Source: Algorithm Advancement
This article is approximately 8900 words long and is recommended to be read in 9 minutes.
This article comprehensively introduces evaluation methods for large language models.
Since the introduction of the Transformer model in 2017, research in natural language processing has gradually shifted towards pre-trained models based on this framework, such as BERT, GPT, BART, and T5. These pre-trained models continuously refresh optimal results when adapted to downstream tasks. However, existing evaluation methods suffer from insufficient breadth and depth, data bias, and neglect of other model capabilities or attribute assessments. Therefore, comprehensive evaluation and in-depth research on the various capabilities, attributes, application limitations, potential risks, and controllability of models are necessary.
This article reviews the evaluation benchmarks and metrics in natural language processing, categorizing large language model evaluations into classical and novel evaluation paradigms, and analyzes the shortcomings of existing evaluations. It then introduces comprehensive evaluation ideas, relevant metrics, and methods for large language models, summarizing the new directions in large language model evaluation that are currently receiving widespread attention. It should be noted that the large language models referred to in this article are not strictly limited by scale but refer to language models based on pre-training with general capabilities.
1 Evaluation Paradigms in Natural Language Processing
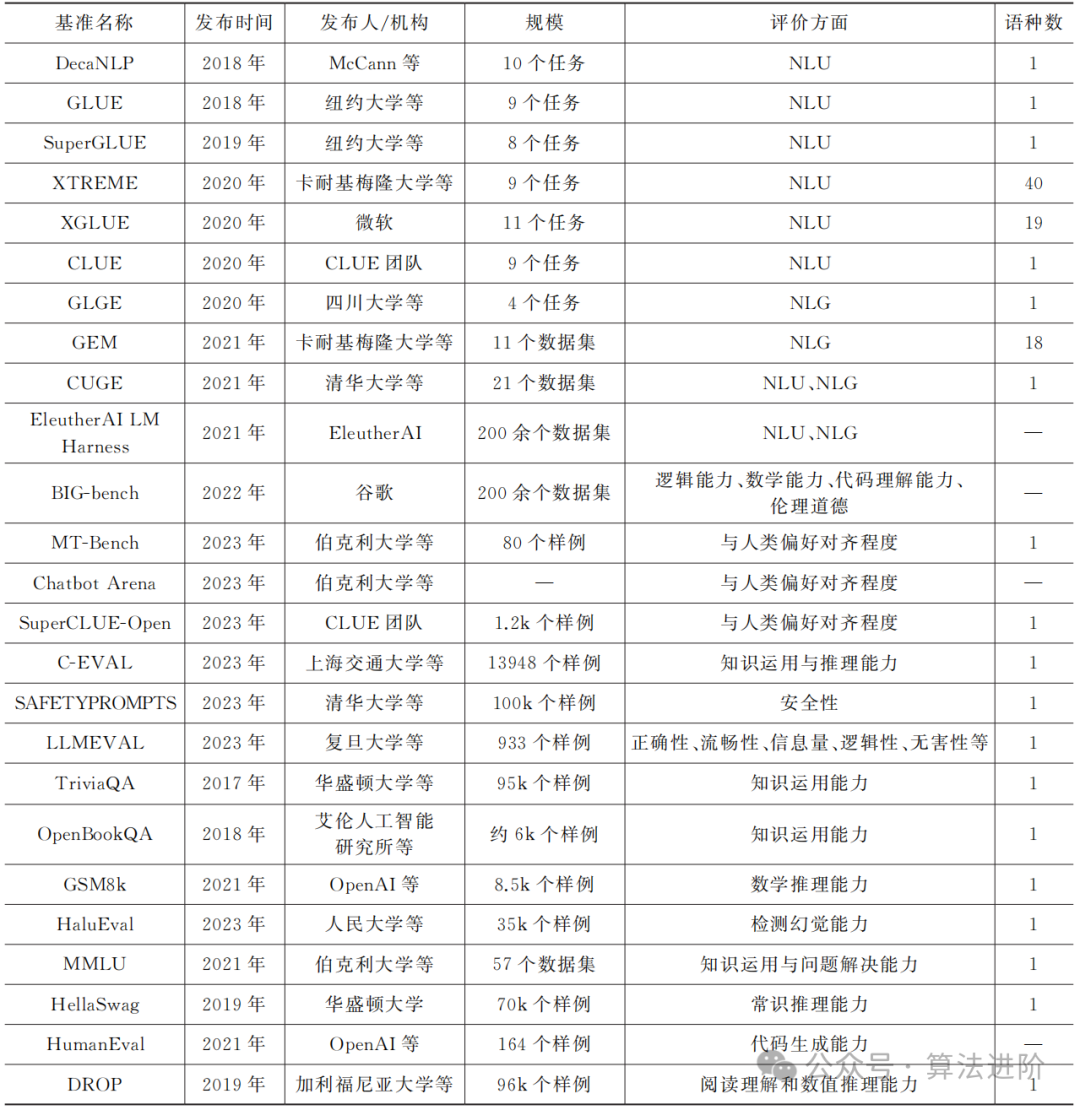
The development of natural language processing has benefited from its evaluation. Evaluations typically rely on a set of benchmarks, where models run on these benchmark datasets and produce outputs, and the evaluation system returns a value representing the model’s capabilities. The simplest evaluation benchmarks consist of a single dataset on a single task, which is also a common basic evaluation mode in natural language processing. To comprehensively assess large language models, multiple datasets can be aggregated and reorganized to form a more general evaluation benchmark. This chapter classifies the evaluation paradigms for large language models, dividing them into classical evaluation paradigms and novel evaluation paradigms. Table 1 lists some typical evaluation benchmarks. Below, we will introduce the classical evaluation paradigms and the novel evaluation paradigms aimed at multiple capabilities, along with the shortcomings of existing evaluations.
Table 1 Some Typical Evaluation Benchmarks
1.1 Classical Evaluations in Natural Language Processing
Natural language processing is divided into two main categories: natural language understanding (NLU) and natural language generation (NLG), but under the classical evaluation paradigm, it mainly focuses on the degree of match between the model’s final output results and reference answers. The structure of classical evaluations is shown in Figure 1.
