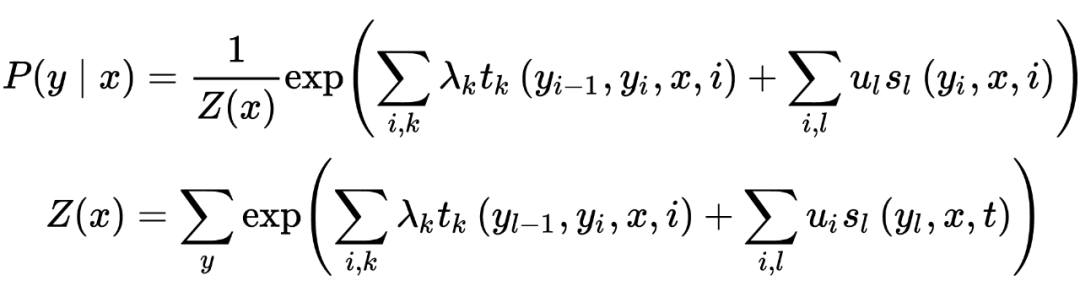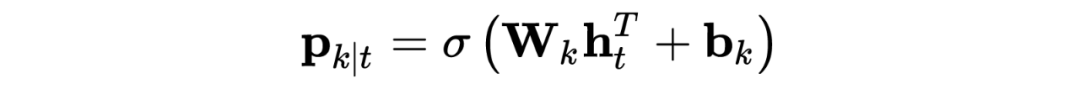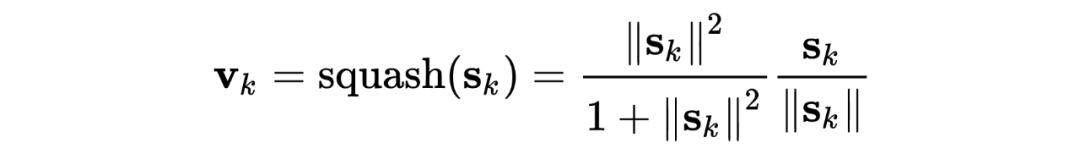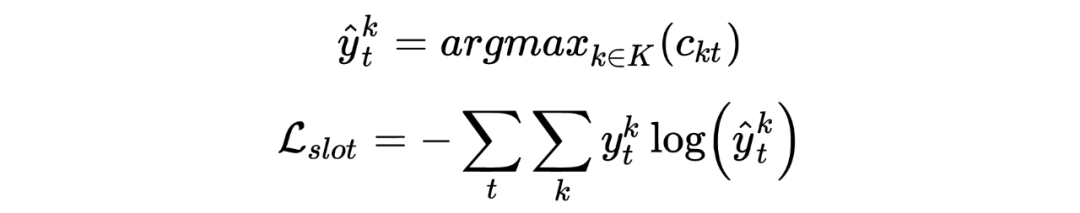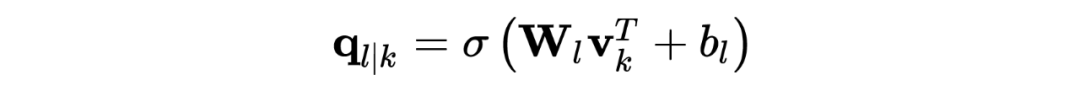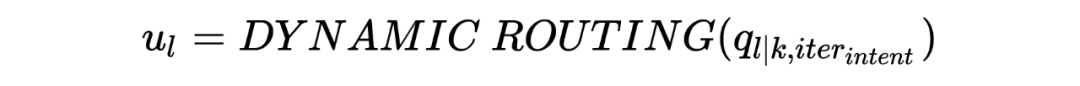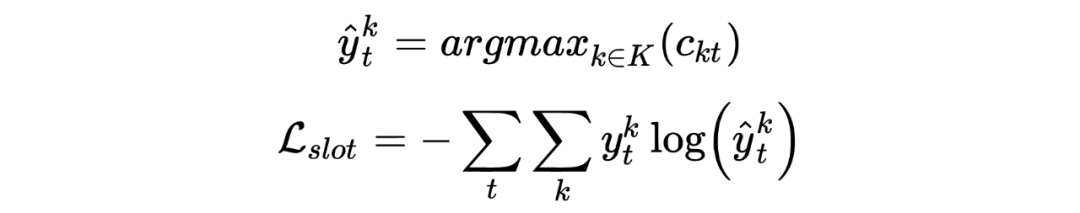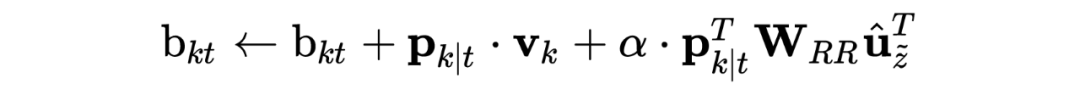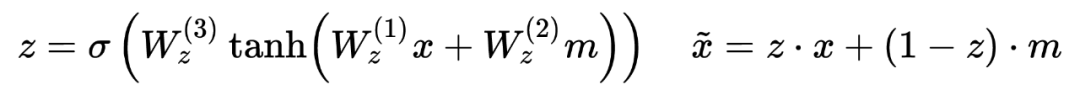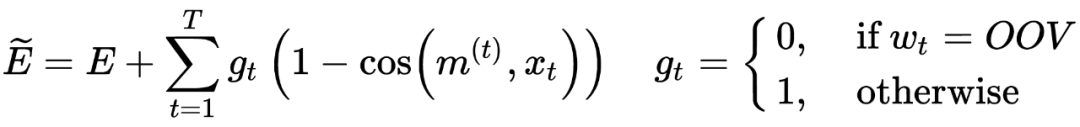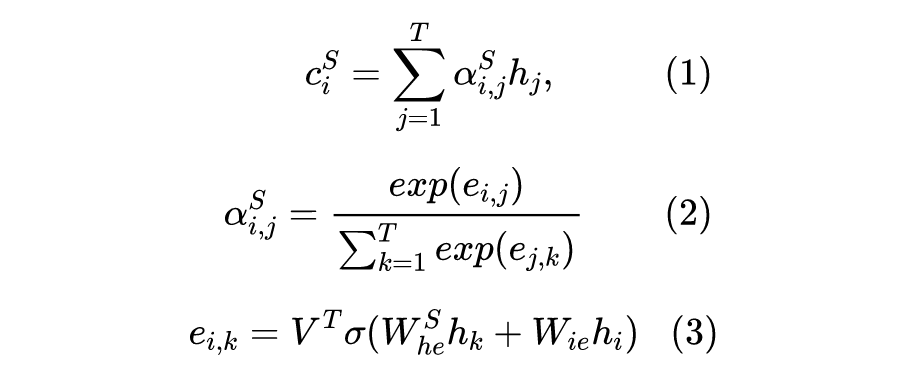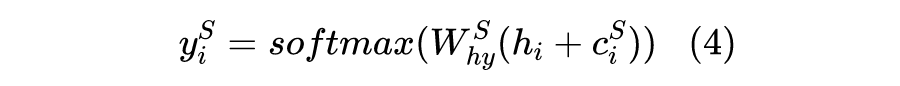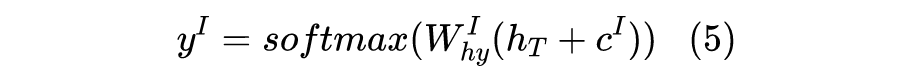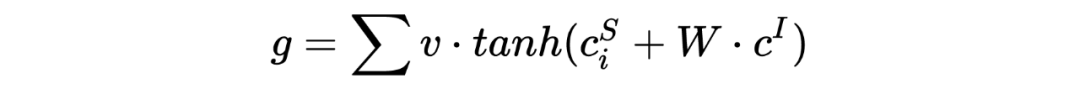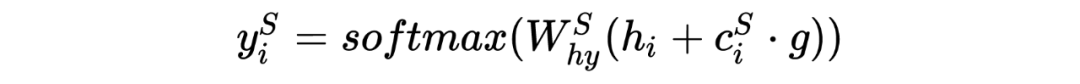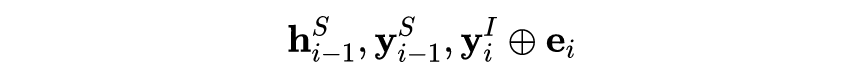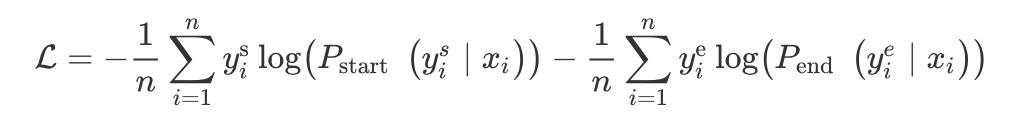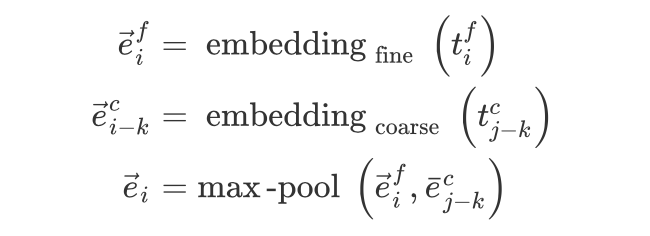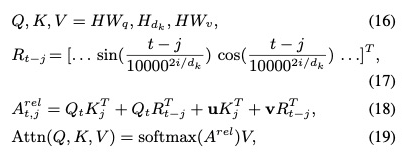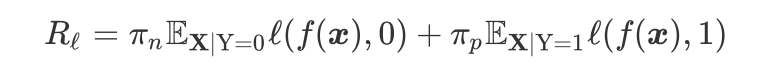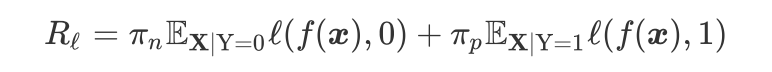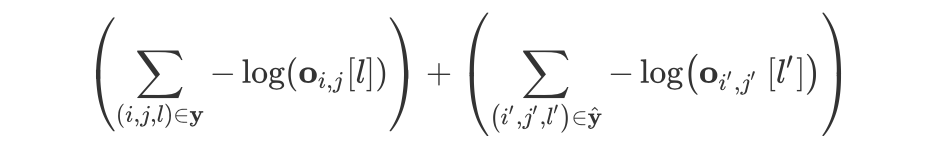MLNLP(Machine Learning Algorithms and Natural Language Processing) is one of the largest natural language processing communities in China and abroad, gathering over 500,000 subscribers, with an audience that includes NLP graduate students, university professors, and researchers from enterprises.
