
Large Language Models (LLMs) are a type of artificial intelligence model designed to understand and generate human language. They are trained on vast amounts of text data and can perform a wide range of tasks, including text summarization, translation, sentiment analysis, and more. LLMs are characterized by their large scale, containing billions of parameters, which help them learn complex patterns in language data. These models are typically based on deep learning architectures such as transformers, enabling them to achieve impressive performance across various Natural Language Processing (NLP) tasks.
At the end of 2022, OpenAI launched ChatGPT, a large language model based on GPT-3.5, which quickly became a hot topic in the field of artificial intelligence due to its outstanding performance, attracting the attention and participation of many researchers and developers.
This week, we have selected 10 outstanding papers in the field of LLMs, from institutions such as Meta AI, Zhejiang University, Tsinghua University, and ETH Zurich.
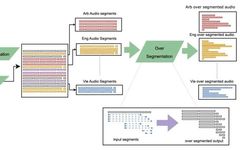
This paper introduces a large-scale multilingual and multimodal machine translation model called SeamlessM4T, which helps individuals translate speech between up to 100 languages. Although recent text-based models have achieved translation coverage for over 200 languages, a unified speech-to-speech translation model has not made similar progress. To address this issue, the authors propose a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition. They used 1 million hours of open speech audio data to learn self-supervised speech representations and created a multimodal auto-aligned speech translation corpus. By filtering and human annotation, as well as pseudo-label data, they developed the first multilingual system capable of translating to and from English in both speech and text. In the FLEURS evaluation, SeamlessM4T achieved a 20% improvement in BLEU score for direct speech-to-text translation compared to previous best levels. Compared to powerful cascade models, SeamlessM4T improved by 1.3 BLEU points in speech-to-text translation and 2.6 ASR-BLEU points in speech-to-speech translation. Robustness tests showed that the system performed better in speech-to-text tasks with background noise and speaker variation. The authors also evaluated the translation safety of SeamlessM4T concerning gender bias and added toxicity. Finally, they open-sourced all contributions on GitHub for more people to learn and use.
Link: https://www.aminer.cn/pub/64e5849c3fda6d7f063af4d6
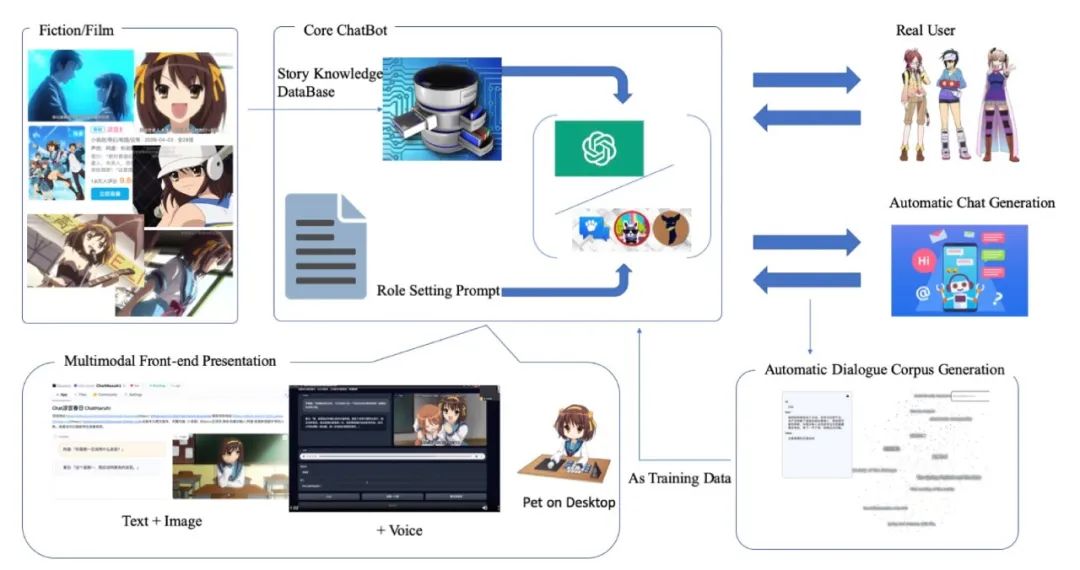
This paper presents a method to revive animated characters using large language models. Although character role-playing chatbots based on large language models have gained attention, better techniques are needed to mimic specific fictional characters. The paper proposes an algorithm to control the language model through improved prompts and character memory extracted from scripts. The authors constructed a dataset named ChatHaruhi, covering 32 Chinese and English TV drama and animation characters, with over 54,000 simulated dialogues. Both automatic and human evaluations showed that this method significantly improved role-playing capabilities compared to baseline methods.
