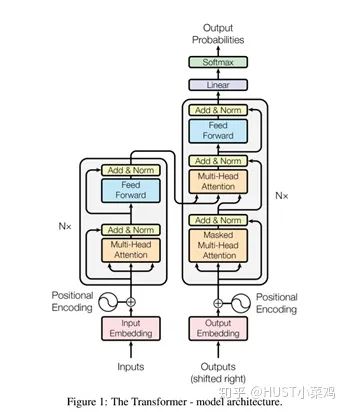
Self-attention, sometimes referred to as internal attention, is an attention mechanism related to different positions of a single sequence. Its purpose is to calculate the representation of the sequence, because of the decoder’s position invariance, and in DETR, each pixel not only contains numerical information, but also the positional information of each pixel is very important.

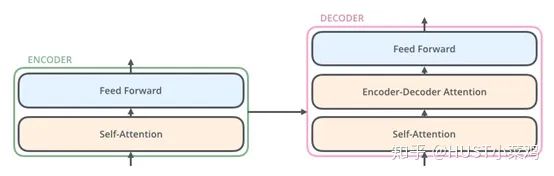
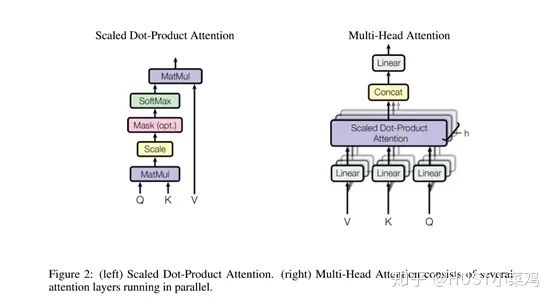
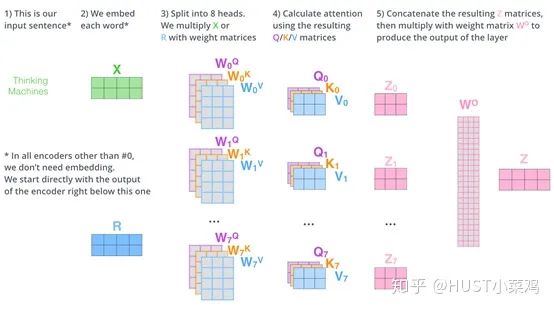
All encoders are structurally the same, but they do not share parameters. Each encoder can be decomposed into two sub-layers:
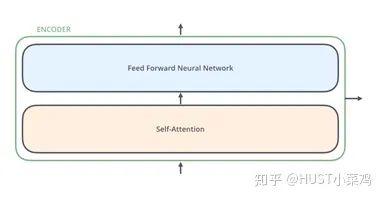
In the transformer, each encoder sub-layer consists of Multi-head Self-Attention and Position-wise FFN.
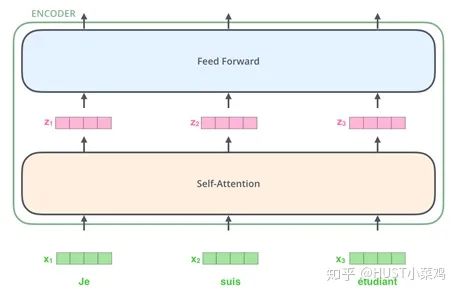
Self-Attention
Self-Attention is the core content of the Transformer, which can be understood as mapping a queue and a set of values corresponding to the input, forming a mapping from query, key, value to output. The output can be viewed as a weighted sum of the values, with the weights derived from Self-Attention.
