
Author: Chen Zhi Yan
This article is approximately 3500 words long and is recommended for a 7-minute read.
The Transformer is the first model that completely relies on the self-attention mechanism to compute its input and output representations.
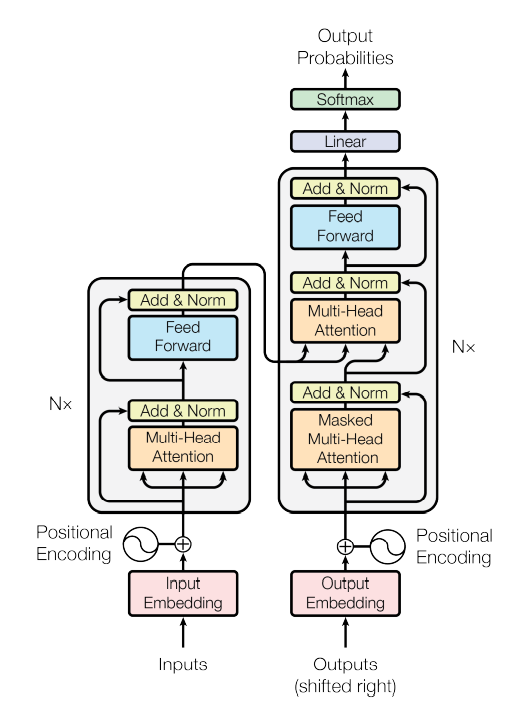
Figure 1-1 Stacked Encoder-Decoder Structure (Source: Internet)
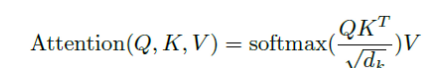
-
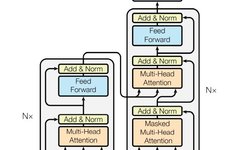
In the encoder-decoder attention layer, Q values come from the previous decoder layer, while K and V values come from the encoder’s output, allowing every position in the decoder to be related to the input sequence’s position. This architecture mimics the attention mechanism in sequence-to-sequence model encoders and decoders. -
The encoder includes a self-attention layer, where Q, K, and V values all come from the output of the previous encoder layer, allowing position information in the encoder to participate in the previous layer’s position encoding. -
Similarly, the self-attention mechanism in the decoder allows position information in the decoder to participate in the decoding of all position information.
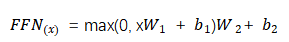
 Table 3-1 Maximum Path Length, Complexity per Layer, and Minimum Operations for Different Layer Sequences
Table 3-1 Maximum Path Length, Complexity per Layer, and Minimum Operations for Different Layer Sequences .
.4.1 Training Data and Batch Size
4.2 Hardware Configuration
4.3 Optimizer
4.4 Regularization
4.5 Training Results
Author Biography
Chen Zhi Yan, graduated from Beijing Jiaotong University with a master’s degree in Communication and Control Engineering. He has served as an engineer at Great Wall Computer Software and Systems Company and Datang Microelectronics Company. Currently, he is engaged in the operation and maintenance of intelligent translation teaching systems and has accumulated experience in artificial intelligence deep learning and natural language processing (NLP).
Editor: Yu Teng Kai
Proofreader: Lin Yi Lin
Data Research Department Introduction
The Data Research Department was established in early 2017, dividing into several groups based on interest. Each group adheres to the overall knowledge sharing and practical project planning of the research department while having its own characteristics:
Algorithm Model Group: Actively participates in competitions like Kaggle, original hands-on teaching series articles;
Research Analysis Group: Explores the beauty of data products through interviews and other methods;
System Platform Group: Tracks cutting-edge technologies in big data & artificial intelligence systems and dialogues with experts;
Natural Language Processing Group: Focuses on practice, actively participates in competitions and plans various text analysis projects;
Manufacturing Big Data Group: Upholds the dream of an industrial power, integrating industry, academia, research, and government to explore data value;
Data Visualization Group: Merges information with art, explores the beauty of data, and learns to tell stories with visualization;
Web Crawling Group: Crawls web information and collaborates with other groups to develop creative projects.
Click on the end of the article “Read Original” to sign up for Data Research Department Volunteers, there is always a group that suits you~
Reprint Notice
If you need to reprint, please indicate the author and source (Reprinted from: Data Research THUID: DatapiTHU) prominently at the beginning of the article, and place a prominent QR code for Data Research at the end of the article. For articles with original identification, please send the 【Article Name – Pending Authorized Public Account Name and ID】 to the contact email to apply for whitelist authorization and edit as required.
Unauthorized reprints and adaptations will be legally pursued.


Click “Read Original” to join the organization~