The vision of the community is to promote communication and progress among the academic and industrial circles of natural language processing and machine learning enthusiasts at home and abroad.
Source | PaperWeekly
©Author | Zhou Zhiyang
Affiliation | Algorithm Engineer at Tencent
Research Direction | Dialogue Robots
Named Entity Recognition (NER) refers to the identification of entities with specific meanings in the text, mainly including names of people, places, organizations, proper nouns, etc.
This article will take BERT as a time node and provide a detailed introduction to some methods used in the history of NER, as well as some methods that emerged after BERT.
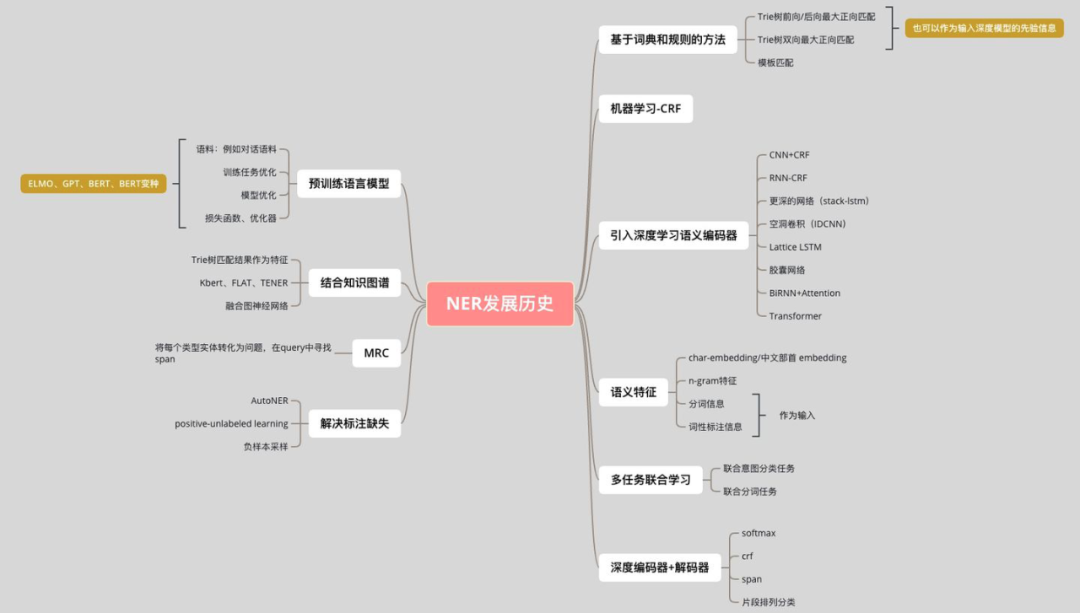
01 NER—Past Section
This section will unfold from the following aspects:
1.1 Evaluation Metrics
Using entity-level precision, recall, and F1 score.
1.2 Dictionary and Rule-Based Methods
Utilize dictionaries to match potential entities in sentences based on prior information from the dictionaries and filter them using certain rules.
Alternatively, use syntactic templates to extract entities, for example, the template “play song ${song}” can extract song= “七里香” from query=”play song 七里香”.
Forward Maximum Matching & Backward Maximum Matching & Bidirectional Maximum Matching.
The principle is quite simple, just look at the code:
https://github.com/InsaneLife/MyPicture/blob/master/NER/ner_rule.py
Forward maximum matching: Match phrases from front to back, prioritizing the longest ones.
Backward maximum matching: Match phrases from back to front, prioritizing the longest ones.
Bidirectional maximum matching principle:
-
Cover the most tokens in the match.
-
Sentences contain entities and segments after segmentation, with the fewest segments + entities.
1.3 Machine Learning-Based Methods
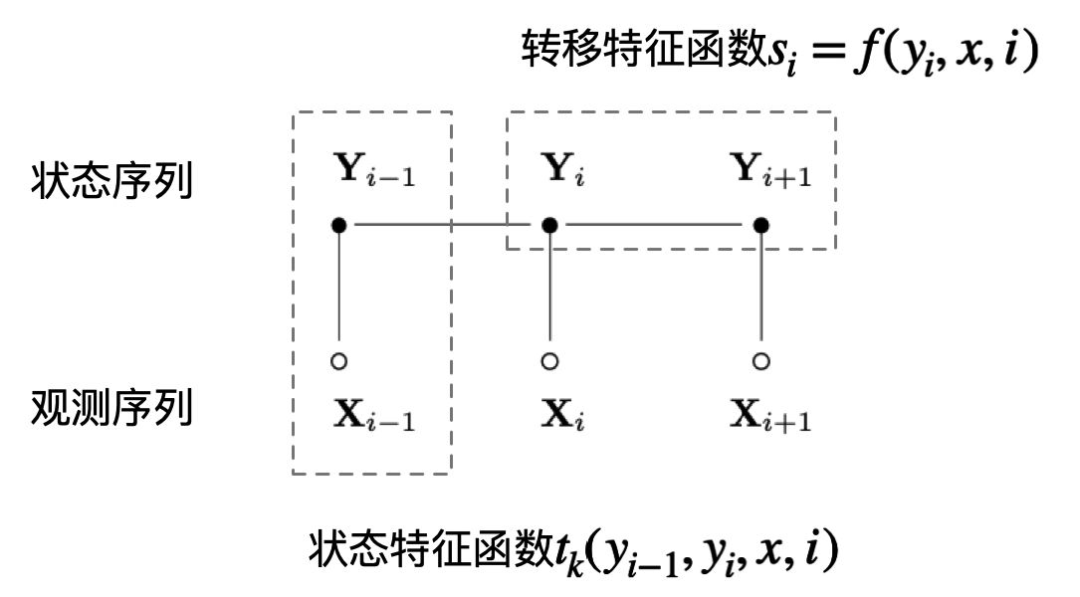
CRF, the principle can be referenced: Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data
Under the condition that random variable X takes value x, the conditional probability of random variable Y taking value y is:
Where is the feature function (as shown in the figure above), corresponds to the weight, is the normalization factor.