The specific implementation details are as follows:
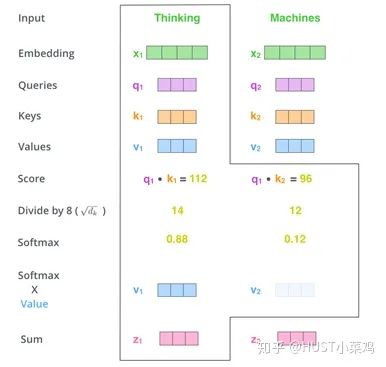
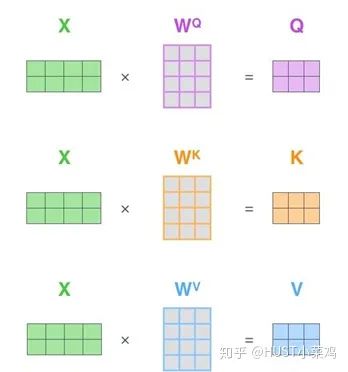
In self-attention, each word has three different vectors: the Query vector, the Key vector, and the Value vector, all of length 64. They are obtained by multiplying the embedding vector X by three different weight matrices, where the sizes of the three matrices are also the same, all being 512×64.
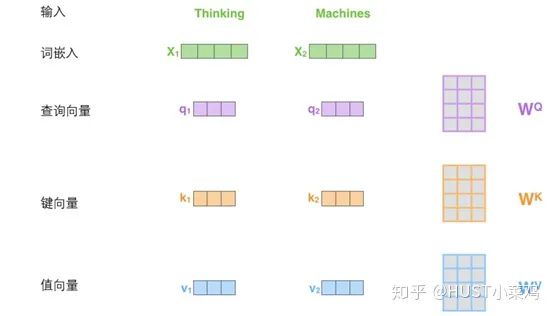
1) Convert the input word into an embedding vector;
2) Obtain the q, k, v vectors from the embedding vector;
3) Calculate a score for each vector: score=q×v;
4) For gradient stability, the Transformer uses score normalization, dividing by sqrt(dk);
5) Apply the softmax activation function to the score;
6) Multiply the softmax by the Value vector v to obtain the weighted score for each input vector v;
7) Sum to get the final output result z.
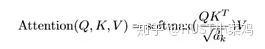
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
"""DETR Transformer class.Copy-paste from torch.nn.Transformer with modifications:
* positional encodings are passed in MHattention
* extra LN at the end of encoder is removed
* decoder returns a stack of activations from all decoding layers"""
import copy
from typing import Optional, List
import torch
import torch.nn.functional as F
from torch import nn, Tensor
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
mask = mask.flatten(1)
tgt = torch.zeros_like(query_embed)
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
for layer in self.layers:
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
if self.norm is not None:
output = self.norm(output)
return output
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
output = tgt
intermediate = []
for layer in self.layers:
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate)
return output
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
def forward_pre(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm1(tgt)
q = k = self.with_pos_embed(tgt2, query_pos)
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
def _get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
def build_transformer(args):
return Transformer(
d_model=args.hidden_dim,
dropout=args.dropout,
nhead=args.nheads,
dim_feedforward=args.dim_feedforward,
num_encoder_layers=args.enc_layers,
num_decoder_layers=args.dec_layers,
normalize_before=args.pre_norm,
return_intermediate_dec=True,
)
def _get_activation_fn(activation):
"""Return an activation function given a string"""
if activation == "relu":
return F.relu
if activation == "gelu":
return F.gelu
if activation == "glu":
return F.glu
raise RuntimeError(F"activation should be relu/gelu, not {activation}.")Soft attention is a continuous distribution problem between [0,1], focusing more on areas or channels. Soft attention is deterministic attention, which can be generated by the network after learning, and is differentiable, allowing gradients to be computed through neural networks and to learn the attention weights through forward and backward propagation.
1. Spatial Domain Attention (Spatial Transformer Network)
Paper link: http://papers.nips.cc/paper/5854-spatial-transformer-networks
GitHub link: https://github.com/fxia22/stn.pytorch
Spatial region attention can be understood as allowing the neural network to see where it is looking. Through the attention mechanism, the spatial information in the original image is transformed into another space while retaining key information. Many existing methods use this type of network; one I have encountered is ALPHA Pose.
