Understanding BERT: Interview Questions and Insights

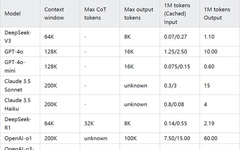
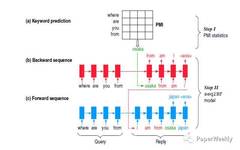
Follow the WeChat public account “ML_NLP“ Set as “starred” for heavy content delivery! Author | Adherer Organizer | NewBeeNLP Interview tips knowledge compilation series, continuously updated Full of valuable content, recommended to collect, or as usual, see you in the background (code: BT) 1. What Is the Basic Principle of BERT? BERT comes from Google’s … Read more