From Li Hang’s statistical learning methods
1.4 Introduction of Deep Learning Semantic Encoders
1.4.1 BI-LSTM + CRF
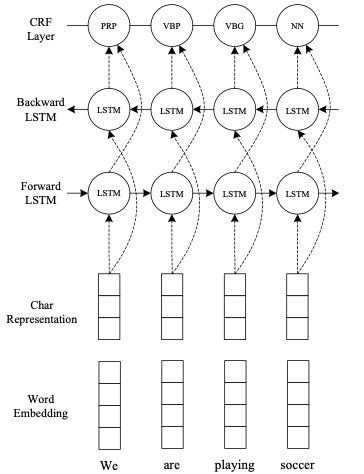
Bidirectional LSTM-CRF Models for Sequence Tagging [2]
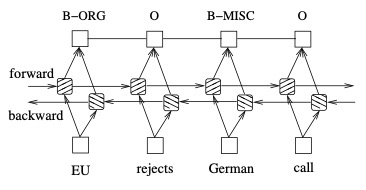
BI-LSTM-CRF models can effectively utilize past and future input features. With the help of the CRF layer, it can also use sentence-level tagging information. The BI-LSTM-CRF model achieved state-of-the-art (SOTA) results on POS (Part-of-Speech tagging), chunking (semantic chunking), and NER datasets. At the same time, the BI-LSTM-CRF model is robust and has less dependence on word embeddings compared to previous models.
The article compares five models: LSTM, BI-LSTM, CRF, LSTM-CRF, BI-LSTM-CRF, LSTM: achieves memory units through input gates, forget gates, and output gates, effectively utilizing previous input features. BI-LSTM: can obtain contextual input features of time steps. CRF: uses functional sentence-level tag information, achieving high accuracy.
A classic model, the paradigm before BERT, can still be used with small datasets.
1.4.2 Stack-LSTM & Char-Embedding
Neural Architectures for Named Entity Recognition [3]
Stack-LSTM: Stack-LSTM directly constructs multi-word named entities. Stack-LSTM adds a stack pointer to LSTM. The model includes chunking and NER (Named Entity Recognition).
1. The stack contains three: output (output stack/completed part), stack (temporary stack), buffer (unprocessed word stack).
2. Three operations (actions):
-
SHIFT: Move a word from buffer to stack;
-
OUT: Move a word from buffer to output;
-
REDUCE: Pop all words from the stack to form a chunk, tag it with label y, and push it to output.
3. The model trains to obtain the conditional probability distribution of each step’s action, where the label is the probability distribution of the true action at each step. During prediction, the action with the highest probability is executed.
4. After outputting the chunk during the REDUCE operation, encode the chunk using LSTM to output its vector representation, then predict its label.
For examples, see the illustration:
Stack-LSTM is derived from: Transition-based dependency parsing with stack long-short-term memory [4]
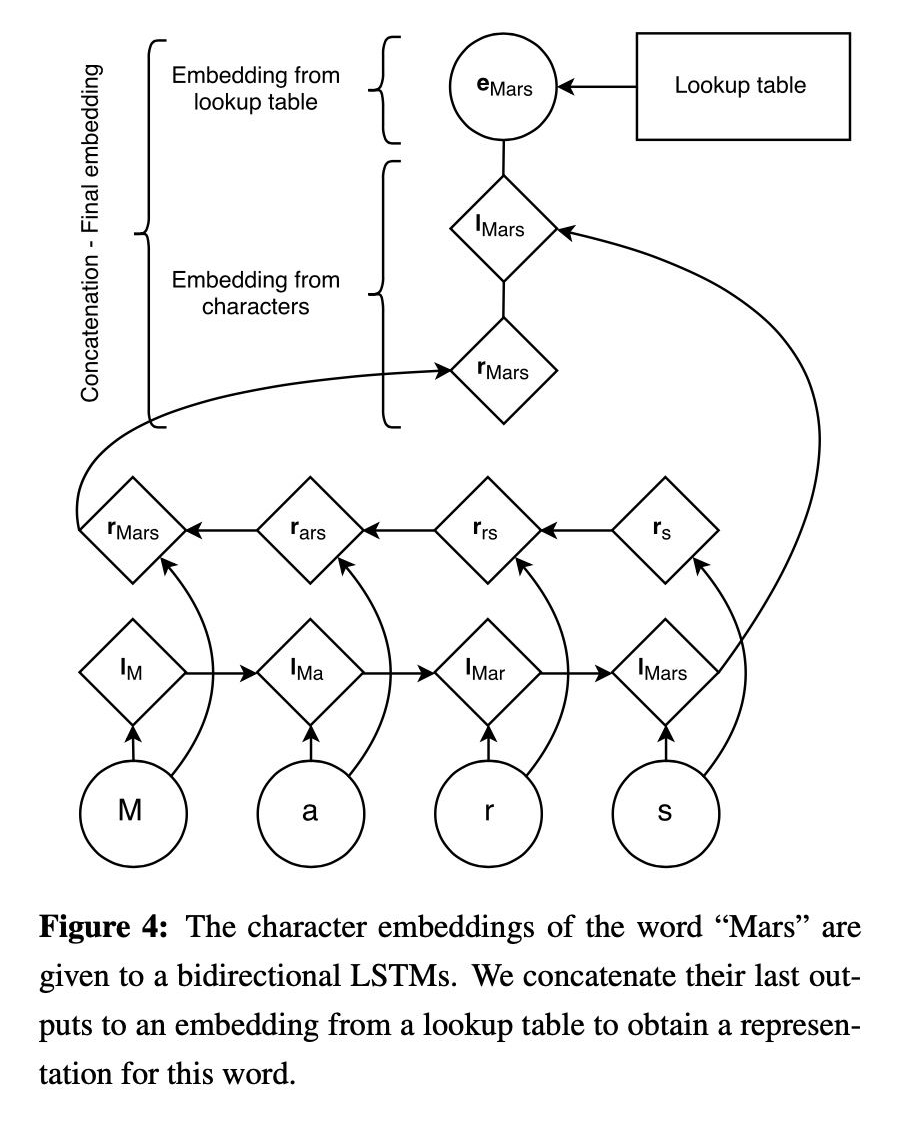
Also using initialized char-embedding, for each word, the character encoding is input through BI-LSTM, outputting the character-level representation of the word, then concatenating the word vector into BI-LSTM + CRF.
1.4.3 CNN + BI-LSTM + CRF
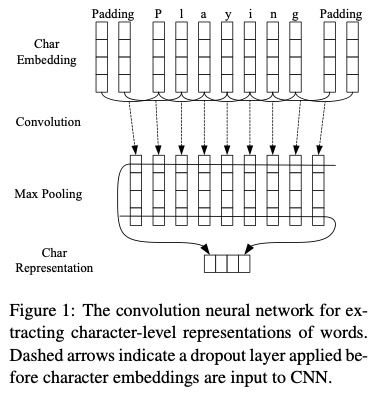
End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF [5]
Use CNN to obtain character-level word representations. CNN is a very effective way to extract morphological information of words (such as prefixes and suffixes) for encoding, as shown in the figure.
Then concatenate the character-level encoding vector from CNN with the word-level vector, inputting it into the BI-LSTM + CRF network, similar to the previous method. Overall network structure:
1.4.4 IDCNN
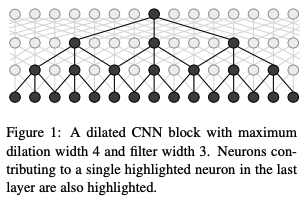
2017 Fast and Accurate Entity Recognition with Iterated Dilated Convolutions [6]
To address the slow decoding speed of Bi-LSTM, this paper proposes the ID-CNNs network as a replacement for Bi-LSTM, maintaining accuracy comparable to Bi-LSTM-CRF while achieving a speedup of 14-20 times. The decoding speed at the sentence level is 8 times faster compared to Bi-LSTM-CRF.
Disadvantages of CNN: The contextual information of CNN depends on the size of the window. Although increasing the number of CNN convolution layers can eventually allow each token to obtain the entire input sentence as contextual information, its output resolution performance is too poor.