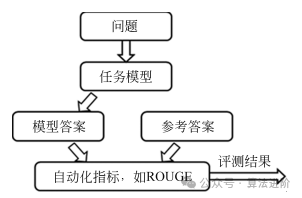
Figure 1 Structure of Classical Evaluations
1.1.1 Evaluation of Natural Language Understanding Capabilities
Evaluation of natural language understanding capabilities refers to assessing the model’s ability to understand natural language. Common natural language understanding tasks include sentiment analysis, text matching, text classification, and reading comprehension. There are numerous relevant evaluation benchmarks for specific tasks. For example, GLUE is a benchmark that includes nine natural language understanding tasks, such as sentiment analysis, text entailment, and sentence similarity. XTREME is a large-scale, multi-task, multi-language model evaluation benchmark involving 40 different languages and nine tasks. In the realm of Chinese information processing, CLUE is a large-scale Chinese understanding evaluation benchmark that includes multiple Chinese natural language understanding tasks such as text classification, reading comprehension, and natural language inference, along with a diagnostic evaluation dataset.
1.1.2 Evaluation of Natural Language Generation Capabilities
Evaluation of natural language generation capabilities refers to assessing the model’s ability to generate natural language. Common natural language generation tasks include machine translation, generative text summarization, and automated dialogue. There are numerous relevant evaluation benchmarks for these tasks. For instance, BLEU is an important metric for assessing translation quality in machine translation tasks, calculating scores by measuring the N-gram matching degree between the generated text and the reference text. Additionally, there are metrics such as METEOR and ROUGE used to evaluate the generation quality of text summarization and question generation tasks.
1.1.3 Evaluation Considering Both Understanding and Generation Capabilities
Given the rapid development of large language models and their widespread application in downstream tasks, evaluation benchmarks that only assess a single capability of the model cannot meet the evaluation needs. Therefore, many new and more comprehensive evaluation benchmarks are continuously being introduced, which typically aggregate multiple datasets, tasks, and evaluation metrics to provide a more comprehensive assessment of model capabilities. For example, research institutions such as Peking University, Tsinghua University, and the Beijing Academy of Artificial Intelligence jointly proposed a benchmark for evaluating Chinese understanding and generation capabilities, CUGE, which covers seven important language functions, including character-level language understanding, discourse-level language understanding, information retrieval and question-answering capabilities, language generation capabilities, conversational interaction capabilities, multilingual capabilities, and mathematical reasoning capabilities, further subdivided into 18 mainstream NLP tasks.
