
Abstract: Large Language Models (LLMs) are natural language processing technologies used to describe vast amounts of text through vector representations and generative probabilities. Recently, with the emergence of representative products like ChatGPT, which has garnered widespread attention in the education sector due to its excellent capabilities in generation, comprehension, logical reasoning, and dialogue, research on the educational applications of LLMs has entered the public eye. However, there is a lack of research on how to effectively utilize different technical routes of LLMs for teaching. This article focuses on the three main technical routes of LLMs: BERT, T5, and the GPT series. It first summarizes their technical principles, advantages, disadvantages, and application scenarios. It then outlines their applications in cultivating higher-order thinking, enhancing reading comprehension, and improving writing and mathematical problem-solving skills. Finally, it further discusses the current practical challenges of LLMs in education and future development suggestions, aiming to provide new ideas, methods, and sustainable development paths for intelligent teaching and digital transformation in education.
Keywords: ChatGPT; Large Language Model; Artificial Intelligence in Education; Digital Transformation in Education
// Introduction
Currently, artificial intelligence technologies such as natural language processing and computer vision are providing impetus for infrastructure upgrades, changes in learning methods, and the re-engineering of educational processes in the context of digital transformation in education[1]. Particularly in the field of natural language processing, with the introduction of transfer learning, large language models or pre-trained language models trained on large-scale corpora have continuously emerged. The recent appearance of ChatGPT and its dialogue system[2] has brought new opportunities for digital transformation in education. LLMs can effectively express vocabulary, syntax, and semantic features of language through deep neural network models, thus supporting personalized digital resource creation, human-machine collaborative learning, and competency-oriented educational evaluation.
Since 2018, LLMs have been widely applied in educational scenarios such as chatbots, online learning analytics, human-machine collaborative writing, and programming. However, there are common issues in the industry, including insufficient understanding of the characteristics of LLMs, unclear practical application effects, incomplete mastery of teaching support strategies, inadequate understanding of pathways to empower students’ core competencies, and insufficient awareness of the challenges and coping strategies they bring[3]. Therefore, this research analyzes the technical principles, advantages, disadvantages, and application scenarios of LLMs, based on which it lists typical educational application scenarios and discusses the challenges faced by LLMs in education and future development strategies, aiming to provide new ideas for empowering intelligent teaching and digital transformation in education.
// I. Technical Principles and Features of Large Language Models
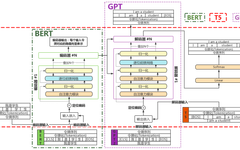
The development of natural language processing plays a key role in the intelligent development of education, and clarifying the technical principles, advantages, disadvantages, and application scenarios of LLMs is a prerequisite for implementing intelligent applications in education. At the level of technical principles, it is necessary to understand the essence, structure, and development context. LLMs essentially belong to deep neural networks, primarily extracting language features through self-supervised learning on large-scale text corpora and generating new text that conforms to language habits. Structurally, LLMs adopt the Transformer architecture, which has good transferability, and mainly consists of input embeddings, positional encodings, encoders, and decoders[4]. The encoder is composed of self-attention mechanisms and feed-forward neural network modules, while the decoder contains two self-attention mechanisms and one feed-forward neural network module; the modules are connected through normalization and residual connections. Additionally, the self-attention mechanism assigns weights to different parts of the input data related to each position in the language sequence, allowing the model to understand the relationships and dependencies between different parts of the input sequence. In terms of development context, before the emergence of large language models, the field of natural language processing mainly experienced three paradigms: rule-based, statistical machine learning, and deep learning. Since 2018, due to the introduction of Transformers, natural language processing has entered a new paradigm of “large language models or pre-trained models + fine-tuning/prompting”[5]. After five years of development, large language models based on Transformers have gradually formed three main technical routes: BERT, T5, and GPT series, with their main structures and operational processes (taking Chinese-English machine translation as an example) shown in Figure 1.

