

Source: Dolphin Data Science Laboratory
This article is approximately 6000 words and is recommended for a 12-minute read.
This is a deep technical popular science and interpretation article, without excessive technical terms.

[ Introduction ] The author of this article is Dr. Chen Wei, who previously served as the chief scientist of a Huawei-affiliated natural language processing (NLP) company.
An expert in storage-compute integration/GPU architecture and AI, with senior professional titles. He is an expert in the Zhongguancun Cloud Computing Industry Alliance, a member of the Chinese Optical Engineering Society, a member of the International Computer Society (ACM), and a professional member of the China Computer Society (CCF). He has previously served as the chief scientist of an AI company and the head of 3D NAND design at a storage chip manufacturer. His major achievements include the first large-capacity reconfigurable storage-compute processor product architecture in the country (prototyped and internally tested at major internet companies), the first AI processor dedicated to the medical field (already applied), and the first AI accelerating compiler compatible with RISC-V/x86/ARM platforms (in collaboration with Alibaba’s Tianshu and Chiplet, already applied). He also established the first 3D NAND chip architecture and design team in the country (benchmarking with Samsung) and created the first embedded flash memory compiler in the country (benchmarking with TSMC, already applied at the platform level).
The key improvements of ChatGPT can be referenced in the paper: Augmenting Reinforcement Learning with Human Feedback.

Introduction
First, here are some reference webpages or papers. Professional readers can go directly to the paper.
On December 1, 2022, OpenAI launched the AI chat prototype ChatGPT, once again capturing attention and sparking discussions in the AI community similar to those about AIGC making artists unemployed.
Reportedly, within just a few days of its open trial, ChatGPT attracted over 1 million internet registered users. Various interesting dialogues querying or teasing ChatGPT circulated on social networks. Some even likened ChatGPT to a combination of a “search engine + social software,” capable of providing reasonable answers to questions during real-time interactions.
ChatGPT is a language model focused on dialogue generation. It can generate intelligent responses based on user text input. This response can be a short word or a lengthy discourse. GPT stands for Generative Pre-trained Transformer.
By learning from a large collection of existing texts and dialogues (e.g., Wiki), ChatGPT can converse instantaneously like a human, smoothly answering various questions (though its response speed is still slower than that of humans). Whether in English or other languages (such as Chinese, Korean, etc.), from answering historical questions to writing stories and even drafting business plans and industry analyses, it is “almost” omnipotent. Even programmers have posted dialogues where ChatGPT modifies code.
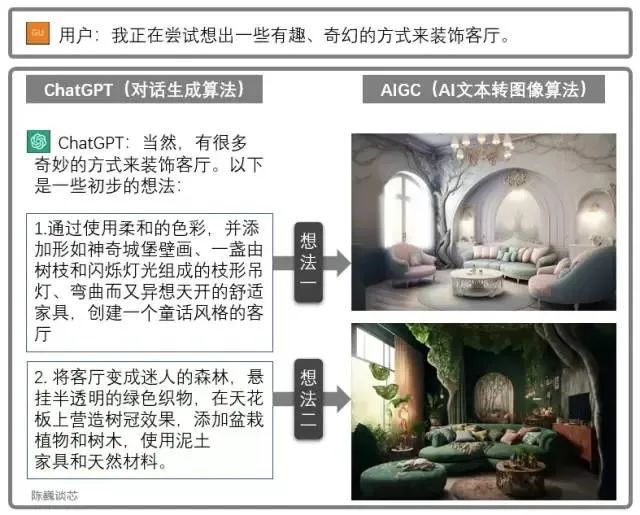
ChatGPT can also be used in conjunction with other AIGC models to obtain more impressive and practical features. For example, generating a living room design through dialogue. This greatly enhances the capability of AI applications to converse with clients, showing us the dawn of large-scale AI implementation.
1. Inheritance and Characteristics of ChatGPT

1.1 OpenAI Family
First, let’s understand who OpenAI is.
OpenAI is headquartered in San Francisco and was co-founded in 2015 by Tesla’s Elon Musk, Sam Altman, and other investors, with the goal of developing AI technology that benefits all humanity. Musk left the company in 2018 due to differences in the direction of company development.