1.2 Novel Evaluation Paradigms for Multiple Capabilities
Novel evaluation paradigms emphasize that large language models should not only be evaluated based on understanding and generation capabilities but also whether they conform to social moral standards. This paradigm provides researchers with more dimensions and in-depth evaluation methods, helping to promote the continuous advancement and improvement of natural language processing technology.
1.2.1 Evaluation of Multiple Attributes
To track the impact of large language model scale on model performance, researchers have proposed evaluations of multiple attributes, including knowledge application ability, mathematical reasoning ability, and hallucination detection ability. These evaluation benchmarks include both simulated exams originally designed for humans and benchmarks used to evaluate language models on traditional natural language processing tasks. For example, TriviaQA and OpenBookQA are used to evaluate the knowledge application ability of large language models, GSM 8k is used to evaluate the mathematical reasoning ability of large language models, and HaluEval is used to evaluate the hallucination detection ability of large language models. These evaluation benchmarks help to comprehensively assess the performance of large language models.
1.2.2 Example of Model Evaluation — Evaluation of GPT-4
OpenAI uses a series of evaluation benchmarks to assess the performance of GPT-4, including simulated exams designed for humans and benchmarks from traditional natural language processing tasks. The simulated exams include SAT Math and Leetcode, primarily assessing mathematical problems and comprehensive coding abilities. The benchmarks from traditional natural language processing tasks include MMLU, HellaSwag, HumanEval, and DROP, which assess the model’s ability to apply knowledge to problem-solving, commonsense reasoning ability, code generation ability, and reading comprehension and numerical reasoning ability, respectively. The evaluation results indicate that GPT-4 performs comparably to humans in most professional and academic exams, achieves state-of-the-art results on multiple traditional natural language processing evaluation benchmarks, and demonstrates the ability to handle low-resource languages.
Microsoft researchers proposed a human-centered evaluation benchmark, AGIEval, based on human-level cognitive abilities closely related to the real world, and evaluated the performance of large language models like GPT-4 and ChatGPT on it. The evaluation data of AGIEval comes from standardized, official human exam questions, such as GRE, SAT, Chinese college entrance examination, LSAT, AMC, and Chinese civil service examination. Unlike literature [35], AGIEval retains only objective questions (multiple choice and fill-in-the-blank) to evaluate large language models in a more standardized and automated manner. The evaluation includes four setups: zero-shot learning, few-shot learning, zero-shot chain of thought, and few-shot chain of thought. The results show that GPT-4 surpasses human average performance in LSAT, SAT, and math competitions, achieving an accuracy rate of 95% in the SAT math exam. However, large language models perform poorly on tasks requiring complex reasoning or specific domain knowledge. Additionally, compared to the GPT-3 series models, the zero-shot learning ability of large language models like GPT-4 is gradually approaching that of few-shot learning.
1.3 Shortcomings of Existing Evaluations
1.3.1 Lack of Evaluation Benchmarks for Emerging Tasks
With the development of general large language models, more application scenarios and tasks are needed to assess their effectiveness. However, some emerging tasks lack evaluation benchmarks, which limits the development of the field. Evaluation benchmarks are key to assessing model performance and comparing different models. Without them, researchers find it difficult to accurately assess model performance and effectively evaluate and compare emerging algorithms and models. Moreover, the lack of evaluation benchmarks also affects the understanding and definition of emerging tasks. Therefore, establishing evaluation benchmarks is crucial for research on the application of models in emerging tasks and can help researchers better understand the application potential of large language models in these tasks.
1.3.2 Lack of Discriminatory Power in Evaluation Tasks
As the capabilities of large language models have improved, their performance on some evaluation tasks has become comparable to or even surpassing that of humans, leading many evaluation tasks to lose challenge and discriminatory power, making it difficult to provide valuable information to researchers. This issue reflects not only the problem of evaluation benchmarks but also the trend of large language model development exceeding the scope of existing assessment tasks. Therefore, more attention needs to be paid to the discriminatory power and difficulty of evaluation tasks to ensure that evaluation results have practical reference significance.