Figure 1. Main Structure and Operational Process of Transformer-based BERT/T5/GPT Series Large Language Models (Taking Chinese-English Machine Translation as an Example)
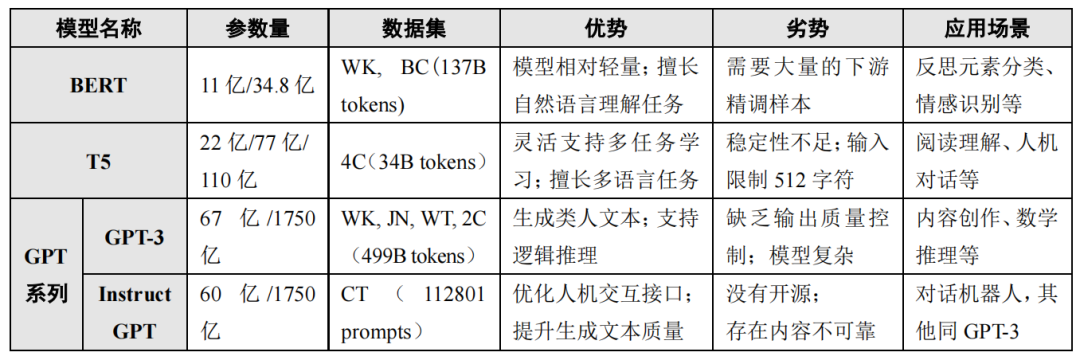
Various LLMs have different characteristics. Table 1 lists the basic information regarding the three main technical routes of LLMs in terms of parameter size, datasets1, model advantages and disadvantages, and application scenarios. Through literature comparison, this study further categorizes LLMs into lightweight, heavyweight, and ultra-heavyweight, and provides a brief explanation of the three main technical routes of LLMs based on their technical principles.
Table 1. Basic Characteristics of the Three Main Technical Routes of Large Language Models
1. Lightweight Open-source BERT
As shown in Figure 1, BERT is a bidirectional encoder based on Transformer, belonging to a typical self-encoding (Autoencoder, AE) language model. The BERT encoder reads the token sequence generated by adding start and end markers to the text sequence, randomly masks some words in the input sequence, and predicts the masked content based on the context, thus outputting the hidden vector representation corresponding to each token. Therefore, BERT excels in natural language understanding tasks and performs well in application scenarios such as classification of writing reflective elements and sentiment recognition in online discussions[6]. In terms of model parameters, BERT is relatively lightweight, has lower hardware requirements, and is suitable for personal research and development. For example, BERTBASE contains 1.1 billion parameters and uses 16 TPUs; BERTLARGE contains 3.48 billion parameters and uses 64 TPUs, taking about four days to complete training, with cloud computing rental costing approximately 50,000 RMB. Additionally, the pre-trained BERT model only requires one extra output layer, which can be fine-tuned based on new task-specific data, and its performance can be enhanced by adjusting hyperparameters, changing structures, or further fine-tuning, although this model still requires a significant amount of downstream fine-tuning samples.
2. Heavyweight Open-source T5
T5 is a general-purpose language model that adopts a Transformer-based “encoder-decoder” structure (as shown in Figure 1). In the input phase, the encoder directly reads the input text sequence to generate a token sequence, while the decoder reads the output text sequence and generates a token sequence after adding end markers; after processing by the encoder and decoder, the output is processed by Linear and Softmax functions to generate the target text with end markers. Therefore, the training task of T5 is essentially a “text-to-text” language transformation paradigm[7], which can flexibly support multi-task learning, but its stability is insufficient, and the input text sequence is limited to 512 characters. Meanwhile, the derived version, mT5, is a large language model trained on 75 languages[8], supporting multilingual tasks, which enables it to understand information more comprehensively compared to other models and can be applied in reading comprehension, human-machine dialogue, and other scenarios. In terms of model parameters, T5 includes T5BASE with 2.2 billion parameters, T5LARGE with 7.7 billion parameters, and the T5 model with 11 billion parameters, making it medium-sized in terms of parameter scale. However, T5 has higher training costs; for instance, the pre-training of the Danish T5 used four A100 graphics cards, costing approximately 900,000 RMB, making it more suitable for laboratories and small teams for model improvement and application development.
3. Ultra-heavyweight GPT Series
In terms of model structure, the GPT series is a typical autoregressive (AR) language model, as shown in Figure 1. It adopts a single decoder structure, where the decoder reads the text sequence and adds start and end markers to generate a token sequence, subsequently outputting the target text with end markers. The causal masking attention mechanism of this model allocates attention weights to the words to the left of the predicted words, thereby achieving text prediction[9], which has led to the advantages of the GPT series in content creation, code generation, and other natural language generation tasks[10].
Currently, due to the significant difficulty and high cost of fine-tuning tasks with GPT-2, the field of natural language processing has begun to shift towards the “pre-training + prompting” paradigm represented by GPT-3[11]. This paradigm is characterized by in-context learning, requiring only the introduction of prompts or the addition of one or more training samples based on the prompts[12], allowing original downstream tasks to be transformed into pre-training stage model tasks. Furthermore, with the support of chain-of-thought techniques, it can quickly fit on limited data, enhancing the credibility of conventional human-like text generation results while also improving the model’s generalization ability on atypical mathematical reasoning tasks[13].
