This article is approximately 2000 words long and takes about 5 minutes to read. If the goal is the model's zero-shot generalization capability, the decoder structure + language model task is the best; if multitask finetuning is also needed, the encoder-decoder structure + MLM task is the best.
From GPT-3 to prompts, more and more people have discovered that large models perform very well under the zero-shot learning setting. This has led to increasing expectations for AGI.
However, one thing is very puzzling: in 2019, T5 found through “hyperparameter tuning” that when designing pre-training models, the encoder-decoder model structure + MLM task achieved the best results in downstream task finetuning. Yet, as of 2022, mainstream large models are all using decoder-only model structures, such as OpenAI’s GPT series, Google’s PaLM [1], and DeepMind’s Chinchilla [2]. Why is this? Do these large model designs have issues?
Today, I bring you an article from Hugging Face and Google. This article shares a similar experimental approach to T5, and through extensive comparative designs, it reaches a significant conclusion: If the goal is the model’s zero-shot generalization capability, the decoder structure + language model task is the best; if multitask finetuning is also needed, the encoder-decoder structure + MLM task is the best.
In addition to finding the best training method, the authors, through extensive experiments, also found the most cost-effective training method. The training computation required is only one-ninth!
Paper Title: What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
Paper Link: https://arxiv.org/abs/2204.05832
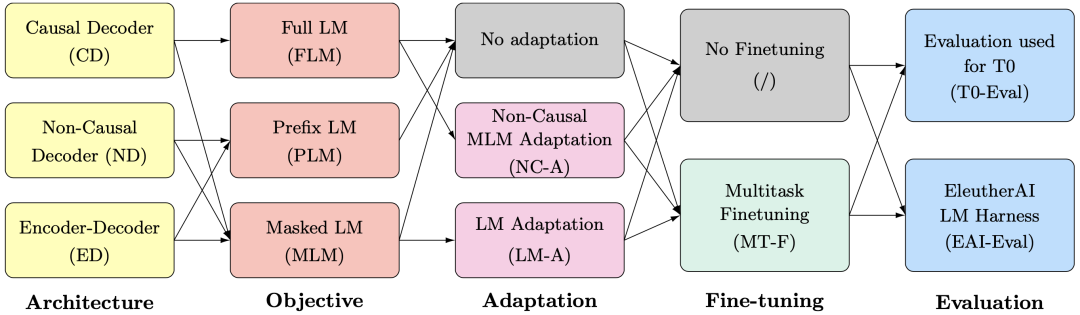
Model design can be divided into four aspects shown in the diagram: what structure to choose? What training objectives? Should adaptation be done? Multitask finetuning? The article also evaluated two benchmarks.
Model Structure
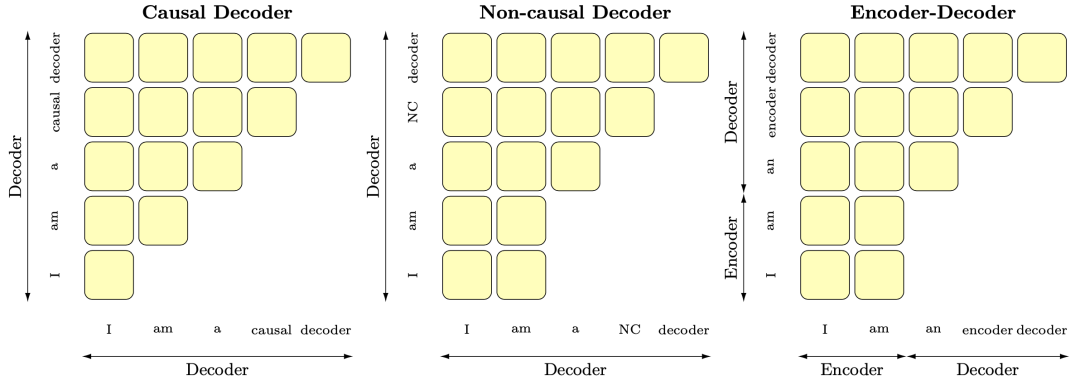
The model structures are all based on transformers, with three options, as shown in the diagram:
-
Causal decoder-only (CD): Directly using only the transformer decoder. These models mostly use the language model training objective, predicting the current token based on previous context. Representative works include the GPT series.
-
Non-causal decoder-only (ND): To allow generation based on given conditions, part of the previous tokens can be visible during training.
-
Encoder-decoder (ED): This is the original transformer structure, where an input sequence is processed by the encoder to output a vector representation of the same length, and the decoder generates conditionally autoregressive outputs based on the encoder’s output.
To summarize, CD uses only the decoder, ND is a prompt-enabled decoder, and ED is the encoder-decoder structure. Abbreviations will be used later.
Training Objectives
Corresponding to the model structures, there are also three types of training objectives:
-
Full language modeling (FLM): CD-type model architectures commonly use FLM, predicting the current token based on previous context. During training, each token’s loss can be computed in parallel, but predictions require iterative forecasting.
-
Prefix language modeling (PLM): ND-type and ED-type model architectures can use PLM. A prefix is defined in the attention matrix, and during training, the model is required to generate tokens following the prefix.