Spatial transformer is actually the implementation of the attention mechanism, as the trained spatial transformer can identify the regions in the image that need attention, and this transformer can also have the function of rotation and scaling transformation, allowing the extraction of important local information from the image through transformation.
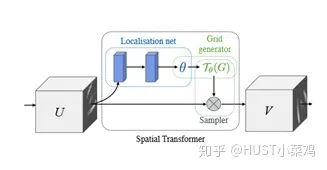
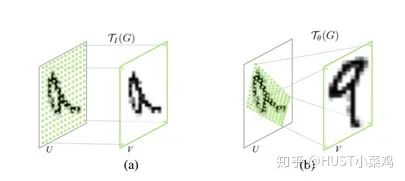
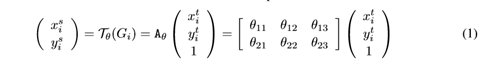
The main focus is on learning the spatial transformation matrix.
class STN(Module):
def __init__(self, layout = 'BHWD'):
super(STN, self).__init__()
if layout == 'BHWD':
self.f = STNFunction()
else:
self.f = STNFunctionBCHW()
def forward(self, input1, input2):
return self.f(input1, input2)
class STNFunction(Function):
def forward(self, input1, input2):
self.input1 = input1
self.input2 = input2
self.device_c = ffi.new("int *")
output = torch.zeros(input1.size()[0], input2.size()[1], input2.size()[2], input1.size()[3])
#print('device %d' % torch.cuda.current_device())
if input1.is_cuda:
self.device = torch.cuda.current_device()
else:
self.device = -1
self.device_c[0] = self.device
if not input1.is_cuda:
my_lib.BilinearSamplerBHWD_updateOutput(input1, input2, output)
else:
output = output.cuda(self.device)
my_lib.BilinearSamplerBHWD_updateOutput_cuda(input1, input2, output, self.device_c)
return output
def backward(self, grad_output):
grad_input1 = torch.zeros(self.input1.size())
grad_input2 = torch.zeros(self.input2.size())
#print('backward device %d' % self.device)
if not grad_output.is_cuda:
my_lib.BilinearSamplerBHWD_updateGradInput(self.input1, self.input2, grad_input1, grad_input2, grad_output)
else:
grad_input1 = grad_input1.cuda(self.device)
grad_input2 = grad_input2.cuda(self.device)
my_lib.BilinearSamplerBHWD_updateGradInput_cuda(self.input1, self.input2, grad_input1, grad_input2, grad_output, self.device_c)
return grad_input1, grad_input22. Channel Attention (Channel Attention, CA)
Channel attention can be understood as letting the neural network see what it is looking at. A typical representative is SENet. Each layer of the convolutional network has many convolution kernels, each corresponding to a feature channel. Compared to spatial attention mechanisms, channel attention allocates resources between each convolution channel, with a coarser granularity than the former.
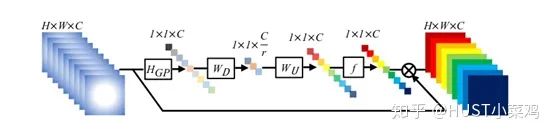
Paper: Squeeze-and-Excitation Networks (https://arxiv.org/abs/1709.01507)
GitHub link: https://github.com/moskomule/senet.pytorch
Squeeze operation: Uses global spatial features of each channel as the representation of that channel, generating statistics for each channel using global average pooling.
Excitation operation: Learn the dependency of each channel and adjust different feature maps based on the dependency, obtaining the final output, which requires examining the dependency of each channel.