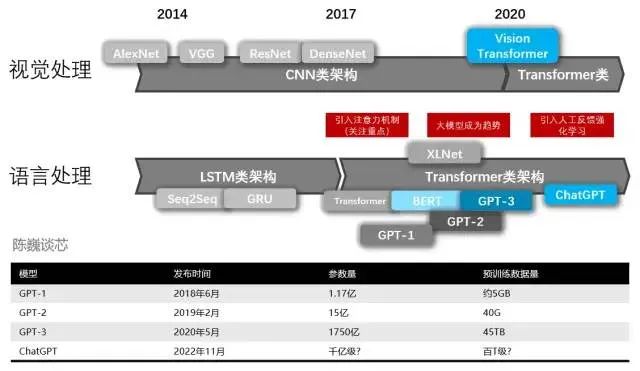
Previously, OpenAI was known for launching the GPT series of natural language processing models. Since 2018, OpenAI has begun releasing generative pre-trained language models (GPT) that can be used to generate articles, code, machine translations, Q&A, and various content.
Each generation of the GPT model has seen an explosive growth in the number of parameters, famously known as “the bigger, the better.” The GPT-2 released in February 2019 had 1.5 billion parameters, while GPT-3 released in May 2020 reached 175 billion parameters.

1.2 Main Features of ChatGPT
ChatGPT is a dialogue AI model developed based on the GPT-3.5 (Generative Pre-trained Transformer 3.5) architecture, and is a sibling model of InstructGPT. ChatGPT is likely a rehearsal by OpenAI before the official launch of GPT-4, or used to collect a large amount of dialogue data.
OpenAI trained ChatGPT using RLHF (Reinforcement Learning from Human Feedback) technology and added more human supervision for fine-tuning.
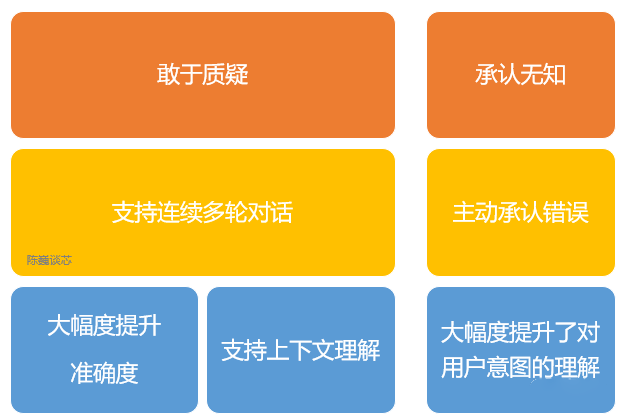
Additionally, ChatGPT has the following features:
1) It can proactively admit its mistakes. If a user points out its errors, the model listens to the feedback and optimizes its answer.
2) ChatGPT can question incorrect queries. For example, when asked about “Columbus arriving in America in 2015,” the robot will clarify that Columbus did not belong to that era and adjust the output accordingly.
3) ChatGPT can acknowledge its ignorance and admit its lack of knowledge about specialized techniques.
4) It supports continuous multi-turn dialogue.
Unlike the various smart speakers and “artificial intelligence idiots” we use in daily life, ChatGPT remembers previous users’ dialogue information during conversations, i.e., contextual understanding, to answer certain hypothetical questions. ChatGPT can achieve continuous dialogue, greatly enhancing the user experience in conversational interaction modes.
For accurate translation (especially for Chinese and name transliteration), ChatGPT still has a way to go to be perfect, but in terms of text fluency and recognition of specific names, it is comparable to other online translation tools.
Since ChatGPT is a large language model, it currently does not have internet search capabilities, so it can only answer based on the dataset it has from 2021. For example, it does not know about the 2022 World Cup or provide information like Apple’s Siri about today’s weather or help you search for information. If ChatGPT could browse the internet to find learning materials and search for knowledge, it would likely achieve even greater breakthroughs.
Even with limited knowledge, ChatGPT can still answer many quirky questions posed by imaginative humans. To prevent ChatGPT from developing bad habits, it uses algorithms to filter and reduce harmful and deceptive training inputs, querying through a moderate API and rejecting potential racist or sexist prompts.
2. Principles of ChatGPT/GPT
2.1 NLP
Known limitations in the NLP/NLU field include misunderstandings of repetitive texts, highly specialized topics, and contextual phrases.
Both humans and AI typically require years of training to converse properly. NLP models not only need to understand the meanings of words but also how to construct sentences and provide contextually meaningful responses, even using appropriate slang and technical jargon.
Essentially, the GPT-3 or GPT-3.5 that underpins ChatGPT is an enormous statistical language model or sequential text prediction model.
