
Source: Algorithm Advancement
This article is about 4000 words long and is recommended for an 8-minute read.
This article deeply explores the potential connections between Transformer, Recurrent Neural Networks (RNN), and State Space Models (SSM).
By exploring the potential connections between seemingly unrelated Large Language Model (LLM) architectures, we may open up new avenues for facilitating the exchange of ideas between different models and improving overall efficiency.
Despite the recent attention on linear RNNs such as Mamba and State Space Models (SSM), the Transformer architecture remains a major pillar of LLMs. This pattern may soon change: hybrid architectures like Jamba, Samba, and Griffin show great potential. These models significantly outperform Transformers in terms of time and memory efficiency, while not significantly decreasing abilities compared to attention-based LLMs.
Recent research has revealed deep connections between different architectural choices, including Transformers, RNNs, SSMs, and matrix mixers. This finding is significant as it provides the possibility for the transfer of ideas between different architectures. This article will delve into Transformer, RNN, and Mamba 2, using detailed algebraic analysis to understand the following points:
-
Transformers can be viewed as RNNs in certain cases (Section 2)
-
State Space Models may be hidden within the masks of self-attention mechanisms (Section 4)
-
Mamba can be rewritten as masked self-attention under specific conditions (Section 5)
These connections are not only interesting but may also have profound implications for future model design.
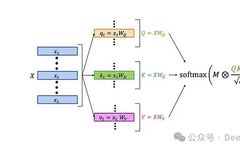
Masked Self-Attention Mechanism in LLMs
First, let’s review the structure of the classic LLM self-attention layer:
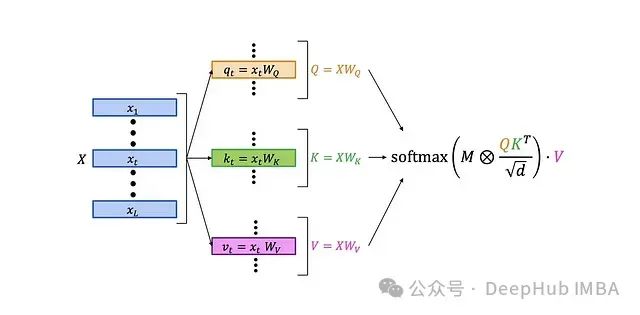
The more detailed structure is as follows:
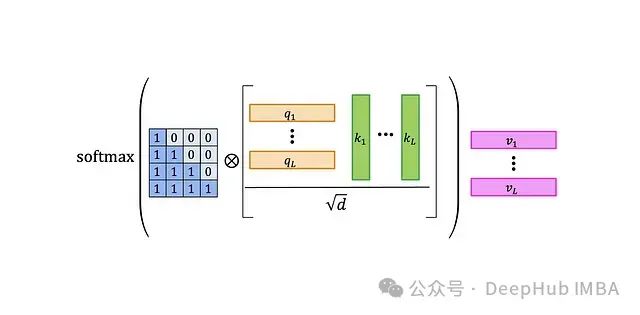
The workflow of the self-attention layer is as follows:
-
Multiply the query matrix Q and the key matrix K to obtain an L×L matrix containing the scalar product of the queries and keys.
-
Normalize the resulting matrix.
-
Perform element-wise multiplication of the normalized matrix with the L×L attention mask. The default causal mask is shown in the figure—the 0-1 matrix on the left. This step zeroes out the product of earlier queries with later keys, preventing the attention mechanism from “seeing the future”.
-
Apply the softmax function to the result.
-
Finally, multiply the attention weight matrix A with the value matrix V. The t-th row of the output can be represented as:
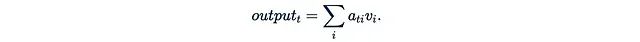
This means that the i-th value is weighted by “the attention weight of the t-th query on the i-th key”.
Many design choices in this architecture could be modified. Next, we will explore some possible variants.
Linearized Attention
The softmax function in the attention formula ensures that values are mixed with positive coefficients that sum to one. This design preserves certain statistical properties but also imposes limitations. For instance, even if we want to utilize the associative law, such as (QK^T)V = Q(K^TV), we cannot break through the constraints of softmax.