The overall structure is shown in the figure:
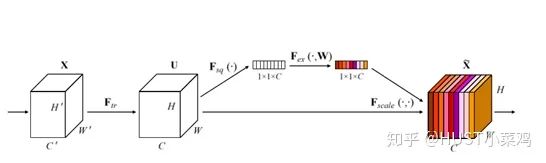
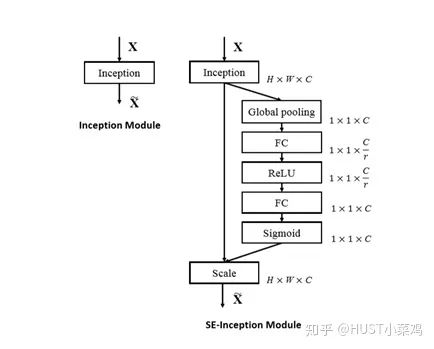
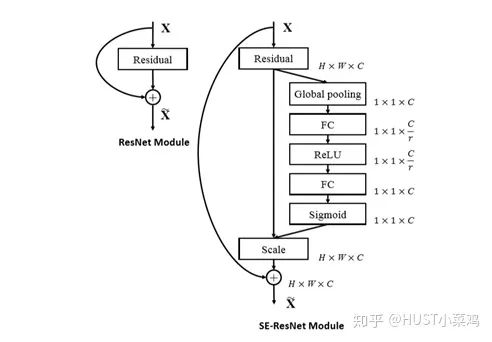
Global avgpooling is performed on the input features to obtain 1×1×Channel.
Then the bottleneck features interact, first compressing the number of channels, and then reconstructing back to the number of channels.
Finally, a sigmoid is added to generate attention weights between channels from 0 to 1, which are then scaled back to the original input features.
SE-ResNet‘s SE-Block
class SEBasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None,
*, reduction=16):
super(SEBasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, 1)
self.bn2 = nn.BatchNorm2d(planes)
self.se = SELayer(planes, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.se(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)Basic Block of ResNet‘s
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
if inplanes != planes:
self.downsample = nn.Sequential(nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes))
else:
self.downsample = lambda x: x
self.stride = stride
def forward(self, x):
residual = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual
out = self.relu(out)
return outThe main difference between the two lies in the addition of a SELayer. For details, please refer to the source code.
3. Hybrid Domain Model (Integrating Spatial and Channel Attention)
(1) Paper: Residual Attention Network for Image Classification (CVPR 2017 Open Access Repository)
The attention mechanism in this article is based on soft attention with a masking mechanism, but the difference is that this attention mechanism’s mask draws on the idea of residual networks. It not only adds the mask based on the information of the current network layer but also passes down the information from the previous layer, preventing the issue of insufficient information due to masking that could hinder the stacking of network layers.
The innovation of the attention mechanism in this article is the proposal of residual attention learning, which not only uses the masked feature tensor as the input for the next layer but also passes the unmasked feature tensor as input for the next layer, allowing for richer features to be obtained and thus better attention to key features. Additionally, a third-order attention module is used to construct the entire attention.
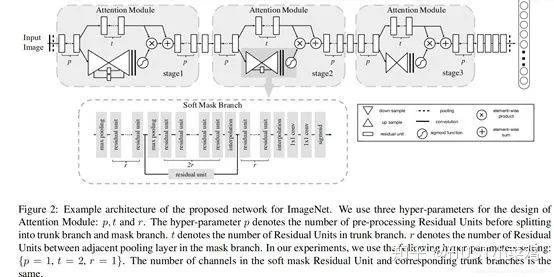
(2) Paper: Dual Attention Network for Scene Segmentation (CVPR 2019 Open Access Repository)
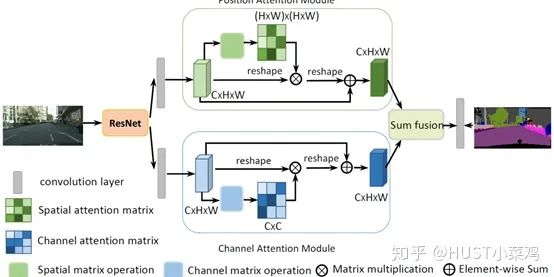
Paper: Non-local Neural Networks (CVPR 2018 Open Access Repository)
GitHub link: https://github.com/AlexHex7/Non-local_pytorch
The term local refers to the receptive field. For example, the size of a single convolution operation’s receptive field is the size of the convolution kernel, and we generally choose kernels like 3*3 or 5*5, which only consider local areas, thus performing local operations. Pooling is also local. In contrast, non-local refers to a receptive field that can be large, not confined to a local domain. Fully connected layers are non-local and global.
