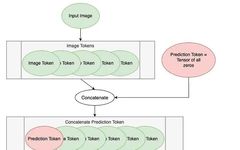
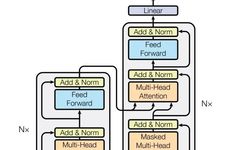
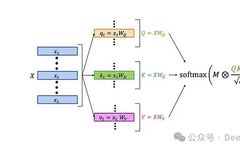
Introduction to Transformer Models
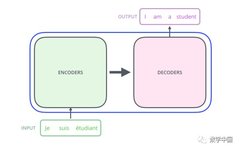
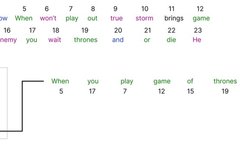
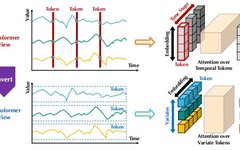
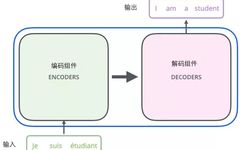
Madio.net Mathematics China ///Editor: Only Tulips’ Garden The essence of the Transformer is an Encoder-Decoder structure, as shown in the figure: Before the advent of transformers, most sequence-to-sequence models (Encoder-Decoder) were based on CNNs and RNNs. In this article, we have already introduced the Attention and Self-attention mechanisms, and the Transformer is based on the … Read more