Why is the associative law so important? Because changing the order of multiplication can significantly impact computational complexity:
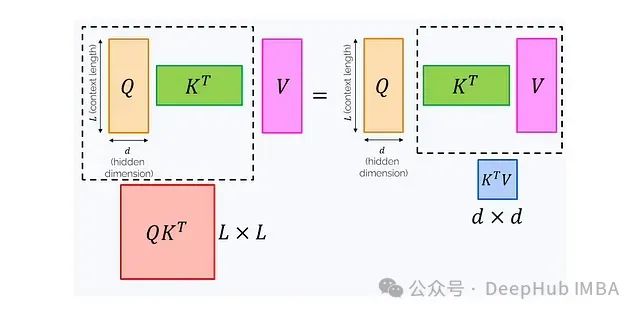
The left formula requires calculating an L×L matrix, which has a complexity of O(L²d) and a memory consumption of O(L²) if this matrix is fully present in memory. The right formula requires calculating a d×d matrix, with a complexity of O(Ld²) and a memory consumption of O(d²).
As the context length L increases, the computational cost of the left formula rapidly becomes prohibitively high. To address this issue, we can consider removing softmax. Let’s expand the formula with softmax in detail:
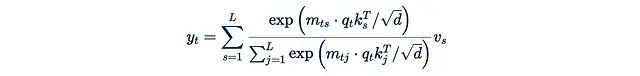
Where
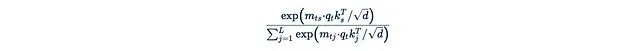
is the softmax function. The exponential function is the main barrier that prevents us from extracting any terms from it. If we directly remove the exponential function:
Then the normalization factor
also disappears.
This simplified formula has a problem: q_t^T k_s cannot guarantee positivity, which may lead to values being mixed with coefficients of different signs, which is theoretically unreasonable. Worse still, the denominator may be zero, leading to computational crashes. To mitigate this issue, we can introduce a “good” element-wise function φ (called a kernel function):
The original research suggests using φ(x) = 1 + elu(x) as the kernel function.
This variant of the attention mechanism is called linearized attention. One of its important advantages is that it allows us to utilize the associative law:
The relationship between M, K^T, and V in parentheses now becomes quite complex, no longer just ordinary matrix multiplication and element-wise multiplication. We will discuss this computational unit in detail in the next section.
If M is a causal mask, meaning that the diagonal and below are 1s and above the diagonal are 0s:
Then the computation can be further simplified:
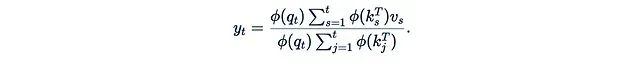
This can be computed recursively in a simple way:
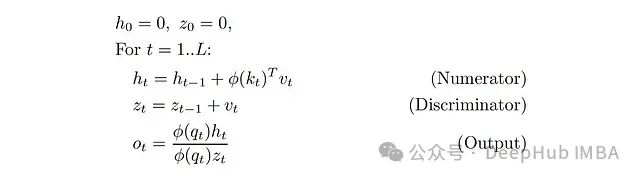
This was the first paper to propose linearized attention, titled “Transformers are RNNs” at ICML 2020.
In this formula, we have two hidden states: the vector z_t and the matrix h_t (φ(k_t)^T v_t is a column vector multiplied by a row vector, resulting in a d×d matrix).
Recent research often presents linearized attention in a more simplified form, removing the φ function and denominator:
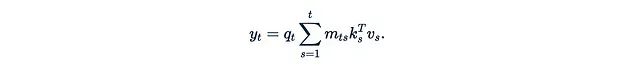
Linearized attention has two main advantages:
-
As a recursive mechanism, it has linear complexity with respect to sequence length L during inference.
-
As a Transformer model, it can be efficiently trained in parallel.
But you may ask: if linearized attention is so excellent, why hasn’t it been widely adopted in all LLMs? Are we discussing the secondary complexity issue of attention? In fact, LLMs based on linearized attention have lower stability during training and slightly inferior capability compared to standard self-attention. This may be because the fixed d×d shape bottleneck conveys less information than the adjustable L×L shape bottleneck.
Further Exploration
The connection between RNN and linearized attention has been rediscovered and explored in several recent studies. A common pattern is using matrix hidden states with the following update rule:
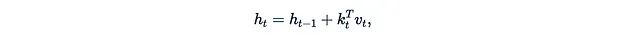
Where k_t and v_t can be viewed as some kind of “key” and “value”, the output form of the RNN layer is:
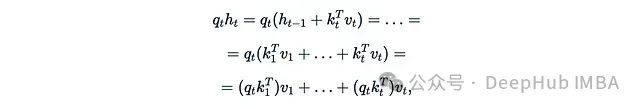
This is essentially equivalent to linear attention. The following two papers provide interesting examples:
1. xLSTM (May 2024): This paper proposes improvements to the famous LSTM recursive architecture. Its mLSTM block contains a matrix hidden state, updated as follows:
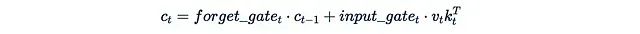
The output is obtained by multiplying this state with a “query”. (Note: The linear algebra setup in this paper is opposite to ours, so the order of query, key, and value appears a bit strange.)