1.3.3 Unfair Evaluation Methods
Unfair evaluation methods primarily manifest in unfairness in the selection of evaluation metrics and datasets, as well as human factors that may lead to unfair evaluation results. In terms of evaluation metrics, the same task’s evaluation datasets may produce contradictory situations where model A outperforms model B on one evaluation dataset but underperforms on another. Human factors can also lead to unfair evaluation results; for example, in manual evaluations, the background, perspectives, and experiences of evaluators may influence their judgments of models, introducing human bias into the evaluation results.
1.3.4 Incomplete Evaluations
Currently, evaluations of a model’s single capabilities are often simplified to single metrics on single datasets for single tasks, which cannot accurately reflect the strengths and weaknesses of the model in the evaluated capability. For example, evaluating natural language generation capabilities requires examining multiple aspects, but different aspects may apply different evaluation metrics. Different tasks and datasets will involve various language phenomena and application scenarios, which are often overlooked in single metrics evaluations. Moreover, evaluations of the model’s comprehensive capabilities are mostly simple aggregations of single evaluation benchmarks, lacking systemic interactions, and cannot comprehensively assess the model’s overall capabilities and multiple attributes.
1.3.5 Pollution of Evaluation Benchmarks
The pollution of evaluation benchmarks refers to the presence of evaluation data in the model’s training data, affecting the fairness and credibility of the evaluations. To ensure fairness and credibility, the test data of evaluation benchmarks should not be included in the training data of large language models. Due to the vast amount of model training data, researchers find it challenging to determine whether evaluation benchmarks have leaked. Such pollution affects the fairness and credibility of evaluation benchmarks. Therefore, both benchmark builders and users need to carefully consider and ensure independence and representativeness. Future developers of large language models should clearly identify potential pollution issues and their extent.
1.3.6 Lack of Interpretability in Evaluation Results
In the evaluation of large language models, existing evaluation methods lack explanations and analyses of evaluation results, leading to a lack of interpretability. This deficiency mainly manifests in two aspects: first, digital evaluation methods make it difficult to understand the performance differences of models across different tasks and datasets; second, the lack of interpretability makes it challenging to determine the strengths and weaknesses of models on specific tasks, hindering targeted optimization and improvement. Therefore, enhancing the interpretability of evaluation results is crucial for improving model performance and optimization.
2 Comprehensive Evaluation of Large Language Models
HELM is a comprehensive evaluation method for large language models proposed by Liang et al., applicable to multiple scenarios, tasks, and evaluation metrics. It selects applicable tasks as evaluation priorities and chooses a subset of main evaluation data. HELM defines seven evaluation metrics, such as accuracy, and seven more targeted evaluation dimensions, such as language ability and reasoning ability. It has evaluated 30 large language models across 42 scenarios and evaluation metrics and publicly released the results. However, HELM also points out omissions and shortcomings in its evaluations, such as missing certain scenarios and tasks and insufficient evaluation methods. Due to some large models no longer being open-source, comprehensive evaluation becomes challenging. HELM treats large language models as black boxes, which is also one of its shortcomings. Evaluation attributes include accuracy, calibration, generalization ability, adaptability, robustness, efficiency, bias and stereotypes, fairness, and harmfulness.
Accuracy is an indicator that measures the proportion of correct predictions or generated results by the model, crucial for large language models handling natural language tasks and applications. The evaluation methods for accuracy vary based on scenarios and tasks. Common evaluation metrics include F1 score and accuracy (for classification problems), BLEU and ROUGE (for generation problems), exact match (for both classification and generation problems), reciprocal rank, and normalized discounted cumulative gain (for search problems). Accuracy metrics are widely used in natural language processing evaluations and will continue to be a significant evaluation metric.