However, due to the significant differences between the tasks of pre-trained language models and downstream tasks, there may still be poor content generation effects (e.g., fabricating facts, generating biased or harmful information), leading to the emergence of a new paradigm of “pre-training + pre-fine-tuning + prompting,” resulting in the development of large language models represented by InstructGPT and ChatGPT[14]. In the “pre-fine-tuning” phase, these models must undergo reinforcement learning with human feedback for training, enhancing the quality of content generation. Compared to InstructGPT, ChatGPT is trained using a multi-turn dialogue learning approach, constructing a dialogue history model that improves the model’s dialogue generation capability and fluency.
In summary, the GPT series large language models can be applied in content creation, mathematical reasoning, and chatbots. However, models like GPT-3 and its successors remain complex and closed-source, with parameters reaching 175 billion. Variants like Codex, which have undergone extensive code fine-tuning, also reach 12 billion parameters, resulting in extremely high reproduction and research and development costs (the cost of a single pre-training of GPT-3 is approximately 9.8 million RMB[15]), making them suitable only for medium to large companies and government organizations for R&D.
// II. Educational Application Scenarios of Large Language Models
Utilizing the technical principles and features of LLMs, researchers have applied them to the education sector with certain results. Next, this study presents the application status of LLMs from three scenarios: empowering higher-order thinking, enhancing reading comprehension, and improving writing and problem-solving skills.
1. Online Discussion and Reflective Learning Scenario: Empowering Higher-order Thinking Skills
Text data in online discussion and reflective learning scenarios reflect students’ cognitive and emotional expressions during online learning to some extent. BERT, with its advantages in natural language understanding, can identify cognitive and emotional aspects in students’ text data, laying the foundation for empowering students’ higher-order thinking skills. Thus, from a macro perspective of cognitive and emotional recognition, Liu et al.[16] constructed the LLM classifier BERT-CNN to automatically detect students’ emotions and cognitive engagement in online discussions, exploring the developmental patterns of students’ cognitive and emotional growth in online learning.
Additionally, some researchers have further improved the application scheme for cultivating students’ higher-order thinking skills based on identifying more micro cognitive dimensions such as critical thinking and reflection. For instance, in the aspect of cultivating critical thinking skills, Wambsganss et al.[17] developed an adaptive dialogue learning system called ArgueTutor, which can automatically identify argument elements such as claims and premises based on an improved BERT classifier. Practical applications have shown that ArgueTutor effectively promotes students’ argumentative writing and critical thinking skills. In the aspect of cultivating reflective skills, Wulff et al.[18] proposed using the German BERT language model to classify pre-service physics teachers’ reflective writing, including five reflective elements: context, description, evaluation, alternatives, and consequences. Furthermore, some researchers have expanded intelligent collaborative feedback solutions based on the classification of reflective text elements. For example, Lin Yupeng[19] utilized the Chinese BERT language model to construct an improved Chinese reflective element classifier MacBERT_RCNN, which can identify seven reflective elements: experiences, emotions, beliefs, perspectives, difficulties, learning gains, and plans. Based on the intelligent identification of reflective elements in writing, researchers collaborated with frontline teachers to design feedback templates, creating an intelligent feedback system to support personalized reflective writing and cultivate students’ reflective skills[20][21]. For instance, Figure 2 shows the interface of the intelligent reflective writing system based on the MacBERT_RCNN model. This system can leverage the advantages of LLMs in text comprehension to identify cognitive and emotional patterns in students’ online discussions and reflective activities, even constructing an intelligent learning feedback system to provide technical support for cultivating students’ higher-order thinking skills. However, in this scenario, there may be a risk of students overly relying on intelligent feedback, leading to learning inertia and weakening of higher-order thinking skills.
