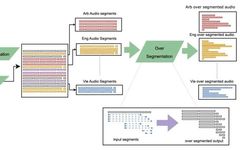
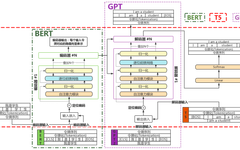
Application Of Large-Scale Pre-trained Models In Quantitative Investment (Part 1)

Application of Large-Scale Pre-trained Models in Quantitative Investment (Part 1) Research Unit: Taiping Asset Management Co., Ltd. Project Leader: Wang Zhenzhou Project Team Members: Wang Teng, Yi Chao, Zuo Wenting, Hu Qiang, Yu Hui Abstract: This project deeply explores the application of large-scale pre-trained models in the field of quantitative investment, mainly addressing several key … Read more