While accuracy measures the correctness of the model’s output results, calibration measures the accuracy of the probabilities assigned to the output results, that is, the accuracy with which the model’s predictions estimate the true probability distribution. Evaluating the calibration of large language models is significant: first, it helps improve the reliability of the model; the higher the calibration, the more reliable the model’s predictions are; second, it aids in improving confidence estimation, as calibration can better help users understand the model’s predictions and intervene manually when necessary.
Expected Calibration Error (ECE) is an indicator for assessing model calibration, used to compare the gap between predicted probabilities and actual probabilities. It does this by dividing the probability range into M small intervals, calculating the sum of the product of the number of correctly predicted samples within each interval and their predicted probabilities, and dividing by the number of samples in the interval to obtain accuracy. It then calculates the average confidence for each interval, which is the mean of the predicted probabilities. Finally, the expected calibration error is the sum of the calibration gaps for all intervals, which is the difference between accuracy and average confidence.
2.3 Generalization Ability
The evaluation of a model’s generalization ability mainly focuses on its performance across different datasets, especially in few-shot or zero-shot settings. Few-shot refers to when the model is given only a small number of samples as reference during prediction, with parameters typically not updated. Zero-shot, on the other hand, does not provide reference examples, only the problem text, allowing the model to infer the answer directly. These two evaluation methods can effectively reflect the model’s generalization ability, which also indicates the model’s effectiveness when applied to downstream tasks. Therefore, evaluating generalization ability is one of the keys to assessing whether large language models can be broadly applied in practical scenarios and is an important component of future evaluations of large models.
The capabilities of large models on specific tasks can be enhanced through adaptation, which is the process of converting the original model into one suitable for specific downstream tasks. Adaptability refers to the model’s performance under different adaptation strategies. There are three adaptation strategies: adaptation without updating the original model parameters, adaptation that adds adaptation layers and adjusts their parameters, and adaptation that updates all parameters of the original model. Adaptation without updating model parameters achieves better results on downstream tasks by designing prompts and contextual examples, but how to choose the appropriate prompt format is crucial. Adding adaptation layers with a small number of parameters and adjusting their parameters is a highly efficient, low-loss adaptation method, for example, by adding adaptation layers that contain only a few parameters to the original model architecture while fixing the parameters of the original model itself, only updating the parameters of the adaptation layers based on gradients, thus reducing the scale of parameter updates. An extreme adaptation method is to update all parameters of the model, specifically, retraining the model using data from downstream tasks to iteratively update all model parameters.
Although large language models perform excellently, slight perturbations in data can lead to significant performance drops, indicating weak robustness. Robustness measures the model’s resistance to perturbations or noise in input data. One method to evaluate model robustness is to perturb text inputs and observe changes in model outputs. Perturbations can be categorized into adversarial and non-adversarial. Adversarial perturbations are deliberate modifications of input content to mislead the model into making incorrect predictions, significantly impacting the model’s predictions. Non-adversarial perturbations involve more natural and random changes to input content, simulating complex situations in real-world inputs. Adversarial perturbations can be used to evaluate the model’s handling of malicious inputs, while non-adversarial perturbations can measure the model’s performance when facing naturally erroneous inputs in the real world. When evaluating large language models, both types of perturbations need to be considered comprehensively to assess the model’s robustness more thoroughly.
The efficiency of large language models is crucial, including training efficiency and inference efficiency. Training efficiency refers to the complexity of the model during training, while inference efficiency refers to the inference complexity of the model without updating parameters. Evaluation metrics include energy consumption, CO2 emissions, number of parameters, FLOPS, actual inference time, and number of execution layers. Evaluating these metrics helps researchers choose suitable models to meet application needs.
Large language models may exhibit discriminatory behavior in applications due to their underlying biases and stereotypes. The methods for evaluating bias and stereotypes in models can be categorized into two main types: representation-based evaluation methods and generation-based evaluation methods. Representation-based evaluation methods primarily use the geometric relationships of word vectors in the semantic vector space to represent the degree of association between vocabulary, thus reflecting biases and stereotypes in language models. Generation-based evaluation methods focus on using the model’s generation to measure its degree of bias. However, these evaluation methods often rely on manually curated word lists to represent a specific group or attribute label, which may introduce the inherent biases of the curators. Currently, the NLP community still faces some issues regarding bias assessment, such as ambiguous criteria for defining bias, unclear relevance of some evaluation methods to model performance in downstream applications, limited research on other forms of bias (e.g., religious, national), and a lack of relevant studies on bias assessment in non-English contexts.