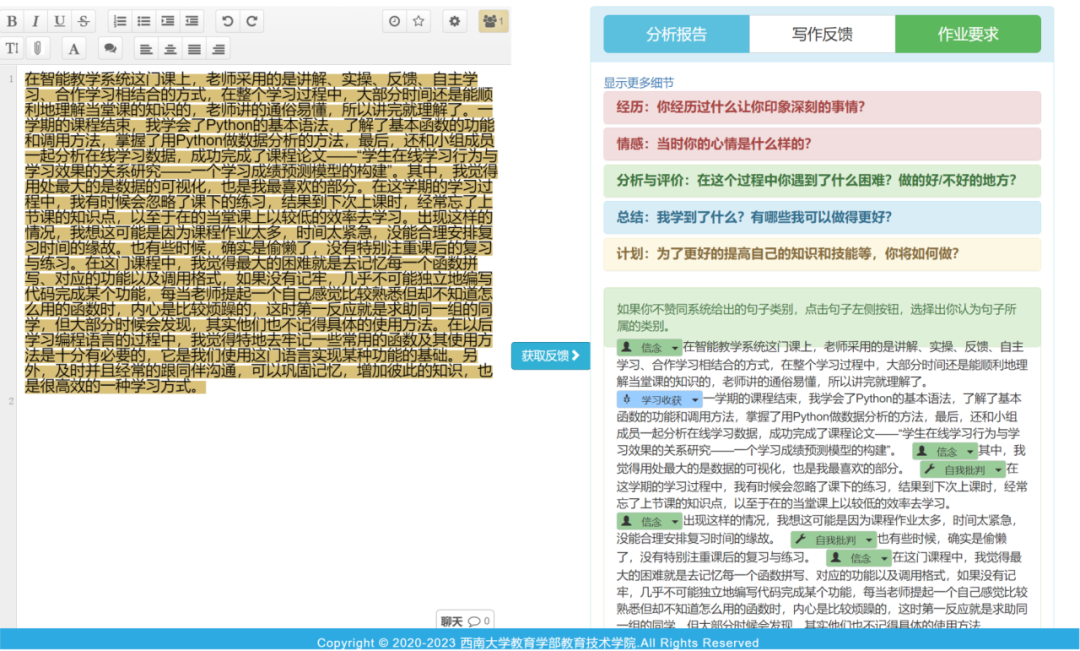
Figure 2. Interface of the Intelligent Reflective Writing System Based on the MacBERT_RCNN Model[22]
2. Human-Machine Collaborative Questioning Scenario: Enhancing Reading Comprehension Skills
Self-questioning can enhance learning focus and deepen understanding of reading content, but current student questioning generally suffers from low levels and limited types[23]. In response, the natural language generation advantages of T5 and GPT series can support the creation of high-quality questions, thereby enhancing students’ reading comprehension skills. Currently, some researchers have constructed human-machine collaborative questioning tools that support both Chinese and English, providing intelligent support for enhancing students’ reading comprehension skills[24]. Our research team utilized the large language model T5-PEGASU to develop a student-AI co-creation questioning tool called Co-Asker, aimed at increasing students’ questioning enthusiasm and enhancing their reading comprehension skills. This model was fine-tuned on Chinese reading comprehension datasets and medical Q&A corpora, capable of automatically generating questions based on question cues and answers. Figure 3 shows the interface of the Co-Asker tool. Our research team applied this tool in a general education course on “Learning Analytics” at S University in Chongqing, involving 55 second-year education students. Each student was required to read four academic papers in the field of educational big data over the course of a week on an online reading platform and pose questions based on the content of the papers. Students were randomly assigned to an experimental group (using Co-Asker to assist question generation) and a control group (students independently creating questions). After three weeks of online reading study, the research results indicated that Co-Asker could generate high-quality human-like questions, stimulating students’ interest and engagement in questioning and deepening their understanding of superficial reading content. However, since the training dataset primarily consists of factual questions, this tool struggles to generate high-order complex questions. The study also found that completing a single training of the T5-PEGASU model took a long time and incurred high costs; for instance, under the use of a single NVIDIA GeForce RTX 3080Ti graphics card, a single training session would take about a week.
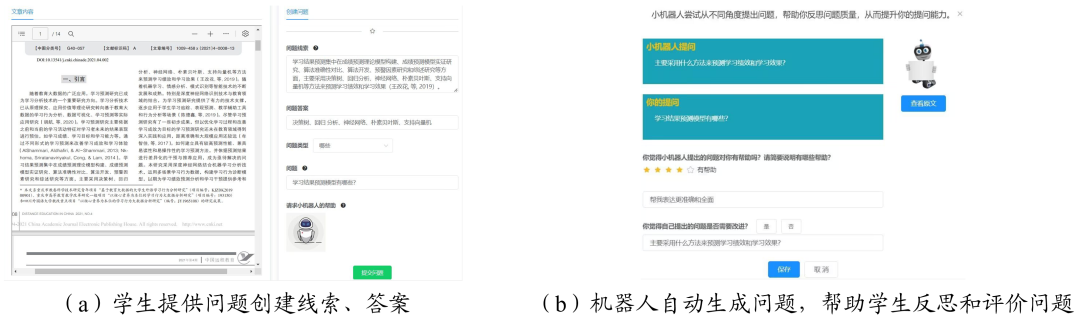
Figure 3. Interface of the Co-Asker Tool
Mastering superficial questions only indicates that students have remembered and understood the knowledge point, while proposing deeper questions is a process for students to establish new concepts and associate them with prior knowledge, which is also a cognitive behavior with creative characteristics. To this end, Abdelghani et al.[25] constructed a human-machine dialogue system called KidsAsk, which supports reading comprehension teaching. It utilizes GPT-3 to automatically generate prompts (including question types, answers, and question perspectives) and helps students pose deeper questions through multi-turn human-machine dialogues. Furthermore, this study conducted reading comprehension questioning teaching experiments with 75 students aged 9 to 10, finding that compared to rule-based human-machine dialogue generation, GPT-3 more effectively prompted elementary students to pose a series of deeper questions related to knowledge points, thereby enhancing deep reading comprehension. In summary, LLMs can leverage their text generation advantages to assist students in questioning through human-machine collaborative dialogue, thereby improving their reading comprehension skills. However, in these application scenarios, there remain practical issues such as the expensive software and hardware investment required for customized development of LLMs and the long model training times.