2. Learning to (learn at test time) (July 2024): This is another RNN architecture with a matrix hidden state, where the hidden state W is a parameter of a function, optimized through gradient descent during iterations at t:
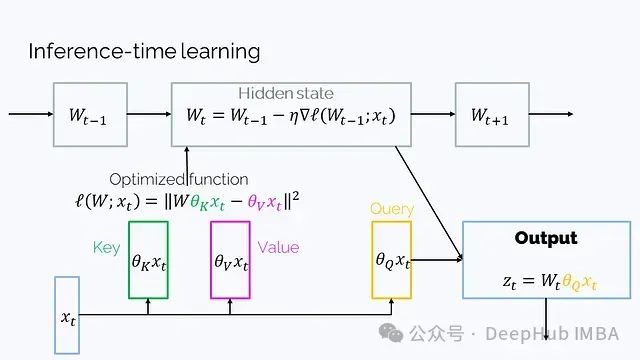
This setup is also transposed, so the order looks a bit different. Although the mathematical expression is more complex than W_t = W_{t-1} + v_t k_t^T, it can be simplified to this form.
We have detailed both of these papers, and those interested can search for them.
Attention Masks
After simplifying the masked attention mechanism, we can start exploring its potential directions for development. An obvious research direction is to choose different lower triangular matrices (ensuring that “future” is not seen) as masks M, rather than simply using a 0-1 causal mask. Before engaging in this exploration, we need to address the efficiency issues it brings.
In the previous section, we used a simple 0-1 causal mask M, which made recursive computation possible. However, in general, this recursive trick no longer applies:
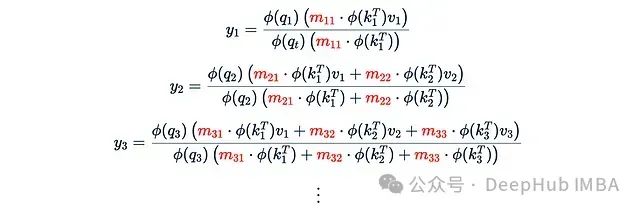
The coefficients m_ts are no longer the same, and there is no simple recursive formula to relate y_3 to y_2. Therefore, for each t, we need to compute the total sum from scratch, which makes the computational complexity quadratic rather than linear.
The key to solving this problem is that we cannot use arbitrary masks M, but should choose special, “good” masks. We need those that can multiply quickly with other matrices (note that this is not element-wise multiplication). To understand how to benefit from this property, let’s analyze how to compute efficiently:
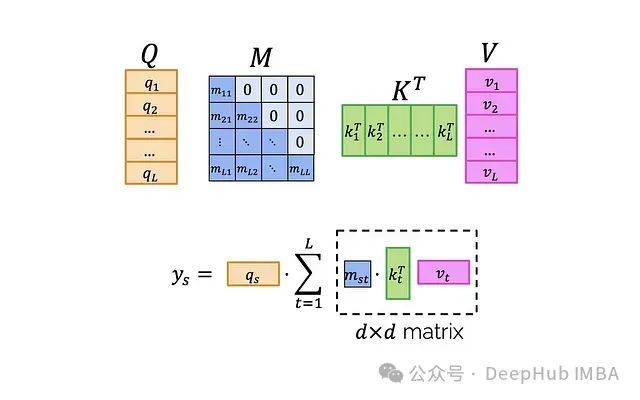
First, clarify the meaning of this expression:
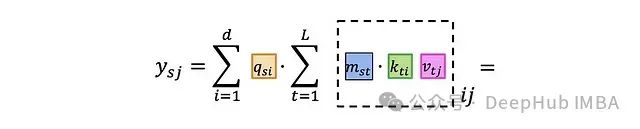
If we delve into individual index levels:
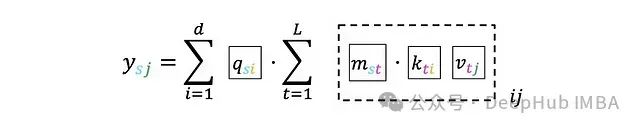
Now we can propose a four-step algorithm:
Step 1. Create a three-dimensional tensor Z using K and V, where:
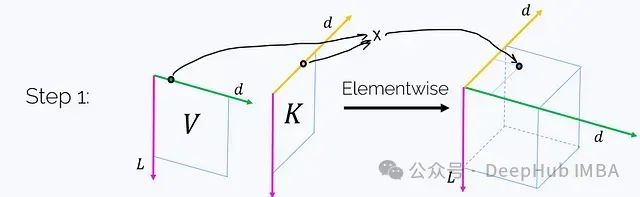
(Each axis is labeled with its length.) This step requires O(Ld²) time and memory complexity. Notably, if we sum this tensor along the magenta axis t, we will obtain the matrix product K^T V:
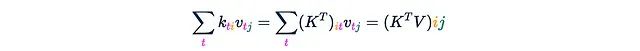
Step 2. Multiply M by this tensor (note that this is not element-wise multiplication). M multiplies Z along every “column” of the magenta axis t.
