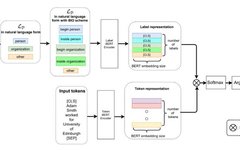
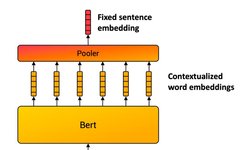
Implementing DistilBERT: A Distilled BERT Model Code
Source: DeepHub IMBA This article is about 2700 words long and suggests a reading time of 9 minutes. This article takes you into the details of Distil and provides a complete code implementation. This article provides a detailed introduction to DistilBERT and gives a complete code implementation. Machine learning models have become increasingly large, and … Read more