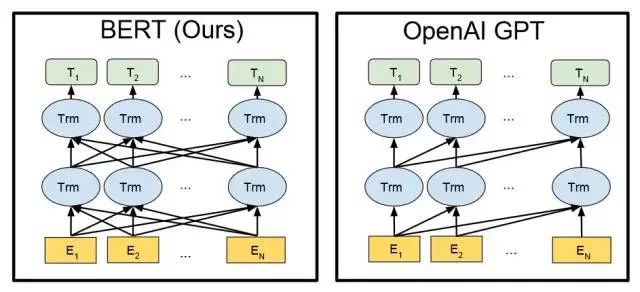
2.2 GPT vs. BERT
Similar to the BERT model, ChatGPT or GPT-3.5 automatically generates each word (or term) based on the input statement and the probability of language/corpus. From a mathematical or machine learning perspective, a language model is a modeling of the probability distribution of the correlation of word sequences, i.e., using previously spoken statements (which can be viewed as vectors in mathematics) as input conditions to predict the probability distribution of different statements or even language sets occurring at the next moment.
ChatGPT is trained using reinforcement learning from human feedback, which enhances machine learning through human intervention to achieve better results. During training, human trainers act as users and AI assistants and fine-tune through proximal policy optimization algorithms.
Due to ChatGPT’s stronger performance and massive parameters, it contains more thematic data and can handle more niche topics. ChatGPT can now further handle tasks such as answering questions, writing articles, summarizing texts, translating languages, and generating computer code.
3. Technical Architecture of ChatGPT
3.1 Evolution of the GPT Family
When talking about ChatGPT, one cannot help but mention the GPT family.
Before ChatGPT, there were several well-known siblings, including GPT-1, GPT-2, and GPT-3. Each of these siblings is larger than the last, with ChatGPT being most similar to GPT-3.
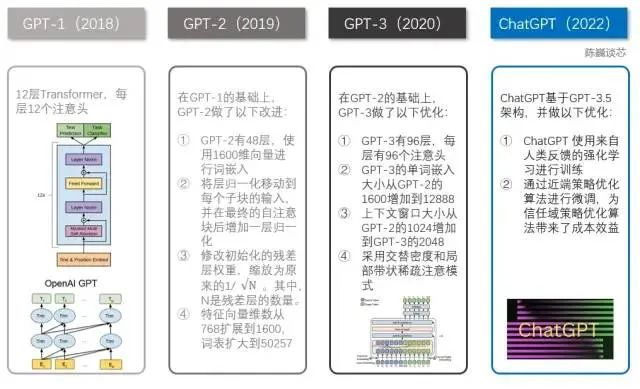
Both the GPT family and the BERT model are well-known NLP models based on Transformer technology. GPT-1 has only 12 Transformer layers, while GPT-3 has increased to 96 layers.
3.2 Reinforcement Learning from Human Feedback
The main difference between InstructGPT/GPT3.5 (the predecessor of ChatGPT) and GPT-3 is the introduction of a training paradigm called RLHF (Reinforcement Learning from Human Feedback). This training paradigm enhances human regulation of model output and provides a more understandable ranking of results.
In InstructGPT, the following are the evaluation criteria for the “goodness of sentences”:
-
Truthfulness: Is it false or misleading information?
-
Harmlessness: Does it cause physical or mental harm to people or the environment?
-
Usefulness: Does it solve the user’s task?
3.3 TAMER Framework
Here we must mention the TAMER (Training an Agent Manually via Evaluative Reinforcement) framework. This framework introduces human annotators into the learning loop of agents, allowing humans to provide reward feedback (i.e., guide agents in training), thereby quickly achieving training task goals.

The main purpose of introducing human annotators is to accelerate training speed. Although reinforcement learning techniques perform well in many areas, there are still many shortcomings, such as slow training convergence and high training costs. Particularly in the real world, the exploration cost or data acquisition cost of many tasks is very high. How to accelerate training efficiency is one of the important problems to be solved in current reinforcement learning tasks.
TAMER can train agents using the knowledge of human annotators in the form of reward feedback to accelerate rapid convergence. TAMER does not require annotators to have professional knowledge or programming skills, making the corpus cost lower. Through TAMER + RL (reinforcement learning), aided by feedback from human annotators, it can enhance the reinforcement learning (RL) process from the Markov Decision Process (MDP) rewards.