-
Masked language modeling (MLM): Models that only use the encoder commonly use the MLM objective. Later, in the T5 seq2seq model, a full-segment masked MLM task was also employed.
To summarize, FLM is the language modeling objective, PLM is the prompt-enabled language modeling objective, and MLM is the masking objective. Abbreviations will also be used later.
Adaptation Tasks
Adaptation tasks involve continuing training with a new training objective after pre-training. Unlike finetuning, the adaptation process does not use data from new downstream tasks but continues to use pre-training data. Adaptation tasks can also be divided into two categories.
-
Language modeling adaptation (LM-A): Pre-trained with MLM, followed by continued training with PLM or FLM. MLM + FLM is the method used in T5, while MLM + PLM refers to the previously popular continuous prompt-tuning methods, such as prefix-tuning, etc.
-
Non-causal MLM adaptation (NC-A): Pre-trained with PLM, followed by continued training with FLM. This method is proposed for the first time in this paper, fixing a portion of the prefix in front of the decoder and training with the PLM objective, effectively performing prefix-tuning on GPT.
Multitask Finetuning
Multitask finetuning (MT-F) is Hugging Face’s work from the end of last year [3], which involves taking a pre-trained model and simultaneously finetuning it on 171 tasks using prompts. This method can greatly enhance the zero-shot capability of the pre-trained model.
Experiments and Conclusions
Evaluation Tasks
This article used two benchmarks:
-
EleutherAI LM Evaluation Harness (EAI-Eval): This task is used to evaluate the zero-shot capability of language models (specifically, those using the FLM training objective in this paper).
-
T0 Test Set (T0-Eval): This is the test set previously used in Hugging Face’s multitask finetuning work.
Both test sets are tested using prompts, meaning prompts are directly constructed and input to the pre-trained model to generate predictions. The main difference between the two test sets is that EAI-Eval provides only one prompt for each task, which significantly affects evaluation due to prompt variability. Therefore, in this paper’s testing, the authors designed multiple prompts for each task to eliminate randomness.
Conclusions
Experiments yielded the following conclusions:
-
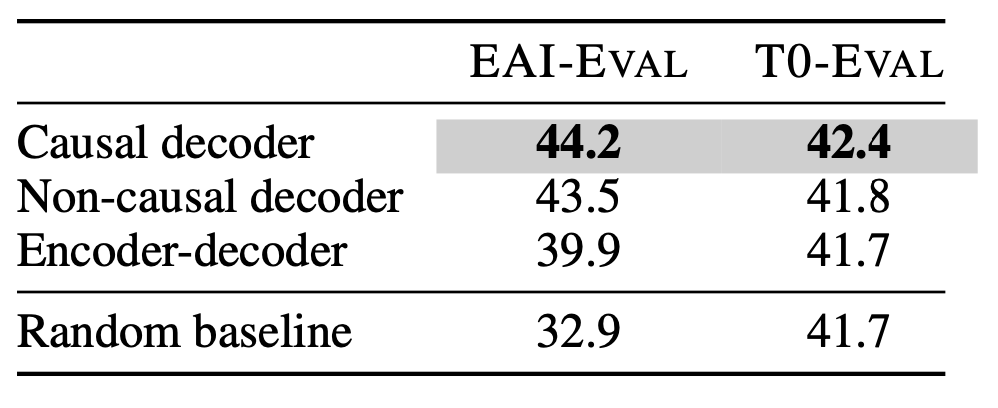
When only unsupervised pre-training is performed:
CD model structure + FLM training objective = the best model for zero-shot.
This aligns with the current large models, which all use this combination for the best zero-shot generalization capability.
-
When pre-training is followed by multitask finetuning:
ED model structure + MLM training objective = the best model for zero-shot.
