
This article is reproduced from:NLP Intelligence Bureau
Since Google introduced the pre-trained language model BERT, various applications of language models have emerged.
However, most models were proposed in English contexts, and their performance often declines to varying degrees when transferred to Chinese contexts.

Previously, my friends and I participated in the CCKS machine reading comprehension competition, and during our research, we found that Liu Ting, Cui Yiming, and Che Wanxiang from HIT proposed a pre-trained language model for Chinese, called MacBERT, which has refreshed the SOTA for many downstream tasks.
We tested MacBERT in the competition, and the score improved significantly, ultimately placing 3rd out of 246 participating teams.

This article will introduce you to the more powerful Chinese language model MacBERT.
Paper Link
https://arxiv.org/pdf/2004.13922.pdf
Open Source Weights
https://github.com/ymcui/MacBERT
1. What is MacBERT?
Let’s briefly review what BERT is.
BERT is essentially a self-encoding language model. To gain extensive knowledge, BERT is trained on over 300 million words and uses a 12-layer bidirectional Transformer architecture. Note that BERT only uses the encoder part of the Transformer, which can be understood as BERT aiming to learn the internal semantic information of large texts.
One of the specific training objectives is known as the masked language model, MLM. That is, when inputting a sentence, 15% of the characters are marked with a “mask” label, and through embedding and 12 layers of Transformer, the model predicts which character was originally at the masked position.
input: 欲把西[mask]比西子,淡[mask]浓抹总相宜
output: 欲把西[湖]比西子,淡[妆]浓抹总相宜
For example, we input Su Dongpo’s poem “欲把西[mask]比西子,淡[mask]浓抹总相宜“, and the model needs to predict that the masked parts are “湖” and “妆” based on the unmasked context.
In contrast, MacBERT retains the overall architecture of BERT but primarily improves the training objectives.
Improvements for the MLM Task
Mac = MLM as correction, which refers to the corrected mask strategy.
One of the shortcomings of the original BERT model is the inconsistency between the pre-training and fine-tuning stages, where pre-training has [mask] characters, but fine-tuning does not.
MacBERT replaces masked characters with similar words of the target word, reducing the gap between the pre-training and fine-tuning stages.
The specific implementation consists of two steps: 1) We use full-word masking and N-gram masking strategies to replace random masking, where the ratio of 1-gram to 4-gram at the word level is 40%, 30%, 20%, and 10% respectively.
2) Instead of using [mask] characters, we look for semantically similar words to the examined word using word2vec for masking. In rare cases, when there are no similar words, we downgrade to using random words for replacement.
Ultimately, we mask 15% of the input words, where 80% are replaced with similar words, 10% are replaced with random words, and the remaining 10% retain the original words.
If this seems a bit abstract, this image makes it clear.