While the accuracy of large language models in downstream tasks continues to improve, fairness issues are also receiving increasing attention. Fairness concerns the performance gaps of models on different feature groups in specific downstream tasks, while bias and stereotypes refer to certain inherent attributes within large language models. Currently, model fairness evaluations can be divided into predictive fairness, opportunity equality, and counterfactual fairness evaluations. As large language models develop, their capability range and application forms may become more extensive, and existing fairness evaluation paradigms based on single languages and single modalities need further iteration to adapt to broader group characteristics and more complex, intertwined language backgrounds.
The harmfulness of large language models refers to their ability to generate harmful statements, which can have adverse effects on social media and the internet. One method to assess their harmfulness is to use harmfulness detection systems, such as HateBERT and Perspective API. However, there is no unified definition of harmful statements, which adds complexity to system development. Developers need to consider the rationality of system design, the accuracy of dataset annotations, and bias issues, while balancing accuracy and fairness to avoid over-punishing or neglecting certain groups. Increasing the openness and transparency of systems will enhance the accuracy and fairness of harmfulness assessments.
3 New Directions in Large Language Model Evaluation
Since the launch of ChatGPT, generative large language models have had an increasing impact, and traditional generative evaluation methods face challenges. Researchers are exploring new evaluation models, such as model-based evaluation, hallucination problem evaluation, and meta-evaluation. These studies address the shortcomings of traditional evaluations and provide more precise, stable, and reliable assessment results for evaluating model performance, especially in natural language generation tasks.
3.1 Model-Based Evaluation
Automated evaluation methods in the field of natural language generation, such as BLEU and ROUGE, primarily rely on “form matching,” which neglects semantics, depends on reference texts, and struggles to capture subtle differences between different tasks. To overcome these limitations, researchers have begun to explore model-based evaluation methods, especially those based on large language models. These methods use pre-built evaluation models to assess task models, leveraging powerful representation learning and semantic understanding capabilities to better capture subtle differences between different generation tasks and correlate better with human evaluations. There are many model-based evaluation methods, among which representative methods include BERTScore (which relies on reference texts), GPTScore, Kocmi & Federmann, and PandaLM (which do not rely on reference texts).
BERTScore is a BERT-based evaluation method that assesses the similarity between the text to be evaluated and the reference text by calculating the cosine similarity. It first utilizes BERT’s word embeddings to obtain encoding vectors for the reference and target texts, then calculates precision and recall based on the cosine similarity between each token in the target text and each token in the reference text, and finally computes the F1 score based on precision and recall. The calculation structure of BERTScore is shown in Figure 2.
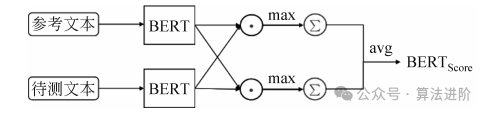
Figure 2 Calculation Structure of BERTScore
BERT for MTE is a BERT-based evaluation method that encodes both the text to be evaluated and the reference text simultaneously using sentence pair encoding and uses a regression model based on MLP to obtain the final metric score.
GPTScore is a model-based evaluation method that assigns higher generation probabilities to higher-quality generated content after providing instructions and the original text to the pre-trained large language model.
Kocmi & Federmann is a model-based evaluation method aimed at assessing generation tasks in a human-like manner. This method employs prompt engineering, combining instructions d, contextual information S, and the text to be evaluated into a template similar to human evaluation, inputting it to the pre-trained large language model. The model directly outputs scores, serving as task metric scores.
PandaLM is a comparative evaluation model that focuses on selecting the best model among various candidate task models based on generated content in the context of instruction tuning. PandaLM is tuned from LLaMA-7B and leverages the generalization ability of large language models to better capture nuanced differences in evaluation demands across different generation tasks, such as conciseness, clarity, comprehensiveness, and formality. Additionally, PandaLM can simultaneously identify and correct errors in task models.