3. Human-Machine Collaborative Writing and Mathematical Problem-Solving Scenario: Enhancing Writing and Problem-Solving Skills
Teaching logic in writing and mathematical problem-solving has always been challenging in the field of subject education, with students often facing issues like “unwillingness to write,” “lack of content,” and “inability to write” and encountering non-standard answers in mathematical problem-solving, with traditional teaching guidance being inefficient. In response, the GPT series or T5-like structured models, due to their advantages in content creation and mathematical reasoning, can be widely applied in intelligent writing tool research and mathematical problem-solving assistance research, effectively enhancing students’ writing and mathematical problem-solving skills. Currently, relevant research mainly involves three aspects: language teaching applications, evaluation of human-machine collaborative writing quality, and effectiveness of mathematical teaching assistance:
1. LLMs have clear advantages in language teaching applications. For instance, Gayed et al.[26] utilized GPT-2 to construct an English writing assistance program called AI KAKU to reduce cognitive barriers for students writing in a second language. This study found through comparative experiments that students in the experimental group using AI KAKU were able to write smoother sentences, richer content, and exhibited stronger language communication skills.
2. Research on the evaluation of human-machine collaborative writing quality mainly focuses on argumentative, creative, and critical writing styles. For argumentative writing, Bao et al.[27] utilized the large language model BART to automatically generate strong argumentative essays based on writing prompts. This model employs an “encoder-dual-decoder” architecture, where the encoder encodes the writing prompts, and the two decoders generate the “planning” and “writing” sequences, achieving end-to-end argumentative essay generation. It was fine-tuned on large news datasets CNN-DailyMail and ArgEssay, measuring the model’s effectiveness through both automatic and manual evaluations. Automatic evaluations include diversity, novelty, repetitiveness, and BLEU scores; manual evaluations primarily assess the relevance of generated articles to themes, coherence of the articles, and richness of arguments. Research results indicate that this model can generate argumentative essays on different topics with good readability and fluency. Additionally, Lee et al.[28] explored the ability of GPT-3 to assist students in creative and critical writing. This study used the online writing platform CoAuthor, inviting 63 students to collaborate with four GPT-3 models, generating a total of 1,445 articles. Figure 4 illustrates the process of human-machine collaborative writing integrated with GPT-3: first, students write a draft based on prompts; then, the large language model provides various writing suggestions based on the draft content; finally, students modify the article content (text highlighted in blue in the figure is generated by the large language model, while the rest is written by students). Interview results indicate that students recognize GPT-3’s writing generation capabilities, including language ability (the ability to generate fluent text), creative ability (the ability to generate new ideas), and collaborative ability (the ability to work together with the author), while human-machine collaboration based on large language models effectively enhances writing efficiency.
3. LLMs can also assist in mathematics teaching. For example, Pardos et al.[29] constructed an intelligent mathematics learning system based on ChatGPT, generating algebra problem-solving prompts to help students reflect and correct errors (as shown in Figure 5). The study conducted algebra problem-solving experiments with 77 high school graduates, finding that the system generated 70% acceptable prompts, improving students’ algebra learning outcomes. In summary, LLMs, leveraging their content creation and mathematical reasoning advantages, can provide intelligent support for enhancing writing and mathematical problem-solving skills. However, when students misuse intelligent writing or mathematical problem-solving tools, ethical risks such as academic dishonesty and copyright disputes may arise.

Figure 4. Process of Human-Machine Collaborative Writing Integrated with GPT-3[30]

Figure 5. Algebra Problem-Solving Prompts Generated Based on ChatGPT[31]
// III. Challenges and Coping Strategies for Educational Applications of Large Language Models
Although LLMs have been widely applied in the education sector, there are corresponding challenges, such as high training costs of LLMs in education, excessive reliance of teachers and students on problem-solving, writing text, and teaching content generation, as well as ethical and intellectual property disputes over generated content. Future practices still need to adopt educational evaluation reforms, collaboration among government, academia, and enterprises, and diversified collaborative governance to address these challenges.