Assuming the original Chinese sentence is “Using a language model to predict the probability of the next word“. After BEP segmentation, based on BERT’s random masking strategy, it might result in:
1. 使 用 语 言 [M] 型 来 [M] 测 下 一 个 词 的 概 率。
If we add a full-word masking strategy, masking will be done at the entity level:
2. 使 用 语 言 [M] [M] 来 [M] [M] 下 一 个 词 的 概 率。
Continuing to add N-gram masking:
3. 使 用 [M] [M] [M] [M] 来 [M] [M] 下 一 个 词 的 概 率。
Finally, using the Mac masking, we replace [M] with semantically similar words:
4. 使 用 语 法 建 模 来 预 见 下 一 个 词 的 几 率。
This summarizes the core idea of MacBERT.
Improvements for the NSP Task
The original NSP has been proven to contribute little, and MacBERT introduces ALBERT’s sentence order prediction (SOP) task, which creates negative samples by switching the original order of two consecutive sentences.
Subsequent ablation experiments demonstrate that SOP performs better than NSP.
2. Experimental Setup and Results
From the Chinese Wikipedia, we obtained about 0.4B words. Additionally, we obtained 5.4B characters from collected extended data, including encyclopedias, news, and Q&A websites, which is ten times larger than Chinese Wikipedia.
To identify the boundaries of Chinese words, we used LTP for Chinese word segmentation, and the vocabulary follows the original BERT.
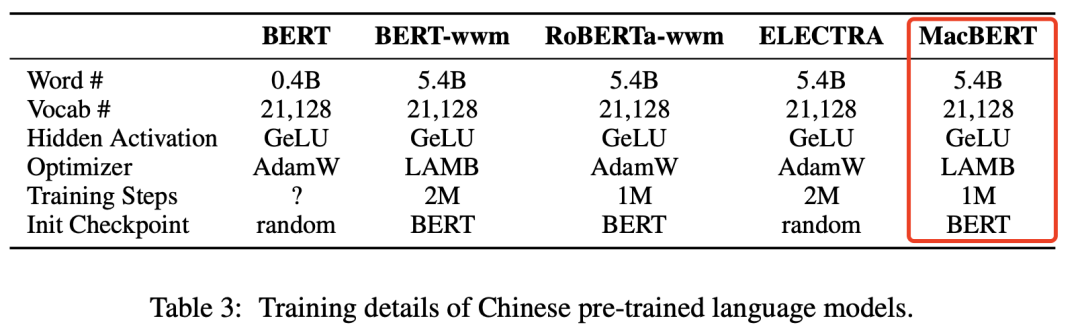
Fine-tuning Experiments
Ultimately, we compared the performance of different pre-trained models on various downstream tasks, including classification, matching, and reading comprehension.
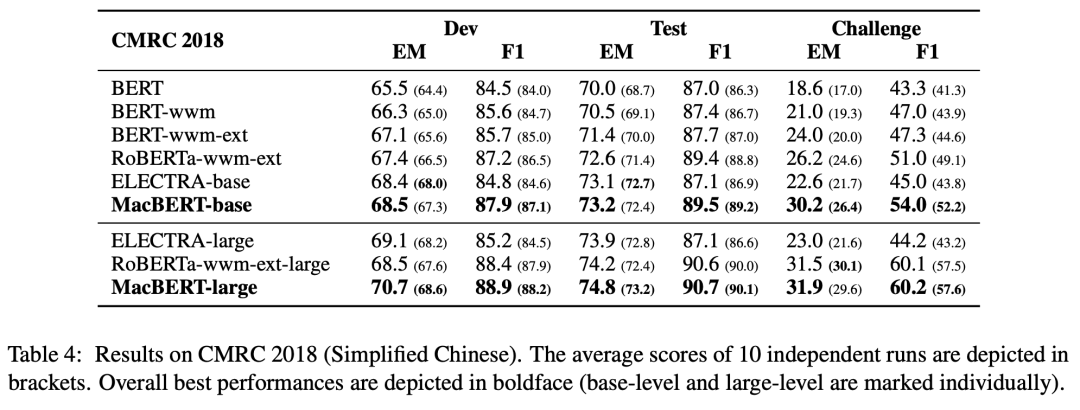
CMRC 2018 Machine Reading Comprehension:
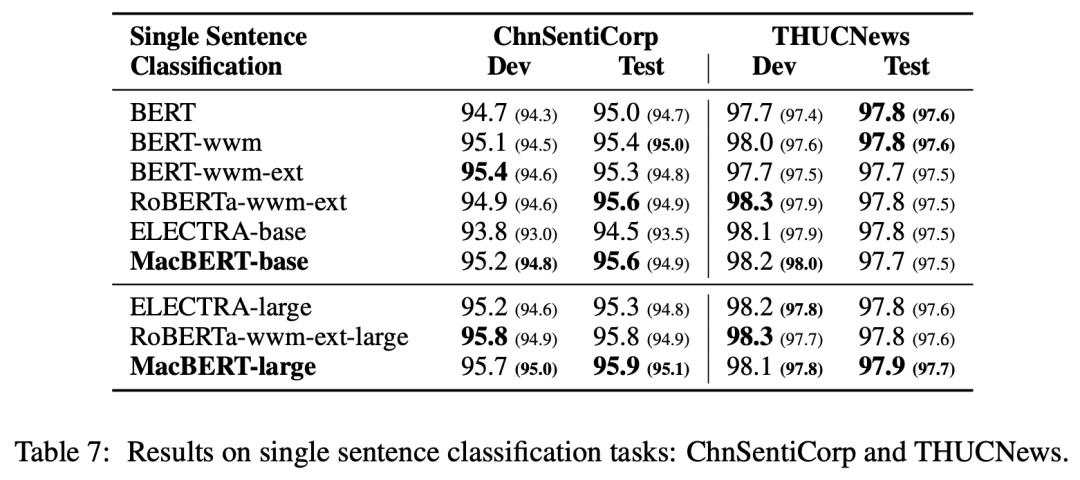
Sentiment Classification + Long Text Classification:
Text Similarity Matching:

Experiments show that MacBERT achieves significant improvements across various Chinese NLP tasks.
Where do these important improvements come from? Detailed ablation experiments provide the answer.
Ablation Experiments
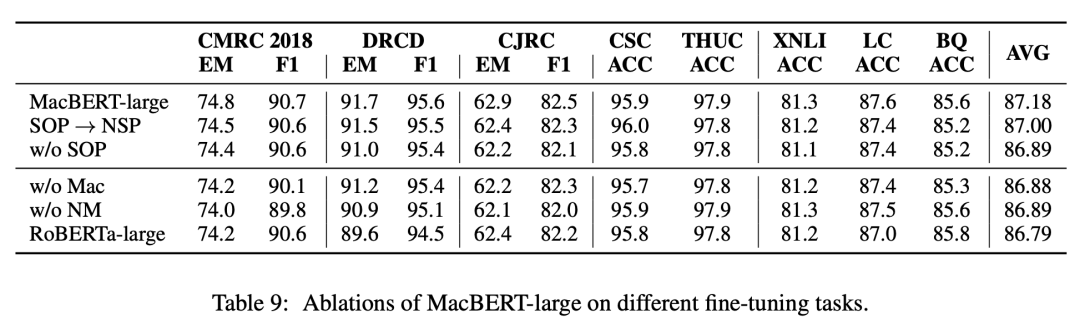
Experimental Conclusions:
1. All proposed improvements contribute positively to the overall results.
2. The most effective modifications are N-gram masking and similar word replacement.
3. The importance of the NSP task is less than that of MLM, and designing better MLM tasks to fully unleash text modeling capabilities is crucial.
4. The SOP task indeed demonstrates better performance than NSP, and removing SOP will lead to a significant decline in reading comprehension tasks.
We tested MacBERT in the CCKS competition, replacing RoBERTa with MacBERT in the encoder, resulting in a validation set F1 score increase from 0.780 to 0.797, achieving nearly a 2% improvement.
3. Summary
MacBERT modifies the MLM task as a language correction approach, reducing the differences between pre-training and fine-tuning stages.
The fine-tuning experiments on various downstream Chinese NLP datasets indicate that MacBERT can achieve significant gains in most tasks.
By analyzing the ablation experiments, we should focus more on the MLM task rather than NSP and its variants, as tasks similar to NSP have not shown overwhelming advantages over each other.
This paper, included in the EMNLP 2020 conference proceedings, represents an innovation and attempt for pre-trained language models in the Chinese context. As the model structure has not changed, it can be well compatible with existing tasks (just replace the checkpoint and configuration files).
For those interested, feel free to give it a try!
Today’s editor: Meng Yao