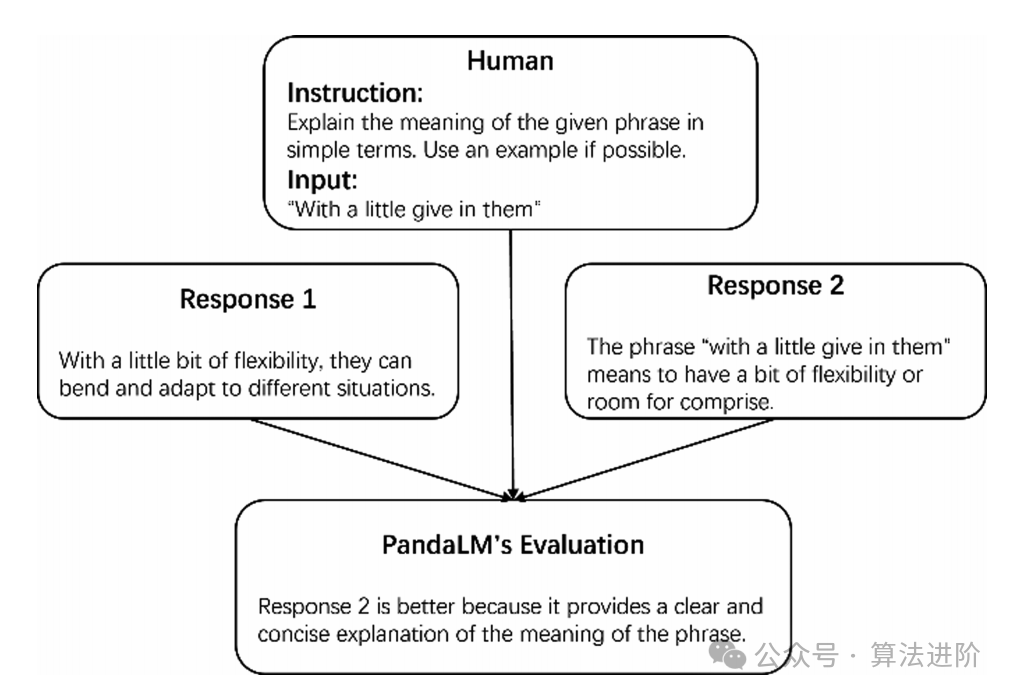
Figure 3 Structure of PandaLM Evaluation
Possible future research directions for model-based evaluations include:
-
More Robust Metrics: Develop more robust model-based evaluation metrics to reduce the impact of noise on evaluation results and improve the stability and reliability of evaluation results.
-
More Reliable Evaluation Methods: Further develop more reliable model-based evaluation methods to enhance the credibility of evaluation results.
-
Knowledge-Augmented Evaluation Methods: Explore methods to inject specific knowledge into large language models to improve the performance of model-based evaluation methods in certain specialized fields.
-
Fine-Grained Evaluation and Enhanced Interpretability: Focus on evaluation methods and interpretability of evaluation models in finer-grained divisions of generated content.
-
Breaking Dependence on Reference Texts: Explore how to utilize the zero-shot or few-shot generalization capabilities of large language models to eliminate dependence on reference texts in generative task evaluations, thereby obtaining more generalizable and transferable evaluation methods, metrics, and more accurate evaluation results.
-
Human-Machine Collaborative Evaluation: Attempt to propose effective ways to combine model-based evaluation with human evaluation to enhance the usability of human evaluations and the accuracy of model-based evaluations.
3.2 Evaluation of Hallucination Issues
Generative large language models have improved in text quality and fluency, but they may also produce inaccurate information, known as the “hallucination” phenomenon, which affects usability and reliability. Hallucinations can be categorized into internal and external types, with evaluation methods divided into non-large language model methods and large language model-based methods. Non-large language model methods include statistical, information extraction, generative question answering, and sentence-level classification, while large language model-based methods assess the degree of hallucination in text through understanding and generation capabilities, utilizing both direct and indirect evaluation methods. Direct evaluation methods use large language models as proxies to complete the work of human evaluators through template design; indirect evaluation methods utilize the model’s generation capabilities, combining other evaluation metrics and methods to obtain comprehensive measurement metrics that can handle complex semantic relationships and assess complex hallucination phenomena, such as logical errors and factual inaccuracies, while providing detailed information about the hallucination. However, it is important to note that the evaluation model itself may also produce hallucinations, and managing this is a challenge.