1. Excessive Reliance on Large Language Models by Teachers and Students, Educational Evaluation Methods Need Reform
While LLMs simplify the process for teachers and students to access information, they also amplify their inertia in knowledge exploration. LLMs possess intelligent feedback, writing content creation, and mathematical reasoning capabilities, and excessive reliance on intelligent tools by students can lead to a lack of active thinking, weakening their knowledge mastery and problem-solving abilities, and even cheating phenomena; simultaneously, LLMs can assist teachers in generating lesson plans, constructing personalized learning resources, and grading assignments[32], but excessive reliance on LLMs by teachers may hinder their professional growth in areas such as professional knowledge and teaching creativity, as teachers still need their own wisdom when designing courses aimed at cultivating higher-order thinking skills.
The emergence of these phenomena stems from the inadequate implementation of the new educational evaluation concept that is based on knowledge and competencies. To address this, breakthroughs should be made in learning task design, learning process evaluation, assignment product evaluation, and teacher evaluation: 1) In terms of learning task design, content should be more competency and skill-oriented, culturally and open-ended, and critical and reflective. For example, learning objectives should be set based on core competencies and social needs, open-ended problem situations should be established based on real social and cultural backgrounds, and learning materials or task steps should be designed with questions, conflicts, and gaps within the students’ “zone of proximal development”. 2) In terms of learning process evaluation, forms should be more intelligent. For instance, learning analytics can assist teachers in monitoring students’ learning behaviors, and periodic student reflection logs can help teachers understand students’ learning thought processes. 3) In terms of assignment product evaluation, it should be more dynamic, creative, and realistic. For instance, consider the degree of contribution of content during the human-machine co-creation process, the degree of creative processing and critical transformation of existing knowledge materials, and the degree of alignment with social issues. 4) New teacher evaluations should pay more attention to the intrinsic relationship between “teacher-technology-teaching practice”. For instance, focus on teachers’ awareness, ability, and effectiveness in using LLMs to improve teaching practices, promoting the transition of teacher capability evaluation towards digital competency evaluation[33].
2. High Training Costs for Large Language Models in Education, Urgent Need for Strengthened Collaboration among Government, Academia, and Enterprises
Currently, the increasing scale of training datasets and the demand for computational power have raised the costs of artificial intelligence development. The sensitivity and diversity of educational data, the complexity of understanding educational concepts and teaching methods, and the difficulty in obtaining and annotating high-quality educational data necessitate higher investments for developing LLMs in education. According to professional institutions, the minimum cost of a single training of GPT-3, which uses general data, is about 10 million RMB[34]; OpenAI plans to invest about 35 billion RMB in model training by 2030. It can be seen that the “bottomless pit” of capital investment, the massive amount of data integration, and the complexity of downstream task design make it a “luxury” for ordinary schools to independently develop large language models for the education sector.
The “government-academia-industry” collaborative model provides a new idea for schools to develop LLMs in the education sector. For example, the Connected Intelligence Centre at the University of Technology Sydney has established a dedicated institution to integrate intelligent education products or self-developed intelligent educational tools (such as AcaWriter[35]) into its curriculum, serving the school’s digital transformation, and promoting sharing and dissemination through the Australian Technology Network Alliance established with government support. In China, technology companies like Baidu, Alibaba, and iFlytek have already made technological layouts in the field of LLMs. Therefore, universities should leverage their educational big data resources and application demonstration advantages in collaboration with technology companies to achieve educational application demonstrations of LLMs, intellectual property implementation, and sustainable commercial promotion in scenarios such as personalized learning, intelligent teaching evaluation, and digital management. The government can link enterprises and leading universities to establish an LLM (artificial intelligence) application alliance, constructing a co-creation mechanism for domain knowledge, technology, tools, and practice, as well as an application sharing platform; it can also utilize policies for digital transformation, legal regulation, and foundational funding support to ensure the healthy and stable development of LLMs in the education sector.
3. Ethical and Copyright Issues Highlighted, Urgent Need for Collaborative Governance
The United Nations Educational, Scientific and Cultural Organization (UNESCO) released the “Education 2030 Framework for Action,” pointing out the unfair phenomenon of artificial intelligence applications in education and proposing initiatives to promote fairness in the application of artificial intelligence in education[36]. However, the diversification of the Internet user base and the non-standardization of user behavior constraints may lead to harmful factors such as cognitive conflicts and racial, gender, and regional discrimination arising from cultural differences in the large-scale training data sourced from the Internet, resulting in biases and unfairness in the text generated by LLMs, which in turn negatively impacts their educational application process[37]. On the other hand, due to the openness of data sources, there is a high likelihood of original data content being reproduced during text generation tasks, leading to potential intellectual property disputes. Some legal scholars have even raised the critical question of “who owns the copyright of content generated by ChatGPT (large language models)?”