However, fully connected layers bring a large number of parameters, complicating optimization. Stacking convolutional layers can increase the receptive field, but if we look at the receptive field of a specific layer’s convolution kernel on the original image, it is still limited. This is an unavoidable aspect of local operations.
However, some tasks may require more information from the original image, such as attention. If global information can be introduced at certain layers, it can effectively resolve the situation where local operations cannot clearly see the global context, providing richer information for subsequent layers.
The general non-local computation defined for neural networks is as follows:
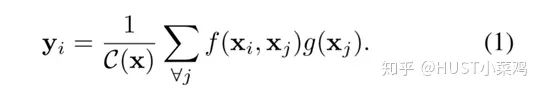
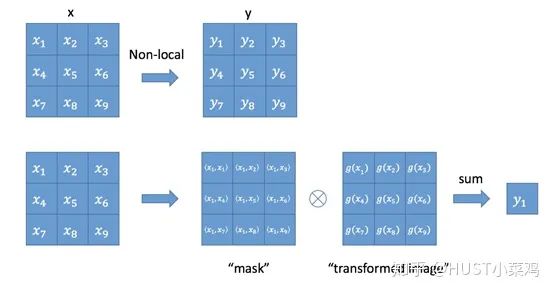
If implemented using a for loop according to the above formula, it would definitely be very slow. Additionally, applying non-local layers on large input sizes would also be computationally expensive.
A solution for the latter is to only introduce non-local layers at higher semantic levels. We can also further reduce computation by adding pooling layers to the embedding results.
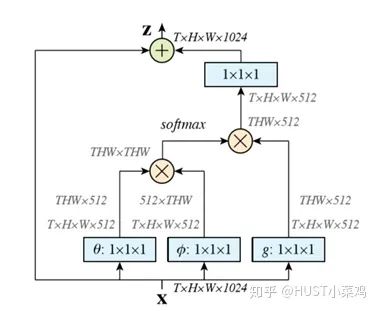
First, perform linear mapping on the input feature map X (through 1×1 convolution to compress the number of channels), then obtain the θ, ϕ, g features.
By reshaping, forcibly merging the dimensions of the three features except for the number of channels, and then performing matrix dot multiplication, we obtain something similar to a covariance matrix (this process is important, as it calculates the self-correlation of the features, i.e., the relationship between each pixel in each frame and all other pixels in all frames).
Then apply softmax to the self-correlation features by column or row (depending on the form of the matrix g) to obtain weights between 0 and 1, which are the self-attention coefficients we need.
Finally, multiply the attention coefficients back to the feature matrix g, and then expand the number of channels, adding residual connections to the original input feature map X.