Future research directions for hallucination evaluation may include:
-
Improving Hallucination Detection: Existing methods face challenges in handling complex or ambiguous semantics. Future research should explore more complex models and algorithms to enhance accuracy and efficiency, as well as investigate how to leverage unlabeled or weakly labeled data to improve performance.
-
In-Depth Study of Hallucination Generation Mechanisms: Comprehensive evaluations can help researchers gain deeper insights into the causes of hallucinations, leading to the development of more comprehensive and targeted evaluation methods. This requires studying the internal working mechanisms of models, including language understanding and generation processes, as well as factors during the training process.
-
Designing General Hallucination Evaluation Methods: For different tasks in natural language generation, it is necessary to design task-independent general evaluation methods. This involves a deep understanding of the nature of hallucinations and the commonalities and peculiarities in different tasks, while considering the tolerance of tasks for hallucinations. Designing evaluation metrics that capture subtle differences between tasks and are highly correlated with human judgment is a current challenge.
In the evaluation of large language models, meta-evaluation is crucial. Meta-evaluation aims to assess the effectiveness and reliability of evaluation metrics, essentially re-evaluating the evaluations. Its core purpose is to determine the degree of correlation between evaluation methods and human assessments, which plays a key role in ensuring evaluation quality, reducing errors, and enhancing the credibility of results. As large language models are widely applied across various fields, the accuracy and credibility of evaluation methods themselves are increasingly under scrutiny. By comparing different evaluation methods, researchers can identify their respective strengths and limitations, allowing them to choose the most suitable evaluation methods for specific tasks and scenarios, accurately measuring model performance. Common correlation calculation methods in meta-evaluation include Pearson correlation coefficient, Spearman’s rank correlation coefficient, and Kendall’s tau coefficient.
The Pearson correlation coefficient is an indicator that measures the strength of the linear relationship between two variables, suitable for situations with strong linear relationships. It is less sensitive to nonlinear relationships and is significantly affected by outliers. However, skewed data distributions may lead to distortion in correlation coefficients, making it unsuitable for situations with complex nonlinear relationships or severe outliers or skewed data.
The Spearman correlation coefficient is an indicator that measures the monotonic relationship between two variables, based on the ranks of the data, making it relatively robust to outliers and skewed data, and capable of capturing nonlinear relationships. However, it only reflects the monotonic relationship between two variables, and when multiple dependencies exist between variables, relying solely on the Spearman correlation coefficient may be insufficient for differentiation.
Kendall’s tau coefficient is a coefficient based on data ranks used to measure the common trend between two variables. Similar to the Spearman correlation coefficient, Kendall’s tau coefficient is also based on data ranks, making it robust to outliers and skewed data. However, calculating Kendall’s tau coefficient requires enumerating every pair of data points, which performs better with small sample data but is less efficient with large sample data.
Research directions for meta-evaluation include:
-
Finer-Grained Meta-Evaluation: Assess the correlation of evaluation results for various evaluation metrics across different evaluation dimensions with human judgments, revealing the ability of evaluation metrics to capture subtle differences in different generation tasks, guiding improvements in evaluation methods themselves.
-
Meta-Evaluation of Fairness in Evaluation Metrics: Explore how evaluation metrics and methods are influenced by the professional backgrounds and cultural differences of human evaluators, as well as the impact of data scarcity on the performance of model-based evaluation methods in low-resource languages.
-
Meta-Evaluation of Robustness in Evaluation Metrics: Study the robustness of evaluation metrics through perturbation-based methods, revealing their stability when facing data noise, changes, or adversarial samples, thereby enhancing the reliability of evaluation methods.
Reference Link:
http://jcip.cipsc.org.cn/CN/Y2024/V38/I1/1
Data Club THU, as a public account in data science, is backed by the Tsinghua University Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, and striving to build a platform for gathering data talent, creating the strongest group of big data in China.

Weibo: @Data Club THU
WeChat Video Number: Data Club THU
Today’s Headlines: Data Club THU