Thus, dilated convolutions emerged: for dilated convolutions, effective input width can grow exponentially with depth, without resolution loss at each layer, and can estimate a certain number of parameters.
1.4.5 Capsule Networks
Joint Slot Filling and Intent Detection via Capsule Neural Networks [7]
Git: https://github.com/czhang99/Capsule-NLU
Two important tasks in NLU are intent detection and slot filling. Current methods, whether pipeline or joint training, do not explicitly model the hierarchical relationships between characters, slots, and intents.
This paper proposes applying capsule networks and dynamic routing-by-agreement to the joint tasks of slot filling and intent detection.
1. Use hierarchical capsule networks to encapsulate the hierarchical relationships between characters, slots, and intents.
2. Propose a rerouting dynamic routing scheme to model slot filling.
The network is divided into WordCaps, SlotCaps, and IntentCaps. For the principles of capsule networks, refer to: Dynamic Routing Between Capsules [8]
WordCaps: For input , the input BI-LSTM encodes it into T capsule vectors , which is no different from ordinary BI-LSTM:
SlotCaps: Here are k slotCaps, corresponding to k NER labels. The author uses the dynamic routing weight of the t-th wordCap for the k-th slotCap as the probability of the t-th word’s NER prediction label. The initial vector:
Using the dynamic routing algorithm, update the weights:
The final loss for slot filling is:
IntentCaps: The input is the output capsule vector of slotCaps, the expression vector of the k-th slotCap for the l-th intentCap:
Similarly, the output capsule vector is obtained through the dynamic routing algorithm, with the magnitude of the vector as the probability of belonging to class l:
The loss uses max-margin Loss:
Re-Routing: To provide intent information for NER, a Re-Routing mechanism is proposed, which is similar to the dynamic routing mechanism, with the only change being that the weight update also uses , where is the capsule vector with the largest norm.
1.4.6 Transformer
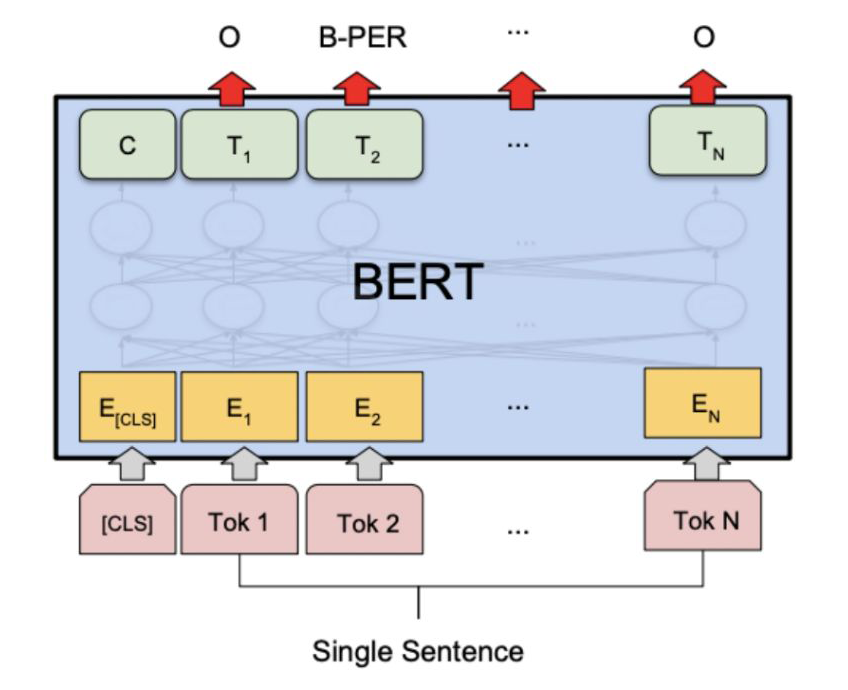
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [10]
To put it simply, it’s BERT, before BERT, there was the long-standing bilstm+crf, and after BERT, it basically had little relevance, the principles of BERT are not elaborated here, and its application in NER tasks is also very simple, just look at the figure, each token’s output is classified directly:
1.5 Semantic Features
1.5.1 Char-Embedding
Neural Architectures for Named Entity Recognition [9]
Decompose English characters into letters, encoding each letter of the word as a sequence, the encoder can use RNN, CNN, etc.
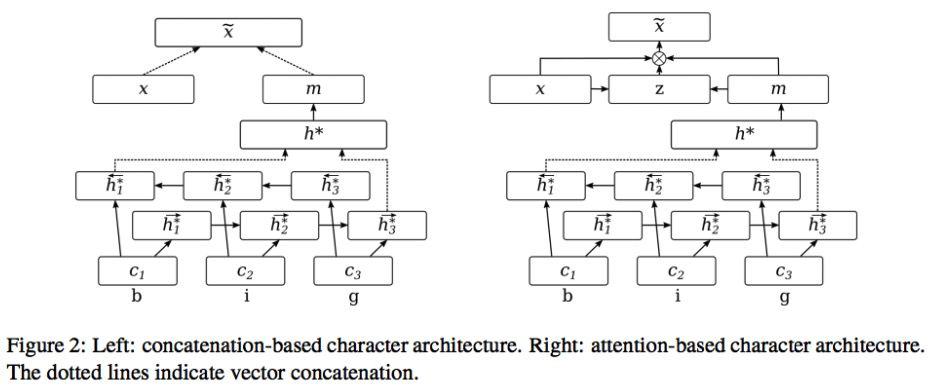
1.5.2 Attending to Characters in Neural Sequence Labeling Models
Attending to Characters in Neural Sequence Labeling Models [12]
Utilize a combination of word-level or character-level embeddings and use an attention mechanism to “flexibly select information” between the two embeddings, whereas previous models directly concatenated the two embeddings.
Directly look at the formula, z is a dynamic weight:
And add an additional loss on cross-entropy:
For non-OOV words, the closer m and x are, the better.
Char-embedding learns a more general representation among all words, while word-embedding learns specific word information. For frequently occurring words, it can directly learn the word representation, and the two will be more similar.
1.5.3 Radical-Level Features
Character-Based LSTM-CRF with Radical-Level Features for Chinese Named Entity Recognition [13]
This is also a char embedding method, which decomposes each Chinese character into its radicals, for example, “朝” will be decomposed into characters: 十、日、十、月. The subsequent structure is similar.
1.5.4 n-gram Prefixes and Suffixes
Named Entity Recognition with Character-Level Models [14]
Extract the prefixes and suffixes of each word as features of the word, for example: “aspirin” extracts 3-gram prefixes and suffixes: {“asp”, “rin”}.
Includes two parameters: n, T. n represents the n-gram size, T is the threshold, indicating that the suffix or prefix appears at least T times in the corpus.
1.6 Multi-Task Joint Learning
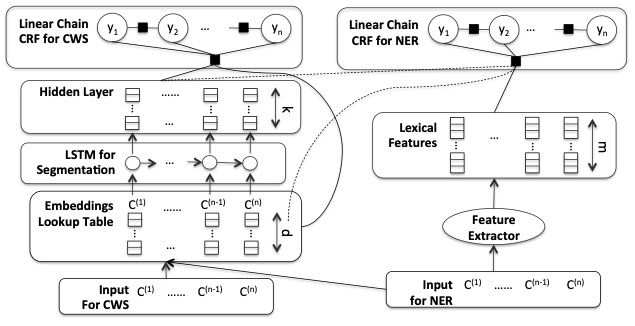
1.6.1 Joint Word Segmentation Learning
Improving Named Entity Recognition for Chinese Social Media with Word Segmentation Representation Learning [15]
Combine Chinese word segmentation and NER tasks. Use the predicted segmentation labels as one of the features for NER input, providing richer boundary information for the NER system.
Word segmentation corpora are currently abundant. If the target domain data is relatively small, it is advisable to use segmented corpora as the source domain to pre-train a lower-level encoder and then fine-tune on the target domain data with the joint segmentation task.