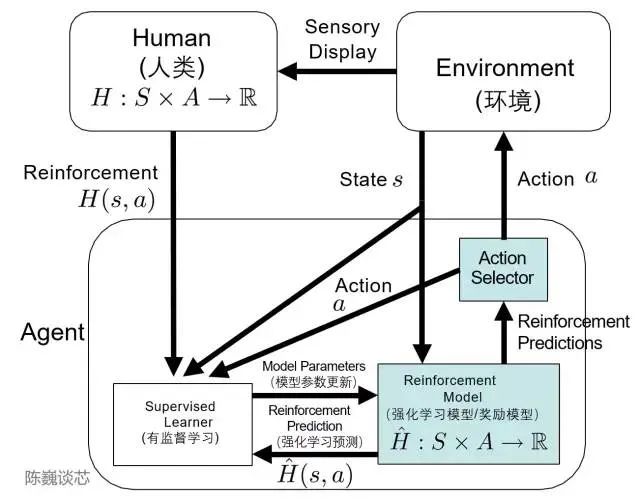
Specifically, human annotators act as users in dialogues with AI assistants, providing dialogue samples for the model to generate responses. The annotators then score and rank the response options, feeding back better results into the model. Agents learn from two feedback modes—human reinforcement and Markov Decision Process rewards—as an integrated system, fine-tuning the model through reward strategies and continuously iterating.
On this basis, ChatGPT can better understand and fulfill human language or instructions than GPT-3, imitating humans and providing coherent and logical textual information.
3.4 Training of ChatGPT
The training process of ChatGPT is divided into the following three stages:
First Stage: Training the Supervised Policy Model.
GPT 3.5 itself struggles to understand the different intentions embedded in various types of human instructions and to determine whether generated content is of high quality. To help GPT 3.5 preliminarily grasp the intent of instructions, a random selection of questions is extracted from the dataset, and human annotators provide high-quality answers, which are then used to fine-tune the GPT-3.5 model (resulting in the SFT model, Supervised Fine-Tuning).
At this point, the SFT model performs better than GPT-3 in following instructions/dialogues, but may not necessarily align with human preferences.
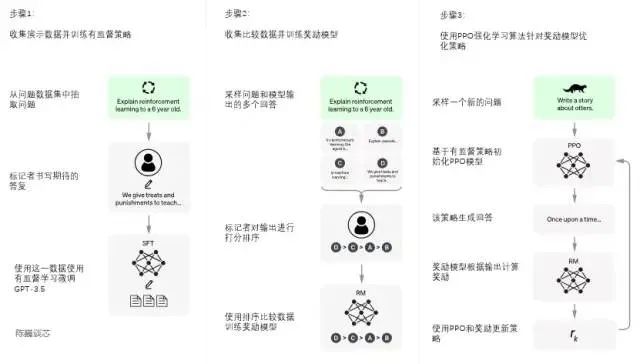
Second Stage: Training the Reward Model (RM).
This stage primarily involves training the reward model using manually annotated training data (approximately 33K data). A random selection of questions is extracted from the dataset, and the model generated in the first stage produces multiple different responses for each question. Human annotators consider these results comprehensively and provide a ranking order. This process is similar to coaching or teaching.
Next, this ranking result data is used to train the reward model. For multiple ranking results, pairs are formed to create multiple training data pairs. The RM model receives an input and gives a score evaluating the quality of the response. Thus, for a pair of training data, parameters are adjusted so that high-quality responses receive higher scores than low-quality ones.
Third Stage: Using Proximal Policy Optimization (PPO) Reinforcement Learning to Optimize Policies.
The core idea of PPO is to transform the On-policy training process in Policy Gradient into Off-policy, i.e., converting online learning into offline learning, a process known as Importance Sampling. This stage utilizes the reward model trained in the second stage to update the parameters of the pre-trained model based on reward scoring. A random selection of questions is extracted from the dataset, and the PPO model generates responses, with the quality scores provided by the RM model trained in the previous stage. The reward scores are sequentially passed, generating policy gradients to update the PPO model parameters through reinforcement learning.
If we continuously repeat the second and third stages through iteration, we will train a higher quality ChatGPT model.
4. Limitations of ChatGPT
Just because ChatGPT can answer questions upon user input, does that mean we no longer need to feed keywords to Google or Baidu to get immediate answers?
Despite ChatGPT demonstrating excellent contextual dialogue capabilities and even programming abilities, changing the public’s impression of chatbots from