Madio.net
Mathematics China
///Editor: Only Tulips’ Garden
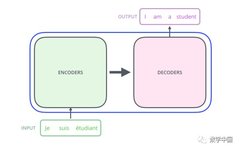
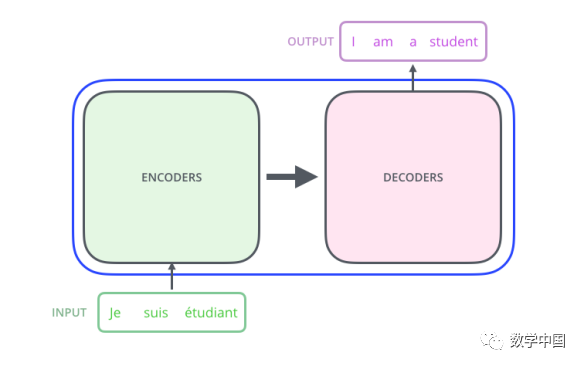
The essence of the Transformer is an Encoder-Decoder structure, as shown in the figure:
Before the advent of transformers, most sequence-to-sequence models (Encoder-Decoder) were based on CNNs and RNNs. In this article, we have already introduced the Attention and Self-attention mechanisms, and the Transformer is based on the attention mechanism. The attention mechanism is much better than CNNs and RNNs. How is it better? Attention can solve the long-distance dependency problem present in RNNs and their variants, meaning that the attention mechanism can have better memory, capable of remembering information over longer distances. Additionally, the most crucial point is that attention supports parallel computation, which is key. The transformer model is entirely based on the attention mechanism, completely discarding the structures of CNNs and RNNs.
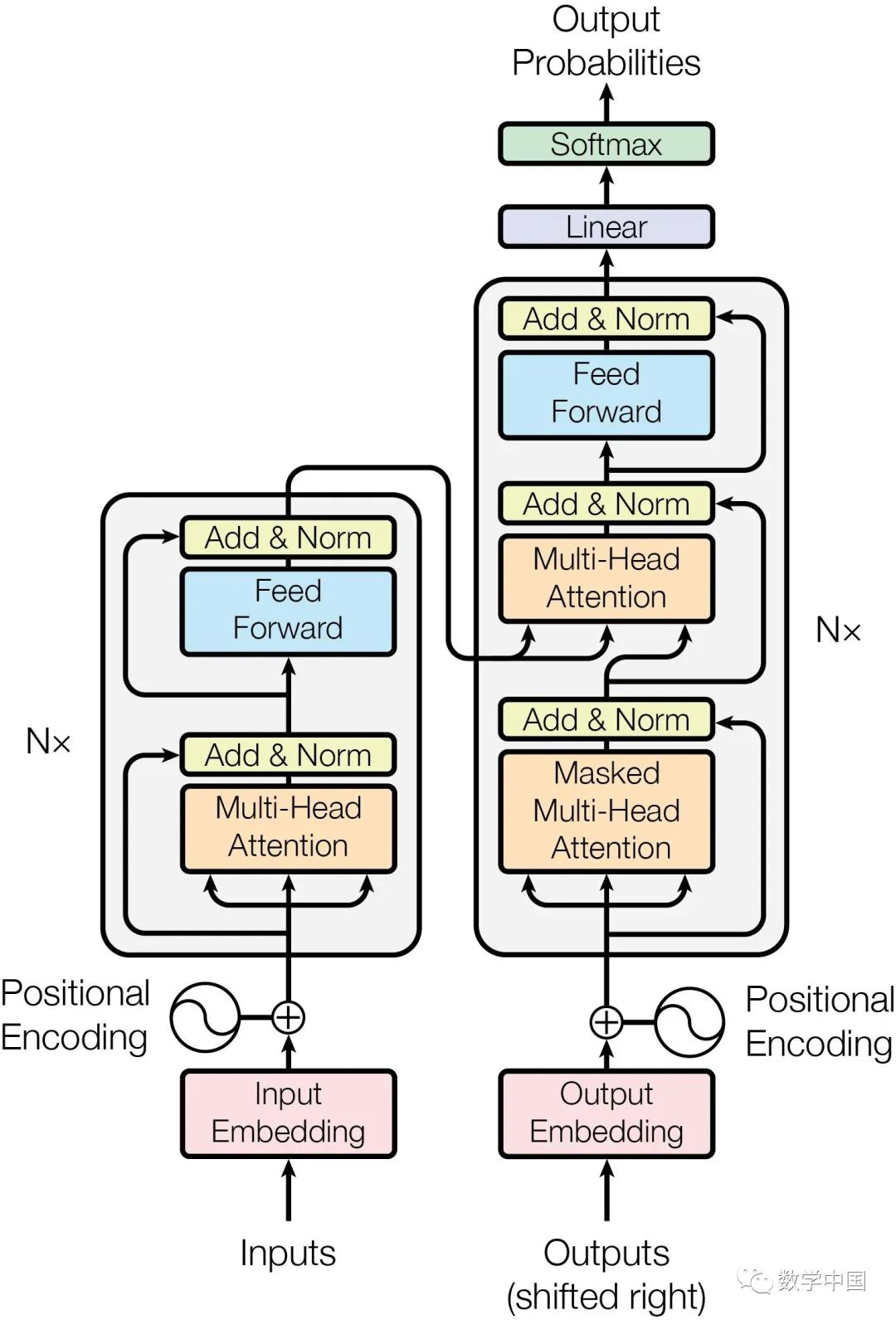
The Transformer is a model based on the multi-head attention mechanism. Understanding the attention mechanism makes this quite simple, and it has been detailed previously.
The input to the Transformer Encoder model (as previously written in the paper) is the word embedding representation of a sentence and its corresponding positional encoding information. The core layer of the model is a multi-head attention mechanism. The attention mechanism was initially applied in image feature extraction tasks. For example, when a person observes an image, they do not look at every part of the image but focus attention on the important parts. Later, researchers applied the attention mechanism to NLP tasks and achieved excellent results. The multi-head attention mechanism uses multiple attention mechanisms for separate calculations to obtain more layers of semantic information, then concatenates the results obtained from each attention mechanism to get the final result. The Add&Norm layer sums the inputs and outputs of the Multi-Head Attention layer and normalizes them before passing them to the Feed Forward layer, and finally performs another Add&Norm process to output the final word vector matrix.
Advantages and Disadvantages of Transformer
Advantages: (1) Although the Transformer ultimately did not escape the traditional learning paradigm, it is merely a combination of fully connected layers (or one-dimensional convolutions) and Attention. However, its design is innovative enough as it discards the fundamental RNN or CNN in NLP and achieves very good results. The design of the algorithm is brilliant and deserves careful study and appreciation from everyone involved in deep learning. (2) The key to the performance improvement brought by the design of the Transformer is that the distance between any two words is 1, which is very effective in solving the challenging long-term dependency problem in NLP. (3) The Transformer can be applied not only in the field of NLP machine translation but also has significant research potential beyond NLP. (4) The algorithm’s parallelism is excellent and aligns well with current hardware (mainly referring to GPUs).
Disadvantages: (1) The brutal abandonment of RNNs and CNNs, while impressive, also causes the model to lose the ability to capture local features. The combination of RNN + CNN + Transformer may yield better results. (2) The positional information lost by the Transformer is actually very important in NLP, and adding Position Embedding to the feature vectors in the paper is merely a stopgap measure, failing to change the inherent flaws in the Transformer structure.