Link: https://www.aminer.cn/pub/64e2e15a3fda6d7f06466a72
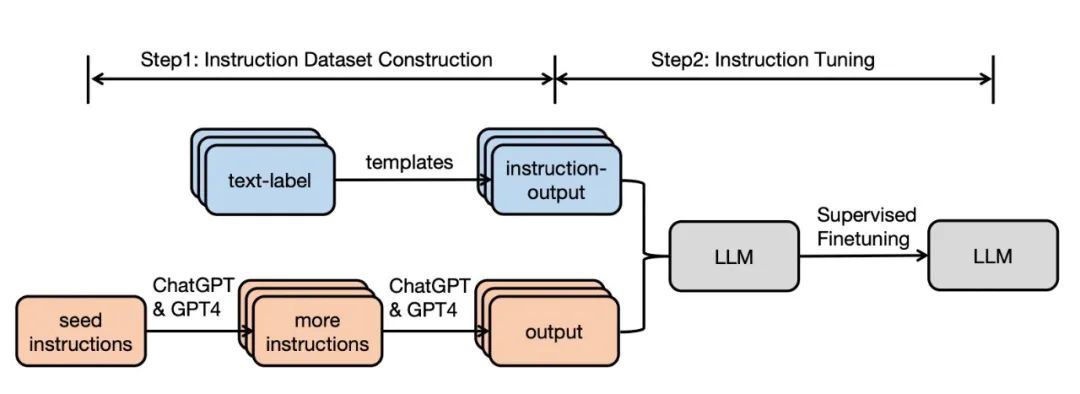
This paper reviews research work in the rapidly developing field of Instruction Tuning (IT). Instruction tuning is a key technique that enhances the capabilities and controllability of large language models (LLMs). Instruction tuning refers to further training LLMs under supervision on datasets containing (instruction, output) pairs, bridging the gap between the LLM’s next word prediction objective and the goal of having the LLM follow human instructions. In this paper, we systematically review the literature, including general methodologies of IT, construction of IT data, training of IT models, and applications in different modes, domains, and applications, while also analyzing aspects that affect IT results (e.g., generating instruction outputs, the size of instruction datasets, etc.). We also review potential pitfalls of IT and criticisms of it, while pointing out current shortcomings of existing strategies and suggesting some beneficial research directions.
Link: https://www.aminer.cn/pub/64e432c73fda6d7f0600b894
We have released a set of large language models called Code Llama, based on Llama 2, which provides state-of-the-art performance for code, filling capabilities, support for large input contexts, and zero-shot instruction-following abilities. We offer various variants to cover a wide range of applications: base model (Code Llama), Python expertise (Code Llama – Python), and instruction-following model (Code Llama – Instruct), with parameters of 7 billion, 13 billion, and 34 billion, respectively. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. The 7B and 13B Code Llama and Code Llama – Instruct variants support filling based on surrounding content. Code Llama achieved state-of-the-art performance on multiple code benchmarks, scoring 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama – Python 7B outperformed Llama 2 70B on HumanEval and MBPP, while all our models outperformed any other publicly available models on MultiPL-E. We released Code Llama under a permissive license allowing research and commercial use.
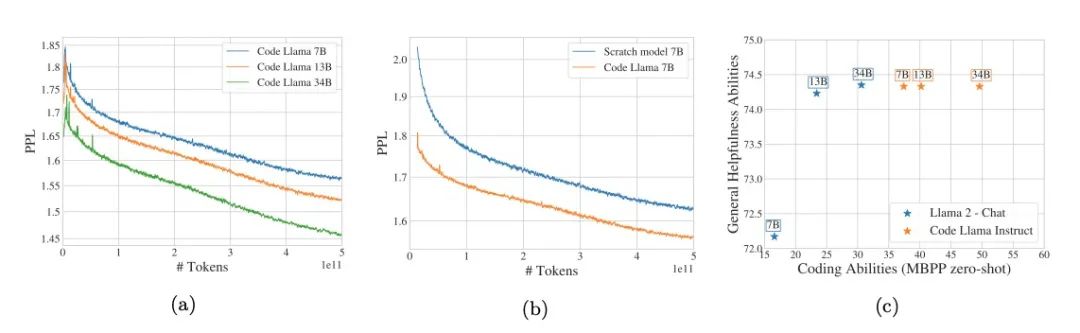
Link: https://www.aminer.cn/pub/64e82e45d1d14e646633f5aa