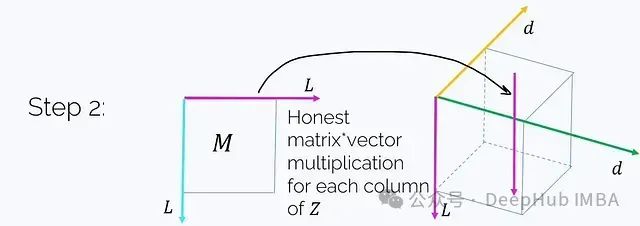
This yields:
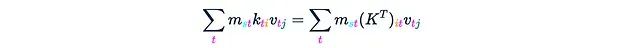
Let’s denote this result as H. Next, we just need to multiply everything by q, which will be completed in the next two steps.
Step 3a. Take Q and perform element-wise multiplication with each j = const layer of H:
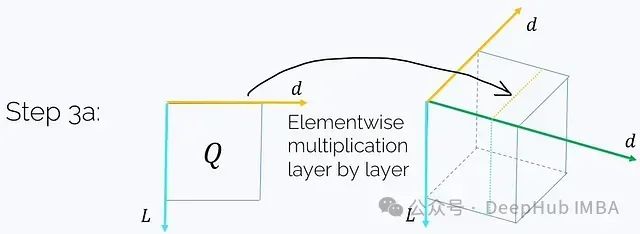
This will yield:
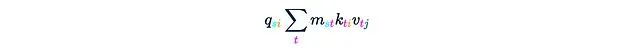
This step requires O(Ld²) time and memory complexity.
Step 3b. Sum the resulting tensor along the i-axis:
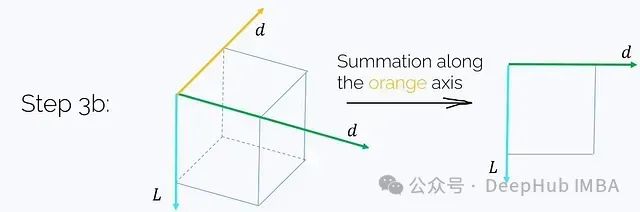
This step also requires O(Ld²) time and memory complexity. Finally, we obtain the desired result:
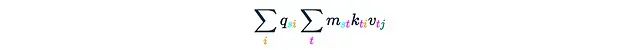
In this process, the most critical part is step two, for which we deliberately omitted the complexity analysis. A rough estimate is:
Each matrix multiplication requires O(L²) complexity, repeated d² times.
This would lead to a huge O(L²d²) complexity. However, our goal is to choose special M such that the complexity of multiplying M by a vector is O(RL), where R is some not-too-large constant.
For example, if M is a 0-1 causal matrix, then multiplying it actually computes a cumulative sum, which can be done in O(L) time. But there are many other structured matrix options with fast vector multiplication properties.
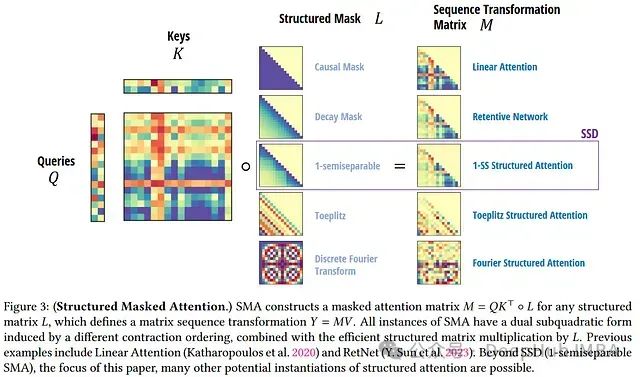
In the next section, we will discuss an important example of this type of matrix—separable matrices, which have close connections to state space models.
Separable Matrices and State Space Models
Let’s review the definition of (discretized) State Space Models (SSM). SSM is a class of sequential models connecting 1D input x_t, r-dimensional hidden state h_t, and 1D output u_t, expressed mathematically as follows:
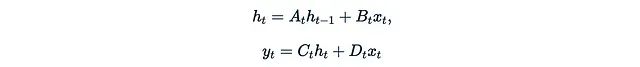
In discrete form, SSM is essentially a complex linear RNN with skip connections. To simplify subsequent discussions, we can even ignore the skip connections by setting D_t = 0.