1.6.2 Joint Intent Learning
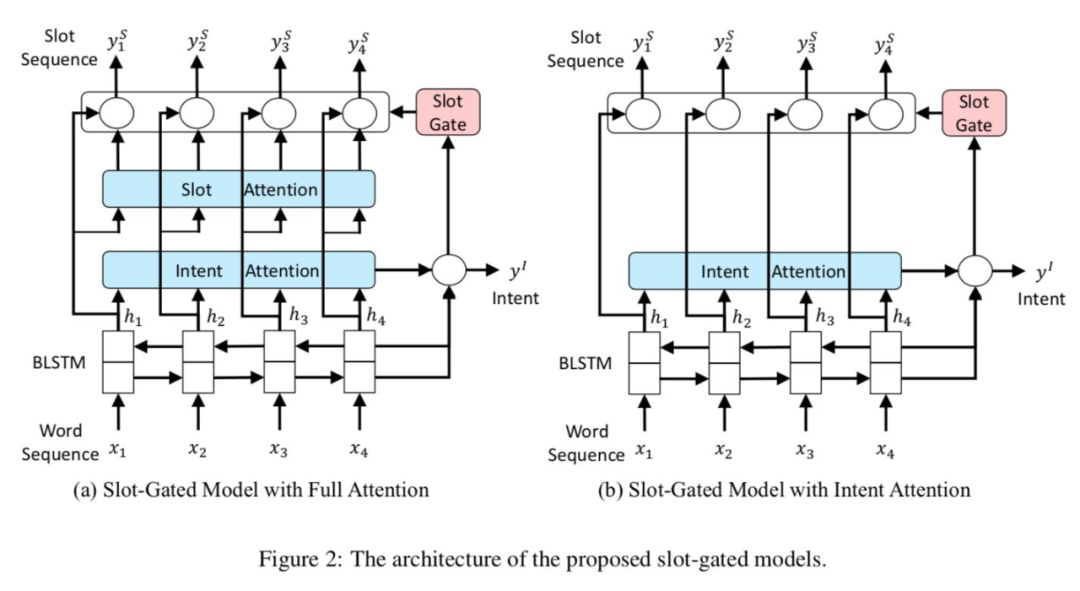
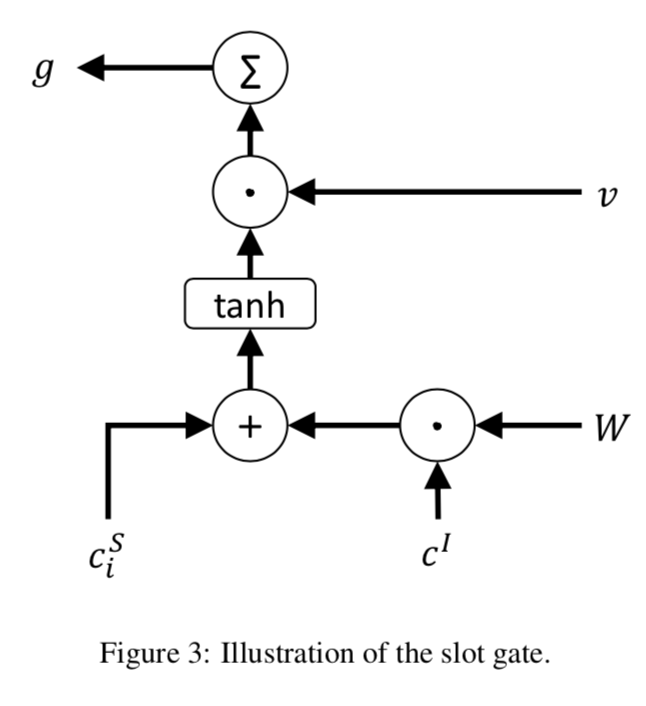
slot-gated
Slot-Gated Modeling for Joint Slot Filling and Intent Prediction [16]
The slot-gated paper proposes the slot-gate to model the relationship between slots and intents while also using the attention method, so this paper introduces this article directly together with attention, previous attention-related content will not be introduced.
Basic features: Using a BiLSTM structure, input:
, output: .
Slot filling attention weight calculation:
, and consistent., calculates the relationship between and the current input vector . The author’s TensorFlow source code uses convolution implementation, while uses linear mapping _linear(). T is the attention dimension, usually consistent with the input vector.
Intent Prediction: Its input is the output of the last unit of BiLSTM and its corresponding context vector, c is calculated in the same way as slot filling, equivalent to i=T.
For specific details of Attention, see: Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling [19], blog:
https://blog.csdn.net/shine19930820/article/details/109756345?spm=1001.2014.3001.5501
Utilize the intent context vector to model the relationship between slots and intents to improve slot filling performance. As shown in Figure 3:
The context vector of the slot and the context vector of the intent are combined through a gate structure (where v and W are both trainable):
, d is the dimension of the input vector h.
, obtain the weights of .
The paper’s source code uses:
Use g as the weight vector for predicting :
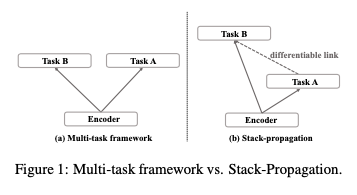
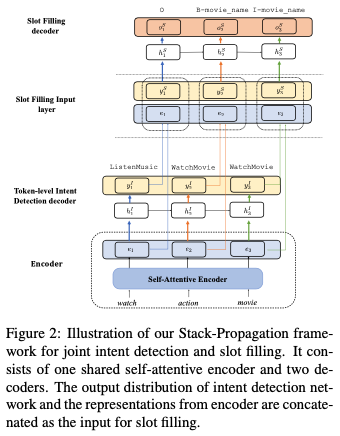
Stack-Propagation
A Stack-Propagation Framework with Token-level Intent Detection for Spoken Language Understanding [18]Git: https://github.com/%20LeePleased/StackPropagation-SLU
First, what is Stack-Propagation? As shown in the figure below:
It is different from multi-tasking, where different tasks are optimized together in a stacked manner.
Then, this paper inputs the output of the intent task stack into the NER task, specifically doing:
-
Token intent (intent phase): Assume that each token will have a probability distribution of intent (the label is the intent of the sentence, trained with a large amount of data to learn the intent distribution of each token, determining each token’s ‘preference’), the final intent prediction of the sentence is determined by voting on the intent prediction results of each token.
-
Slot Filling: The input includes the following three parts:
, where is the intent ID of the predicted result from the previous stage token intent, then transformed into an intent vector through an intent vector matrix, inputting it to the entity prediction module, the decoder is a layer of lstm+softmax.
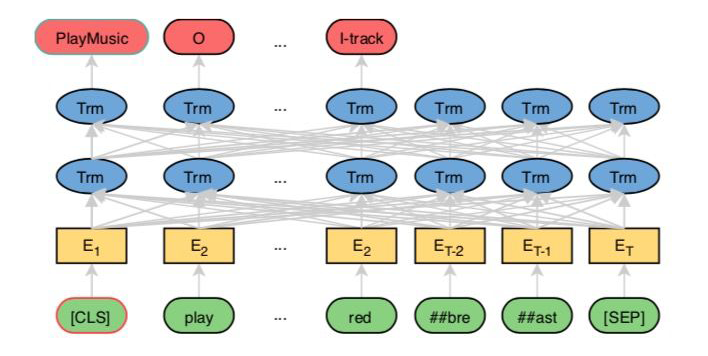
1.6.3 BERT for Joint Intent Classification and Slot Filling
BERT for Joint Intent Classification and Slot Filling [19]
The principle is shown in the figure, the lower-level encoder uses BERT, the output vectors of tokens directly classify the sequence labels, cls vector predicts the intent.
After BERT, it seems that some previous optimizations have become tricks, so are there no new methods? Before BERT, entity recognition was based on sequence labeling, was there no other decoding method? Regarding the present state of NER, let’s continue.
This section will unfold from the following aspects:
The decoders categorized here do not seem to fit well, but no better options were found.
Sequence labeling transforms the entity recognition task into a classification task for each token in the sequence, such as softmax, crf, etc. Recently, many new decoding methods have emerged compared to the sequence labeling decoding method.
SpanNER: Named Entity Re-/Recognition as Span Prediction [20]
Coarse-to-Fine Pre-training for Named Entity Recognition [21]
The essence is to predict the starting and ending nodes of entities, that is, for each token, it will predict whether it is the start and end of a certain entity. For multiple entity types, there are two ways:
1. For each token, it will predict start and end, for start, it is a multi-class (N+1) task, where N is the number of entities:
2. For each category, predict the corresponding start and end.
The advantage of this method is that it can solve the entity nesting problem. However, it also has a disadvantage, predicting the start and end of entities independently (theoretically, start and end should be considered jointly), making it easy to decode non-entities during the decoding phase, for example:
The token “林” predicts start, “伟” predicts end, so “林丹对阵李宗伟” can also be decoded as an entity.