The existence of these three types of issues can be attributed to data regulation, legal protection, and subject awareness. Therefore, in terms of data regulation, it is necessary to maximize the standardization and reliability of data through professional training for data collection and annotation personnel, strict supervision of the collection and annotation processes, and validation steps tested on diverse populations. At the same time, it is essential to effectively utilize human feedback reinforcement learning techniques, treating teachers and students as participants in the construction of artificial intelligence during human-machine collaborative teaching processes[38], continuously refining the quality of LLMs with high-quality evaluation data. In terms of legal protection, experts from multiple fields such as law, intelligent education, and artificial intelligence should collaborate to discuss copyright policies, legal norms, academic ethics, and moral standards for AI-generated content. For instance, recently, the National Internet Information Office, in conjunction with six departments, formulated the “Interim Measures for the Management of Generative Artificial Intelligence Services”[39]. On this basis, it is also crucial to strengthen the ethical and copyright literacy of teachers and students in applying LLMs, establishing rigorous and open norms for human-machine collaborative educational applications, providing regulatory and moral dual guarantees for cultivating core competencies through artificial intelligence.
// IV. Conclusion
In the current era of digital transformation in education, propelled by the trend of technological advancement, this study explores the application layout of LLMs in empowering higher-order thinking, enhancing reading comprehension, and improving writing and problem-solving skills, based on the technical principles, advantages, disadvantages, and application scenarios of LLMs, and proposes coping strategies for the challenges encountered in practical educational applications, aiming to provide suggestions and countermeasures for the empowerment of education by the new generation of artificial intelligence and its governance. Currently, LLMs represented by ChatGPT have opened the door to general artificial intelligence. In the future, based on LLMs, integrating multimodal data such as online discussion texts, classroom teaching videos, and voice, through the “pre-training + pre-fine-tuning + prompting” paradigm, it will be possible to rapidly customize and develop highly precise and interpretable analytical tools for students’ cognitive, emotional, and personality traits, empowering the evaluation and cultivation of students’ holistic development. Additionally, humanoid educational robots will connect with LLMs to interact with classroom teaching environments, expanding their embodied intelligent capabilities such as perception, computation, reasoning, interaction, and control, forming a new type of “human teacher + machine teacher” classroom that will bring new opportunities and challenges for teaching, research, and school governance. Therefore, in this era dominated by general intelligent technologies represented by LLMs, the education sector should prioritize teachers and students, embrace technology with a more open attitude, continuously explore new human-machine collaborative teaching models, establish a new educational value system from the perspective of general artificial intelligence, construct new educational governance norms and models, and based on this, form an open educational LLM development and application system. At the same time, it is essential to avoid the alienation and deviation risks that may arise from the application of LLMs in education, promoting the sustainable development of digital transformation in education.
1. This section uses characters to represent the corresponding datasets and corpora: WK represents the English Wikipedia corpus, BC represents the BooksCorpus dataset, 2C represents the filtered Common Crawl dataset by OpenAI, 4C represents the filtered Common Crawl dataset by the T5 team, JN represents magazines such as Gutenberg, Smashwords, and ArXiv, WT represents the WebText dataset, and CT represents the dialogue and feedback dataset between researchers, users, and AI.
References
[1] Shang Junjie, Li Xiuhan. Difficulties and Coping Strategies in the Digital Transformation of Education [J]. Journal of East China Normal University (Education Science Edition), 2023, (3): 72-81.
[2][13] OpenAI. ChatGPT: Optimizing language models for dialogue [OL].<https://openai.com/blog/chatgpt>
[3] Jiao Jianli. ChatGPT: Friend or Foe of School Education? [J]. Modern Educational Technology, 2023, (4): 5-15.
[4] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [A]. Proceedings of the 31st International Conference on Neural Information Processing Systems [C]. NY, USA: Curran Associates Inc., 2017:6000-6010.
[5][6][7][8][9][11][12][14] Wu T, He S, Liu J, et al. A brief overview of ChatGPT: The history, status quo and potential future development [J]. IEEE/CAA Journal of Automatica Sinica, 2023, (5): 1122-1136.
[10] Floridi L, Chiriatti M. GPT-3: Its nature, scope, limits, and consequences [J]. Minds and Machines, 2020, (2): 681-694.