Let’s represent SSM as a single matrix multiplication:
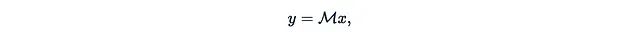
Where
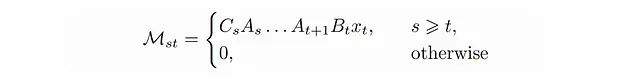
M is a lower triangular matrix, similar to the attention mask we discussed earlier.
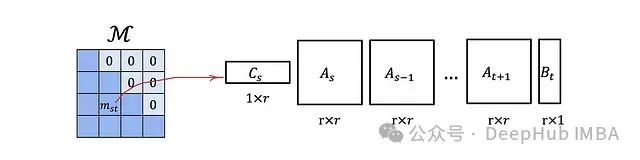
This type of matrix has an important advantage:
A lower triangular matrix of size L × L, if its elements can be represented in this way, can be stored with O(rL) memory and has O(rL) complexity for matrix-vector multiplication, rather than the default O(L²).
This means that every state space model corresponds to a structured attention mask M that can be used in efficient Transformer models with linearized attention.
Even without the surrounding query-key-value mechanism, the separable matrix M itself is already quite complex and expressive. It may itself be a masked attention mechanism. We will explore this in detail in the next section.
State Space Duality
Here, we will introduce a core result from the Mamba 2 paper.
Let’s once again consider y = Mu, where u = u(x) is a function of the input, and M is a separable matrix. If we consider a very special case where each A_t is a scalar matrix: A_t = a_t I. In this case, the formula becomes particularly simple:
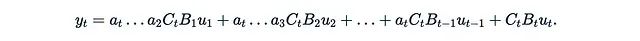
Here,
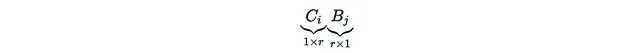
is just a scalar. We can also stack C_i and B_i into matrices B and C such that:
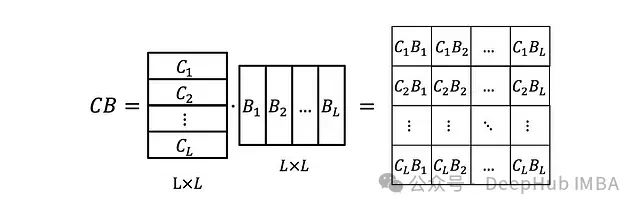
Now we also need to define the matrix:
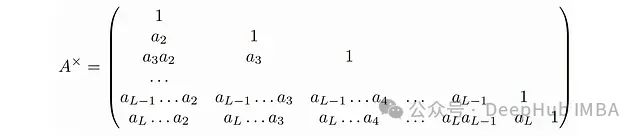
Then it can be easily verified:
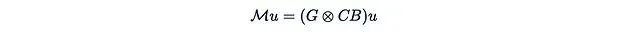
Does this expression look familiar? This is actually a masked attention mechanism, where:
-
G serves as the mask
-
C serves as the query matrix Q
-
B serves as the transposed key matrix K^T
-
u serves as the value matrix V
In the classic SSM, B and C are constants. However, in the Mamba model, they are designed to depend on data, further reinforcing the correspondence with attention mechanisms. This specific correspondence between state space models and masked attention is referred to as state space duality in the Mamba 2 paper.
Further Exploration
Using matrix mixers instead of more complex architectures is not a new idea. An early example is the MLP-Mixer, which uses MLPs for spatial mixing in computer vision tasks instead of convolutions or attention.
Although current research mainly focuses on large language models (LLMs), some papers have proposed non-Transformer, matrix mixing architectures for encoder models. For example:
-
FNet from Google Research, whose matrix mixer M is based on Fourier transforms.
-
Hydra, which proposes adaptive schemes for separable matrices in non-causal (non-triangular) working modes, among other innovations.
Conclusion
This article deeply explores the potential connections between Transformer, Recurrent Neural Networks (RNN), and State Space Models (SSM). Through these analyses, the article demonstrates the deep connections between seemingly different model architectures, providing new perspectives and possibilities for future model design and cross-architecture idea exchange.
About Us
Data Pie THU, as a data science public account, is backed by the Tsinghua University Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, striving to build a data talent gathering platform, and creating the strongest group of data in China.

Sina Weibo: @Data Pie THU
WeChat Video Account: Data Pie THU
Today’s Headline: Data Pie THU