Therefore, span is more suitable for entity recall, or when there is only one entity in the sentence (this situation should be rare), so reading comprehension tasks generally use functional span as decoding.
2.1.2 MRC (Reading Comprehension)
A Unified MRC Framework for Named Entity Recognition [22]
This method is interesting; when we want to recognize entities in a sentence, it can actually be done through a question-and-answer approach. The decoding phase can still use crf or span. For example:
Question: Who is the character described in the sentence?; Sentence: 林丹在伦敦夺冠; Answer: 林丹;
In my subjective opinion, this is impractical, for the following reasons:
-
For different entities, it is necessary to construct question templates, but how to construct question templates? If constructed manually, the quality of the questions will directly affect entity recognition.
-
Increased computational load; the original input is the length of the sentence, but now it is the length of the question plus the sentence.
-
Span has its issues (of course, it also has advantages), or the decoder uses crf.
2.1.3 Span Arrangement + Classification
Span-Level Model for Relation Extraction [23]
Instance-Based Learning of Span Representations [24]
In fact, span is still categorized as a classification task for tokens, while span arrangement + classification is directly for all possible spans, inputting span-level features and outputting the entity category. Span arrangement will classify all possible token combinations as input, for example:
Span-level features generally include:
-
Encoding of the span, pooling or concatenation of start and end vectors, generally preferring the latter.
-
The length of the span, then converted to a vector through the embedding matrix.
-
Sentence features, such as cls vector.
For the model, refer to this model, where phases a and b are entity recognition:
SpERT: Span-based Joint Entity and Relation Extraction with Transformer Pre-training [25]
-
For sentences of length N, if length is not restricted, there will be N(N+1)/2 combinations; in long texts, there will be extremely many spans, leading to a large computational load, and an abundance of negative samples while positive samples are scarce.
-
If candidate span length is restricted, then the length is not flexible.
In fact, having just mentioned that span is suitable for candidate recall, predicting the results of span and then recognizing them through classification is also a viable method.
This part mainly refers to incorporating knowledge into pre-trained models, one method is through adaptive pretraining on target domain data [26], for example, using dialogue corpora for adaptation pretraining.
The other method is to introduce entity and word entity information during the pre-training stage; this part of the paper is quite homogeneous, for example, nezha/ernie/bert-wwm, taking ernie as an example, it incorporates knowledge information into the training task, ERNIE proposes a knowledge masking strategy to replace BERT’s mask, which includes entity-level and phrase-level masking, as shown below:
Basic-Level Masking: Similar to BERT, randomly select tokens to mask.
Phrase-Level Masking: Masks phrases in syntax, such as: a series of|such as, etc.
Entity-Level Masking: Masks entire entities, mainly including people, places, organizations, product names, etc.
The training data includes Chinese Wikipedia, Baidu Encyclopedia, Baidu News (latest entity information), and Baidu Tieba.
2.2.2 Explicit Fusion
This part of explicit fusion mainly refers to introducing knowledge at the model data level.
Trie Tree Matching Results as Features
This part is relatively simple, which is to use the word information matched through rules from the sentence as prior input; if for domain-specific NER, this method can be used.
Refer to the dictionary matching method discussed in the previous section.
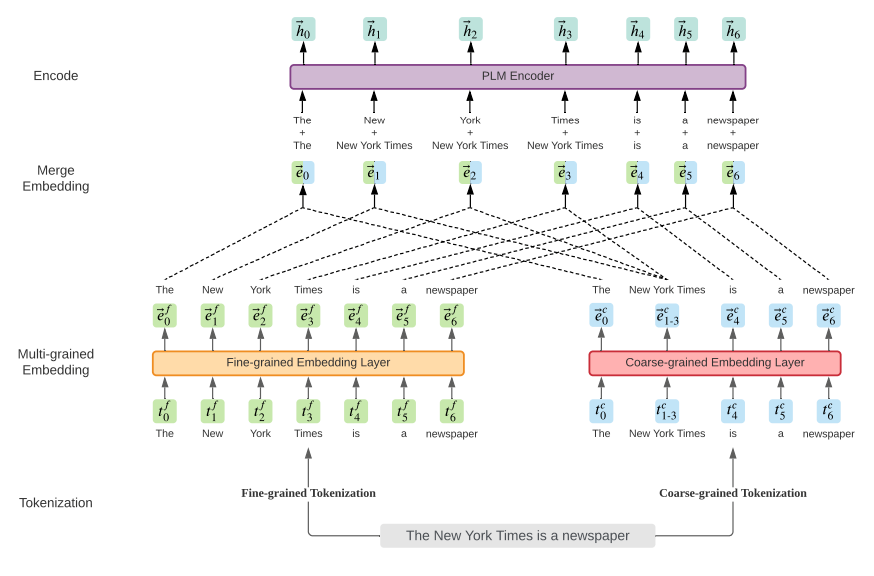
Fusion of Word Segmentation Information (multi-grained: fine-grained and coarse-grained)
Multi-grained translation should be multi-grained, but personally, I think it mainly incorporates segmentation information, as BERT uses characters.
In Chinese, both words and characters can be used as granularity for BERT input, each with its advantages and disadvantages. So is it possible to fuse both input methods?
Early Fusion:
LICHEE [27]: Early fusion refers to merging at the input embedding level, using max-pooling to fuse two granularities (word and character granularity):
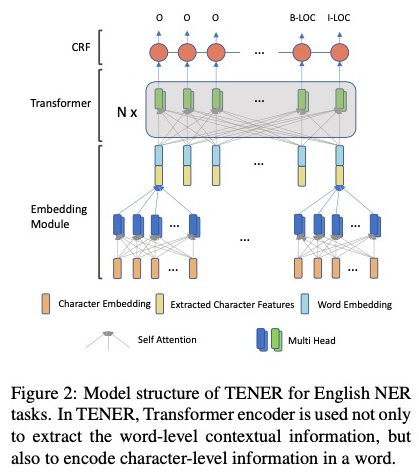
TNER [28]: Improved the Transformer encoder to better model character-level and word-level features. By introducing direction-aware, distance-aware, and un-scaled attention, the modified Transformer encoder can significantly enhance NER tasks.
The article interestingly analyzes the attention mechanism of Transformers, finding that it is not well-suited for NER tasks in terms of directionality, relative positioning, and sparsity.
Embedding incorporates both word embedding and character embedding, with character embedding extracting n-gram and some non-contiguous character features after passing through the Transformer encoder.
Calculating self-attention includes relative position information, but it is not directional, and after passing through the W matrix mapping, the characteristic of relative position information also disappears. Thus, it is proposed to calculate attention weights by separately computing word vectors and position vectors:
Removed the scaled calculation in attention, believing it performs better.
FLAT [29]: Combines lattice structures and Transformers to solve the extra errors introduced by word segmentation in Chinese and can utilize parallelization to enhance inference speed. As shown in the figure, potential words matched through the dictionary (lattice) are appended to the end, then associated with tokens in the original sentence through start and end position encoding.
Additionally, the attention’s relative position encoding is modified (adding direction and relative distance) and attention calculation methods (adding distance features), similar to TNER. A subsequent paper, Lattice BERT, has nearly identical content.
Mid-stage Fusion
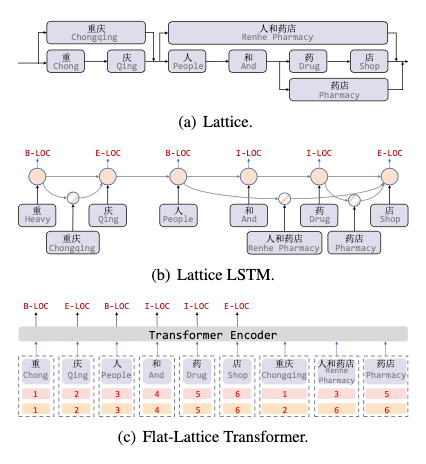
ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations [30]
This refers to incorporating word and character outputs into certain layers of the encoder. In the middle layer of char, N-gram embedding inputs are added.