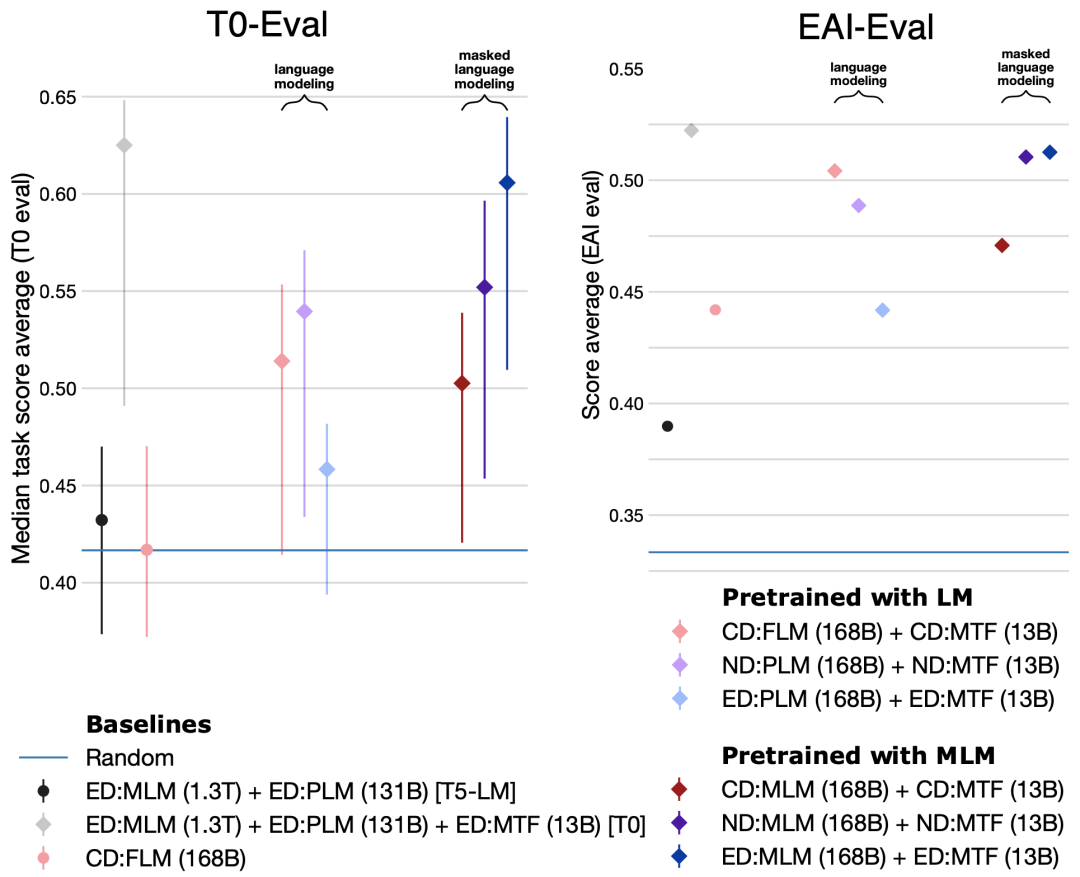
The left and right figures represent two evaluation sets. Each figure contains nine points, representing nine combinations of model architectures and training objectives. The results on the left T0-Eval are very clear: the nine combinations can be divided into three groups, with the left group being several baselines, the middle group being three model structures + language model training objectives, and the right group being three model structures + MLM training objectives. It is evident that the MLM training objective performs significantly better, with MLM + ED being the best.
-
The Role of Adaptation Tasks:
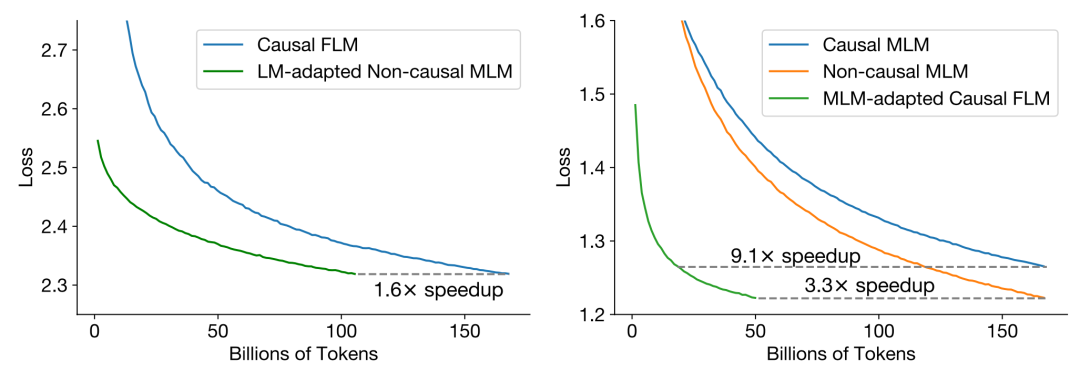
After pre-training, switching to a new training objective for continued training primarily reduces training costs. For instance, in the left image, if we want a combination of CD + FLM, we can first train an ND + MLM, then switch to CD + FLM for adaptation. This can accelerate the overall process by 1.6 times.
Through a series of experiments, the authors ultimately concluded that if one wants to build an effective large model at the lowest cost, the approach is to use CD + FLM for pre-training, then switch to ND + MLM for adaptation tasks, and finally employ multitask finetuning. This training method can speed up the process by 9.1 times compared to direct training while achieving the best results.
This article is very similar to T5, also utilizing a hyperparameter tuning approach in experimental design to ultimately find the best model design and training method. Reading this paper feels logically clear and rigorous.
However, from another perspective, such articles may seem somewhat dull: the use of large models has turned into feature engineering for finding prompts. The training and design in this paper have also become hyperparameter tuning, losing the spark of innovation. This could represent the internal competition in the field of large models.
[1] Aakanksha Chowdhery, et. al., “Palm: Scaling language modeling with pathways.”, https://arxiv.org/abs/2204.02311
[2]Jordan Hoffmann, et. al., “Training Compute-Optimal Large Language Models.”, https://arxiv.org/abs/2203.15556
[3]Victor Sanh, et. al., “Multitask Prompted Training Enables Zero-Shot Task Generalization”, https://arxiv.org/abs/2110.08207
Editor: Yu Tengkai