5. Position Attention (Position-wise Attention)
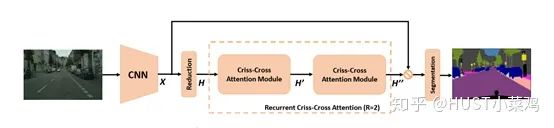
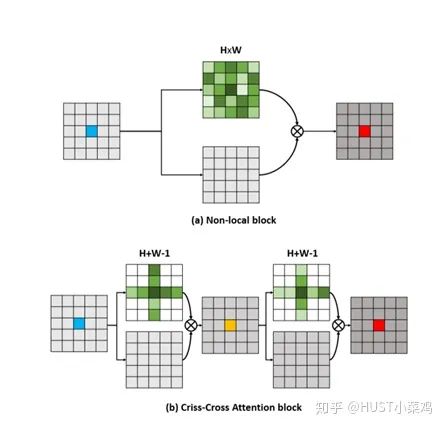
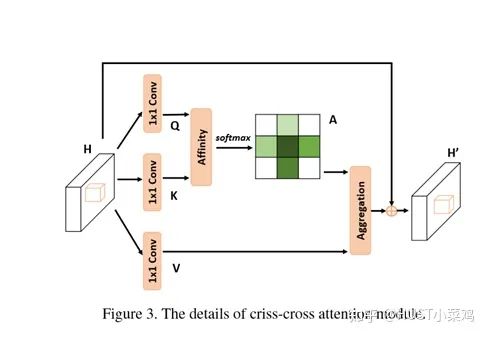
Paper: CCNet: Criss-Cross Attention for Semantic Segmentation (ICCV 2019 Open Access Repository)
GitHub link: https://github.com/speedinghzl/CCNet
The highlight of this article is the clever method used to reduce the number of parameters. In the above DANet, the attention map calculates the similarity between all pixels and all pixels, with spatial complexity of (HxW)x(HxW), while this article adopts the criss-cross idea, calculating only the similarity between each pixel and its corresponding row and column, thus indirectly calculating the similarity between each pixel and every other pixel, reducing spatial complexity to (HxW)x(H+W-1).
def _check_contiguous(*args):
if not all([mod is None or mod.is_contiguous() for mod in args]):
raise ValueError("Non-contiguous input")
class CA_Weight(autograd.Function):
@staticmethod
def forward(ctx, t, f):
# Save context
n, c, h, w = t.size()
size = (n, h+w-1, h, w)
weight = torch.zeros(size, dtype=t.dtype, layout=t.layout, device=t.device)
_ext.ca_forward_cuda(t, f, weight) # Output
ctx.save_for_backward(t, f)
return weight
@staticmethod
@once_differentiable
def backward(ctx, dw):
t, f = ctx.saved_tensors
dt = torch.zeros_like(t)
df = torch.zeros_like(f)
_ext.ca_backward_cuda(dw.contiguous(), t, f, dt, df)
_check_contiguous(dt, df)
return dt, df
class CA_Map(autograd.Function):
@staticmethod
def forward(ctx, weight, g):
# Save context
out = torch.zeros_like(g)
_ext.ca_map_forward_cuda(weight, g, out) # Output
ctx.save_for_backward(weight, g)
return out
@staticmethod
@once_differentiable
def backward(ctx, dout):
weight, g = ctx.saved_tensors
dw = torch.zeros_like(weight)
dg = torch.zeros_like(g)
_ext.ca_map_backward_cuda(dout.contiguous(), weight, g, dw, dg)
_check_contiguous(dw, dg)
return dw, dg
ca_weight = CA_Weight.apply
ca_map = CA_Map.apply
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self,in_dim):
super(CrissCrossAttention,self).__init__()
self.chanel_in = in_dim
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self,x):
proj_query = self.query_conv(x)
proj_key = self.key_conv(x)
proj_value = self.value_conv(x)
energy = ca_weight(proj_query, proj_key)
attention = F.softmax(energy, 1)
out = ca_map(attention, proj_value)
out = self.gamma*out + x
return out
__all__ = ["CrissCrossAttention", "ca_weight", "ca_map"]0/1 problem, which points receive attention and which do not. Hard attention focuses more on specific points, where each point in the image may extend attention, and hard attention is a random prediction process, emphasizing dynamic changes and is non-differentiable, so the training process often relies on reinforcement learning.
Reference Materials:
【1】blog.csdn.net/xys43038
【2】https://zhuanlan.zhihu.com/p/33345791
【3】https://zhuanlan.zhihu.com/p/54150694
Good news!
The Beginner's Guide to Vision knowledge community
is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of "Beginner's Guide to Vision" public account to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the background of "Beginner's Guide to Vision" public account to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, eye line addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the background of "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Discussion Group
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups on SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will be gradually subdivided). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, entry will not be allowed. After successfully adding, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding~