The Transformer has become a mainstream model in the field of artificial intelligence, with a wide range of applications. However, the computational cost of the attention mechanism in Transformers is relatively high, and this cost continues to increase with the length of the sequence.
To address this issue, numerous modifications to the Transformer have emerged in the industry to optimize its operational efficiency. This time, I will share nine articles that improve the efficiency of Transformer models, to help everyone use the models more effectively and find innovative points in the papers.
The articles mainly cover four directions: sparse attention mechanisms, processing long texts with Transformers, improving Transformer efficiency, and convolutional attention. The original texts and source codes have been organized.
1. Sparse Attention Mechanisms
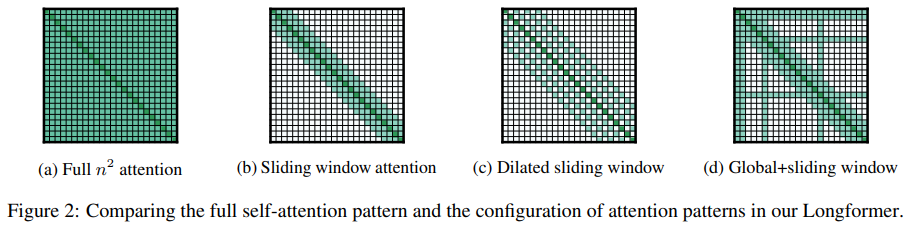
1.1 Longformer: The Long-Document Transformer
Long Document Transformer
Method Summary: Transformer-based models struggle with long sequences because their self-attention operations scale quadratically with the length of the sequence. Longformer addresses this issue by introducing an attention mechanism that scales linearly with sequence length, allowing it to easily handle thousands of tokens or longer documents.Longformer performs excellently in character-level language modeling and achieves state-of-the-art results across various downstream tasks. Additionally, Longformer supports long document generation for sequence-to-sequence tasks and demonstrates its effectiveness on the arXiv summarization dataset.
1.2 Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
Method Summary: Time series forecasting is an important problem in many fields, including the prediction of energy output from solar power plants, electricity consumption, and traffic congestion. This paper proposes a method using Transformers to solve this forecasting problem. Although preliminary studies indicate impressive performance, the authors find two main drawbacks: locality insensitivity and memory bottlenecks. To address these issues, the authors propose convolutional self-attention and LogSparse Transformer, which can better handle local context and reduce memory costs. Experiments show that these methods have advantages in time series forecasting.
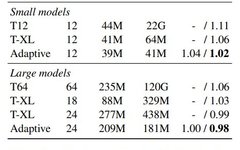
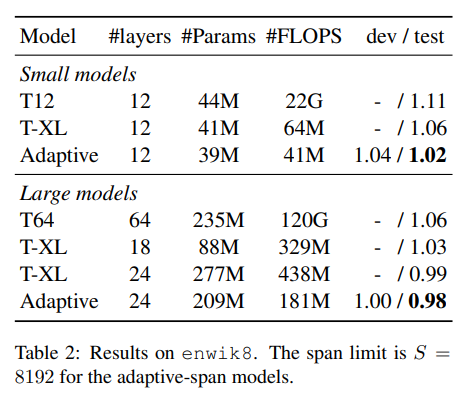
1.3 Adaptive Attention Span in Transformers
Method Summary: The paper introduces a new self-attention mechanism that can learn its optimal attention span. This allows us to significantly extend the maximum context size used in Transformers while maintaining control over memory usage and computation time. The authors demonstrate the effectiveness of this method on character-level language modeling tasks, where they achieved state-of-the-art performance on text8 and enwiki8 with a maximum context of 8k characters.
2. Processing Long Texts with Transformers
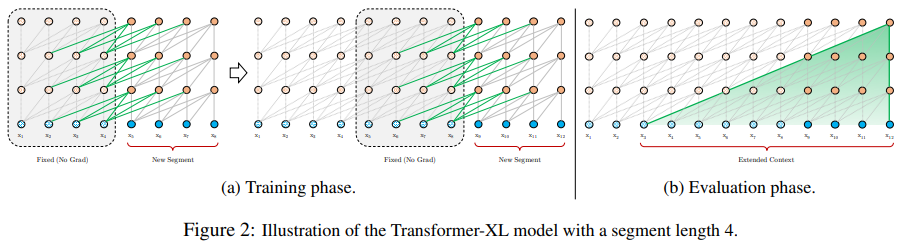
2.1 Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Method Summary: Transformers in language modeling are limited by fixed-length contexts. The authors propose a new neural network architecture, Transformer-XL, which can learn dependencies beyond fixed lengths. It consists of a segment-level recurrence mechanism and a new positional encoding scheme, capable of capturing longer dependencies and addressing context fragmentation issues. This method achieves better performance on both short and long sequences and is over 1,800 times faster than standard Transformers during evaluation.