This n-gram added to the char output may leak information, for example, mlm predicting “粤” when incorporating “港澳”, “粤港澳”, “粤港澳大湾区” may leak answers when predicting “粤”. Smart partners might say to mask the entire word directly, but if “粤港澳大湾区” is masked, it may find most of the sentence masked, making it difficult for the model to learn. Another approach is to modify the attention visibility matrix.
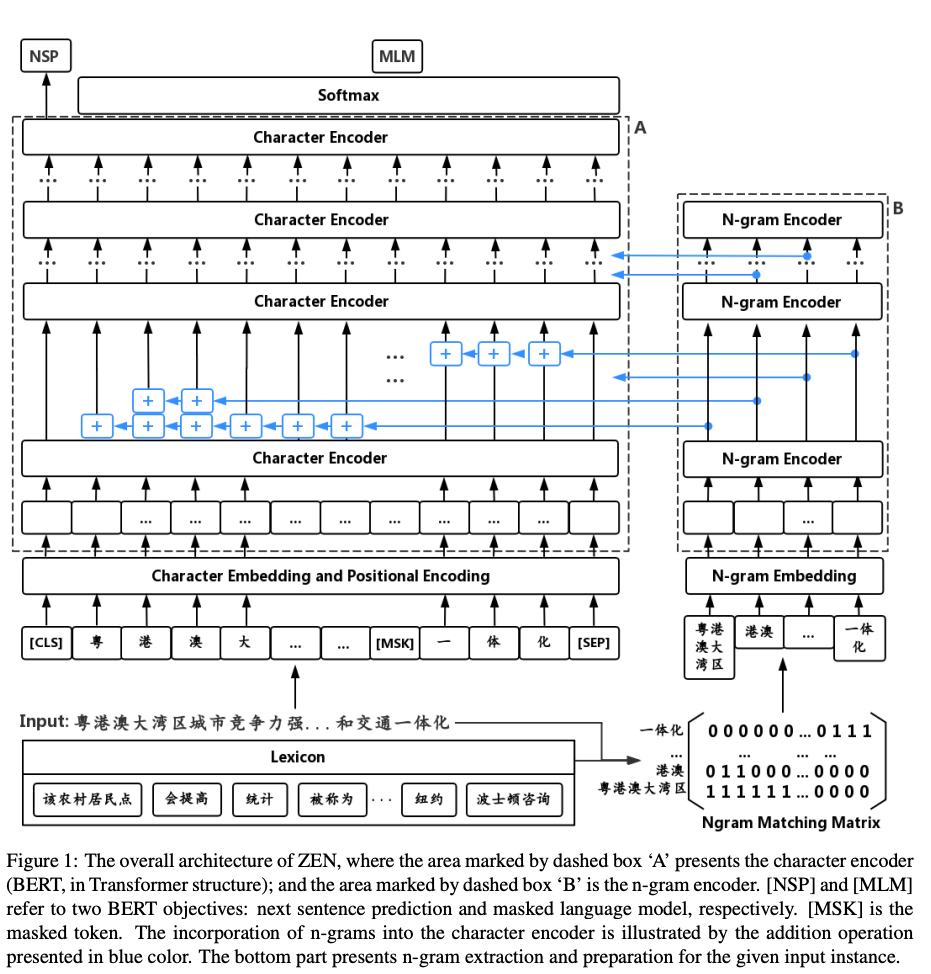
Ambert [31]: Each character and word passes through a shared encoder, then the coarse and fine-grained outputs are fused, finding the output unsuitable for NER tasks, more suitable for classification tasks.
Fusion of Knowledge Graph Information
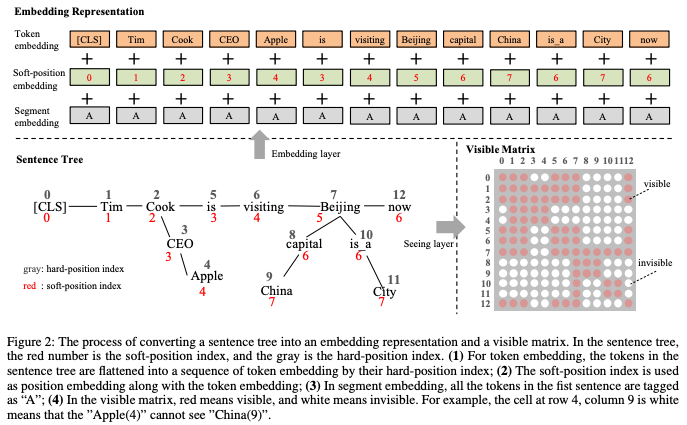
K-BERT: Enabling Language Representation with Knowledge Graph [32]
Knowledge graphs contain entities, entity types, and relationships (edges) between entities. How to incorporate this information into the input? K-BERT uses a very direct method, as shown in the figure below:
For example, in the sentence, cook is the CEO of apple, directly inserting it into the sentence would disrupt the sentence order, and additionally, it introduces extra information interference for other tokens. Therefore, it proposes two methods to solve this problem.
-
Position encoding, maintaining the original sentence’s position unchanged, thus the sequence remains unchanged, while the positions of inserted “CEO”, “Apple”, and “cook” are continuous, ensuring that the knowledge from the graph is inserted in the correct position.
-
Simultaneously, for subsequent tokens, “CEO”, “Apple” belong to noise, thus using a visibility matrix mechanism to make “CEO”, “Apple” invisible to subsequent tokens and also invisible to [CLS].
2.3 Annotation Missing
First, regarding NER annotation, due to the high cost of annotated data, distant supervision is often used for labeling. However, distant supervision dictionaries can cause high accuracy but low recall, leading to many unannotated issues?
Moreover, even with annotations, the absence of entity annotations is a common phenomenon. Aside from correcting the data (which is too costly), is there any other way?
2.3.1 AutoNER
Learning Named Entity Tagger using Domain-Specific Dictionary [33]
Better Modeling of Incomplete Annotations for Named Entity Recognition [34]
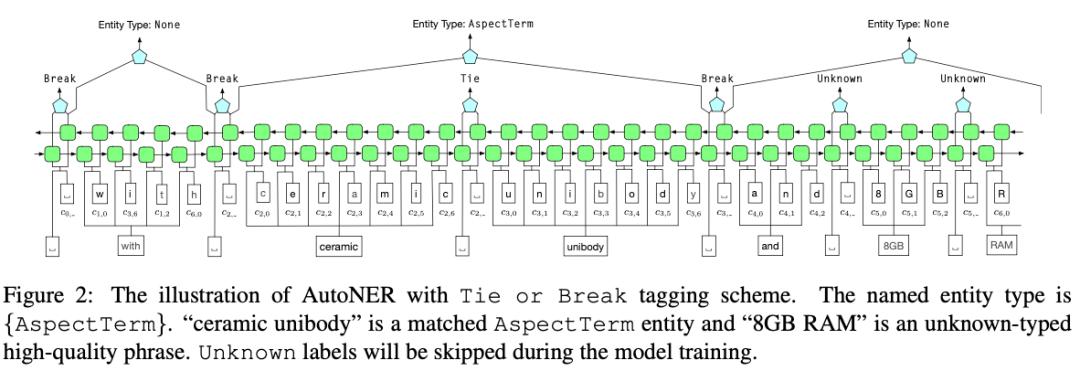
When using dictionaries for distant supervised labeling of entities, due to the limited dictionaries, it generally causes high accuracy but low recall (unlabeled) in the annotated data. To address the unannotated issues in the data, AutoNER with the “Tie or Break” method is proposed.
The specific algorithm is illustrated, where:
1. Tie: For two adjacent tokens, if they belong to the same entity, they are Tie.
2. Unknown: Among two adjacent tokens, if one belongs to an unknown type of high-confidence entity, high-confidence entities are mined using AutoPhrase [35].
3. Break: Does not belong to the above situation, i.e., not the same entity.
4. Tokens between two Breaks are treated as entities, needing to identify their corresponding categories.
5. When calculating loss, Unknown is not counted (mainly to alleviate the false negative problem).
Even if distant supervision incorrectly marks boundaries, the majority of ties within the entity are still correct.