[15][34] Liu Gaochang, Yang Ran. Computing: How much computing power does ChatGPT need [OL].<https://research.gszq.com/research/report?rid=8ae505848630485f018643736cca53e2>
[16] Liu S, Liu S, Liu Z, et al. Automated detection of emotional and cognitive engagement in MOOC discussions to predict learning achievement [J]. Computers & Education, 2022, 181: 104461.
[17] Wambsganß T, Kueng T, Söllner M, et al. ArgueTutor: An adaptive dialog-based learning system for argumentation skills [A]. Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems [C]. New York, USA: Association for Computing Machinery, 2021: 1-13.
[18] Wulff P, Mientus L, Nowak A, et al. Utilizing a pretrained language model (BERT) to classify preservice physics teachers’ written reflections [J]. International Journal of Artificial Intelligence in Education, 2022: 1-28.
[19][22] Lin Yupeng. Design and Implementation of an Automated Classification System for Reflective Text Based on MacBERT_RCNN [D]. Chongqing: Southwest University, 2022: 8, 43.
[20] Zhang Dengbo, Liu Ming. Design and Application of an Intelligent Reflective Writing Feedback System [J]. Modern Educational Technology, 2021, (11): 96-103.
[21] Liu M, Shum S B, Mantzourani E, et al. Evaluating machine learning approaches to classify pharmacy students’ reflective statements [A]. International Conference on Artificial Intelligence in Education [C]. Chicago: Springer International Publishing, 2019: 220-230.
[23] Kurdi G, Leo J, Parsia B, et al. A systematic review of automatic question generation for educational purposes [J]. International Journal of Artificial Intelligence in Education, 2020, (30): 121-204.
[24] Liu Ming, Zhang Jinxu, Wu Zhongming. Intelligent Questioning Technology and Its Educational Applications [J]. Artificial Intelligence, 2022, (2): 30-38.
[25] Abdelghani R, Wang Y H, Yuan X, et al. GPT-3-driven pedagogical agents for training children’s curious question-asking skills [OL].<https://arxiv.org/abs/2211.14228>
[26] Gayed J M, Carlon M K J, Oriola A M, et al. Exploring an AI-based writing assistant’s impact on English language learners [J]. Computers and Education: Artificial Intelligence, 2022, 3: 100055.
[27] Bao J, Wang Y, Li Y, et al. AEG: Argumentative essay generation via a dual-decoder model with content planning [A]. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing [C]. Abu Dhabi: Association for Computational Linguistics, 2022: 5134-5148.
[28][30] Lee M, Liang P, Yang Q. CoAuthor: Designing a human-ai collaborative writing dataset for exploring language model capabilities [A]. Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems [C]. New York: Association for Computing Machinery, 2022: 1-19.
[29][31] Pardos Z A, Bhandari S. Learning gain differences between ChatGPT and human tutor generated algebra hints [OL].<https//doi.org/10.48550/arXiv.2302.06871>
[32] Wu Junqi, Wu Feiyan, Wen Sijiao, et al. Empowering Teacher Professional Development with ChatGPT: Opportunities, Challenges, and Pathways [J]. China Educational Technology, 2023, (5): 15-23.
[33] Zhao Jian. Teacher Burden in the Technological Age: A New Perspective on Understanding Educational Digital Transformation [J]. Educational Research, 2021, (11): 151-159.
[35] Lucas C, Shum S B, Liu M, et al. Implementing a novel software program to support pharmacy students’ reflective practice in scientific research [J]. American Journal of Pharmaceutical Education, 2021, (10): 1021-1030.
[36] UNESCO. Artificial intelligence in education [OL].<https://www.unesco.org/en/digital-education/artificial-intelligence>
[37] Kasneci E, Seßler K, Küchemann S, et al. ChatGPT for good? On opportunities and challenges of large language models for education [J]. Learning and Individual Differences, 2023, 103: 102274.
[38] Xia Qi, Cheng Miaoting, Xue Xiangzhong, et al. Perspectives on Effectively Integrating ChatGPT into Education from an International Viewpoint: A Systematic Review of 72 Articles [J]. Modern Educational Technology, 2023, (6): 26-33.
[39] National Internet Information Office. Interim Measures for the Management of Generative Artificial Intelligence Services [OL].<https://www.gov.cn/zhengce/zhengceku/202307/content_6891752.htm>
This chapter is cited from: Liu Ming, Wu Zhongming, Liao Jian, Ren Yiling, Su Yifei. Educational Applications of Large Language Models: Principles, Status, and Challenges*—From Lightweight BERT to Conversational ChatGPT [J]. Modern Educational Technology, 2023, 33(08): 19-28.