3. Improving Transformer Efficiency
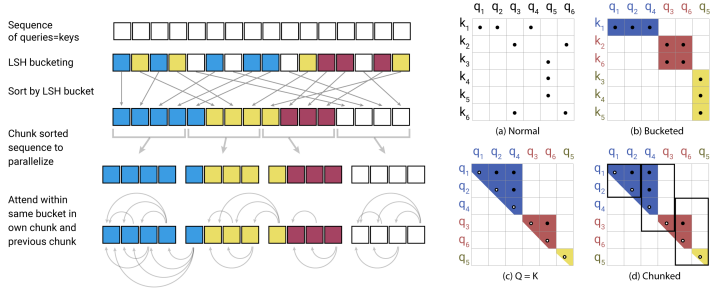
3.1 REFORMER: The Efficient Transformer
Method Summary: The training cost of large Transformer models is high, especially on long sequences. The paper proposes two techniques to improve efficiency: using locality-sensitive hashing to replace dot-product attention, reducing complexity from O(L^2) to O(L log L); and using reversible residual layers instead of standard residuals, allowing activations to be stored only once. The resulting Reformer model performs comparably on long sequences but is more memory-efficient and faster.
3.2 Rethinking Attention with Performers
Method Summary: The paper introduces Performers, a Transformer architecture that can estimate conventional (softmax) full-rank attention Transformers with provable accuracy, but using only linear space and time complexity. To approximate the softmax attention kernel, Performers utilize a novel fast attention method via orthogonal random features (FAVOR+), and can be used to efficiently model kernelized attention mechanisms.

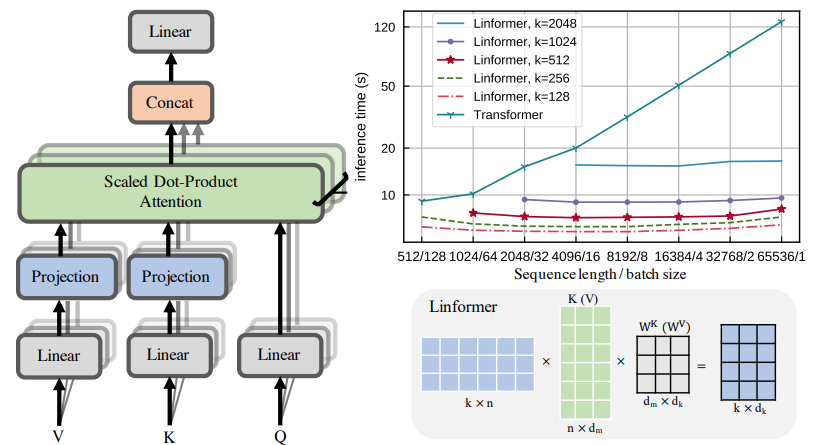
3.3 Linformer: Self-Attention with Linear Complexity
Method Summary: Large Transformer models perform excellently in natural language processing applications, but the training and deployment costs for long sequences are high. This paper proposes a new self-attention mechanism that reduces complexity from O(n^2) to O(n), while maintaining performance. The resulting Linformer is more time- and memory-efficient than standard Transformers.
4. Convolutional Attention
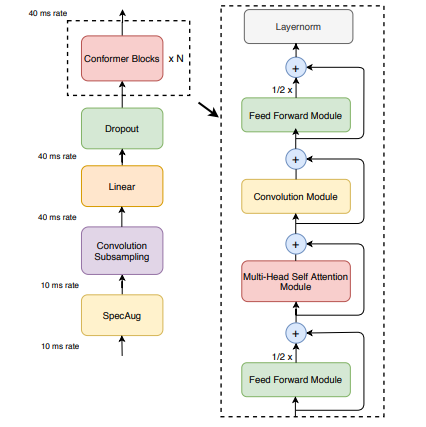
4.1 Conformer: Convolution-Augmented Transformer for Speech Recognition
Method Summary: Conformer is a model that combines convolutional neural networks and Transformers for speech recognition. It is capable of capturing both local and global dependencies in audio sequences. It achieves state-of-the-art accuracy, achieving 2.1%/4.3% WER on the LibriSpeech benchmark without a language model, and 1.9%/3.9% WER with an external language model. Additionally, it features a competitive small model with only 10M parameters.
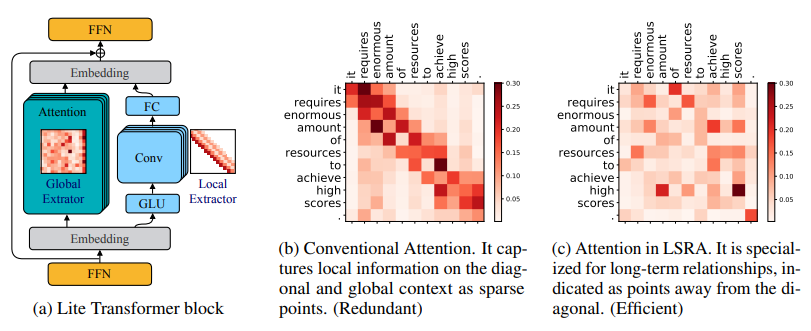
4.2 Lite Transformer with Long-Short Range Attention
Method Summary: This paper proposes an efficient mobile natural language processing architecture, Lite Transformer, which uses long-short range attention (LSRA) to enhance performance. LSRA dedicates a set of heads for local context modeling (via convolution) and another set for long-distance relationship modeling (via attention). On three language tasks, Lite Transformer consistently outperforms standard Transformers. Under resource constraints, Lite Transformer achieved a 1.2/1.7 BLEU score increase over Transformers in the WMT’14 English-French translation task.
Editor / Zhang Zhihong
Reviewer / Fan Ruiqiang
Re-checker / Zhang Zhihong
Click below
Follow us
Read the original text