My understanding of the starting point: 1. The proposal of tie or break aims to solve the boundary labeling error problem, and not calculating loss for Unknown alleviates the false negative problem.
However, there is a problem; the paper mentions that the false negative samples come from high-quality phrases, but these high-quality phrases are based on statistics, so they may not cover low-frequency entities well.
Another paper has a similar idea: Training Named Entity Tagger from Imperfect Annotations [36], which includes two steps in each iteration:
1. Error Identification: Identify possible label errors in the training dataset through cross-training.
2. Weight Reset: Reduce the weight of sentences with erroneous annotations.
2.3.2 PU Learning
Distantly Supervised Named Entity Recognition using Positive-Unlabeled Learning [37]
This mainly addresses the issues of dictionary under-labeling or discontinuous labeling, reducing the requirements for dictionary construction. Unbiased positive-unlabeled learning precisely solves the situation where there are positive and negative examples among unlabeled samples; the author defines it as:
is the negative example, unlabeled samples belong to positive examples , solving the unannotated problem is how to estimate without negative samples.
Why not use negative samples? Because negative samples may ensure that unlabeled positive samples are present.
The author transforms it into:
So I can just learn positive samples directly, no problem. Here, one can roughly guess that the author will use a method similar to out-of-domain.
However, I feel something is off; you are only learning the labeled positive samples, but not the unlabeled positive samples.
Sure enough, for each label of positive samples, construct different binary classifiers to learn whether they belong to positive samples.
I am not being contrary, but unlabeled entities will still affect the binary classification.
2.3.3 Negative Sampling
Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition [38]
Unlabeled data can cause two types of problems: 1) Reducing the number of positive samples. 2) Treating unlabeled data as negative samples. 1 can be alleviated through adaptive pretraining, while 2 can have more serious consequences, misleading the model. How to eliminate this misguidance? That is negative sampling.
This NER framework uses the previously introduced span arrangement classification framework, where each span will have an entity type for classification, making it more suitable for negative sampling.
Negative sampling: For all non-entity span combinations, down-sampling is used because non-entity span combinations may contain positive samples, so negative sampling can alleviate unannotated issues to some extent. Note that it is alleviation, not resolution. The loss function is as follows:
Where the front part is the positive sample, the back part is the negative sample loss, is the sampled negative sample set. The method is quite straightforward, and I think it is more effective than PU learning. The author also proves that through negative sampling, the probability of not treating unlabeled entities as negative samples is greater than (1-2/(n-5)), alleviating the unlabeled problem.
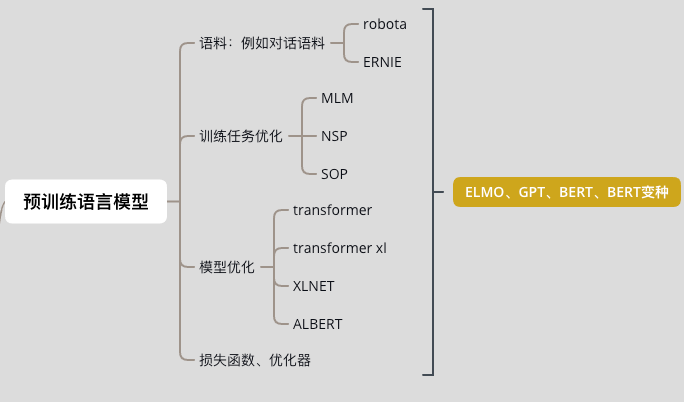
2.4 Pre-trained Language Models
This mainly concerns BERT-related optimizations. For downstream tasks, including NER, there are improvements, so I will not elaborate, see the figure:
[1] Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data
[2] Bidirectional LSTM-CRF Models for Sequence Tagging: https://arxiv.org/abs/1508.01991v1
[3] Neural Architectures for Named Entity Recognition: https://arxiv.org/abs/1603.01360
[4] Transition-based dependency parsing with stack long-short-term memory: http://www.oalib.com/paper/4074644
[5] End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF: https://www.aclweb.org/anthology/P16-1101.pdf
[6] Fast and Accurate Entity Recognition with Iterated Dilated Convolutions: https://arxiv.org/abs/1702.02098
[7] Joint Slot Filling and Intent Detection via Capsule Neural Networks: https://arxiv.org/abs/1812.09471
[8] Dynamic Routing Between Capsules: http://papers.nips.cc/paper/6975-dynamic-routing-between-capsules.pdf
[9] Neural Architectures for Named Entity Recognition: https://arxiv.org/abs/1603.01360
[10] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding: https://arxiv.org/abs/1810.04805
[11] Neural Architectures for Named Entity Recognition: https://arxiv.org/abs/1603.01360
[12] Attending to Characters in Neural Sequence Labeling Models: https://arxiv.org/abs/1611.04361
[13] Character-Based LSTM-CRF with Radical-Level Features for Chinese Named Entity Recognition: http://www.nlpr.ia.ac.cn/cip/ZongPublications/2016/13董传海Character-Based%20LSTM-CRF%20with%20Radical-Level%20Features%20for%20Chinese%20Named%20Entity%20Recognition.pdf
[14] Named Entity Recognition with Character-Level Models: https://nlp.stanford.edu/manning/papers/conll-ner.pdf
[15] Improving Named Entity Recognition for Chinese Social Media with Word Segmentation Representation Learning: https://www.aclweb.org/anthology/P16-2025
[16] Slot-Gated Modeling for Joint Slot Filling and Intent Prediction: https://aclanthology.org/N18-2118
[17] Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling: https://blog.csdn.net/shine19930820/article/details/83052232
[18] A Stack-Propagation Framework with Token-level Intent Detection for Spoken Language Understanding: https://www.aclweb.org/anthology/D19-1214/
[19] BERT for Joint Intent Classification and Slot Filling: https://arxiv.org/abs/1902.10909
[20] SpanNER: Named Entity Re-/Recognition as Span Prediction (https://arxiv.org/pdf/2106.00641v1.pdf)
[21] Coarse-to-Fine Pre-training for Named Entity Recognition (https://aclanthology.org/2020.emnlp-main.514.pdf)
[22] A Unified MRC Framework for Named Entity Recognition (https://arxiv.org/pdf/1910.11476v6.pdf)
[23] Span-Level Model for Relation Extraction (https://aclanthology.org/P19-1525.pdf)
[24] Instance-Based Learning of Span Representations (https://aclanthology.org/2020.acl-main.575)
[25] SpERT: Span-based Joint Entity and Relation Extraction with Transformer Pre-training (https://arxiv.org/abs/1909.07755)
[26] https://medium.com/jasonwu0731/pre-finetuning-domain-adaptive-pre-training-of-language-models-db8fa9747668
[27] https://arxiv.org/pdf/2108.00801.pdf
[28] https://arxiv.org/pdf/1911.04474.pdf
[29] https://arxiv.org/pdf/2004.11795.pdf
[30] ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations (https://arxiv.org/abs/1911.00720)
[31] https://arxiv.org/pdf/2008.11869.pdf
[32] K-BERT: Enabling Language Representation with Knowledge Graph (https://arxiv.org/pdf/1909.07606.pdf)
[33] Learning Named Entity Tagger using Domain-Specific Dictionary (https://arxiv.org/abs/1809.03599)
[34] Better Modeling of Incomplete Annotations for Named Entity Recognition (https://aclanthology.org/N19-1079.pdf)
[35] https://arxiv.org/abs/1702.04457
[36] Training Named Entity Tagger from Imperfect Annotations (https://arxiv.org/abs/1909.01441)
[37] Distantly Supervised Named Entity Recognition using Positive-Unlabeled Learning (https://arxiv.org/abs/1906.01378)
[38] Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition (https://arxiv.org/pdf/2012.05426)
About Us
MLNLP(Machine Learning Algorithms and Natural Language Processing) is a civil academic community jointly built by scholars in natural language processing from home and abroad, which has now developed into one of the largest natural language processing communities in China and abroad, gathering over 500,000 subscribers, including well-known brands such as Ten Thousand People Top Conference Exchange Group, AI Selection, AI Talent Exchange, and AI Academic Exchange, aiming to promote progress among the academic and industrial circles of machine learning and natural language processing enthusiasts.
The community can provide an open communication platform for relevant practitioners in further studies, employment, and research. Everyone is welcome to follow and join us.