Author: Dale Markowitz
Translation: Wang Kehan
Proofreading: He Zhonghua
This article is approximately 3800 words long and is recommended to be read in 5 minutes
This article introduces the currently most popular language model in natural language processing—the Transformer model.
Tags: Natural Language Processing
Do you know this saying: When you have a hammer, everything looks like a nail? In machine learning, we seem to have found a magical hammer. In fact, everything is a nail in front of this model, and that is the Transformer model. The Transformer model can be used to translate text, write poetry, compose articles, and even generate computer code. In fact, many of the amazing research I have written at daleonai.com is built on the foundation of Transformers, such as AlphaFold 2, which is a model that predicts protein structures from gene sequences, as well as powerful natural language processing (NLP) models like GPT-3, BERT, T5, Switch, and Meena. You might say they didn’t just encounter… uh, let’s move on.
If you want to keep up with machine learning, especially in natural language processing, you need to have at least a basic understanding of Transformers. So in this article, we will discuss what they are, how they work, and why they are so influential.
The Transformer is a type of neural network architecture. In simple terms, a neural network is a very effective model for analyzing complex data types such as images, videos, audio, and text. There are specialized neural networks optimized for different types of data. For example, when analyzing images, we typically use Convolutional Neural Networks (CNNs). In general, they mimic the way the human brain processes visual information.
Convolutional Neural Networks, image from Renanar2, Wikimedia Commons
Since around 2012, we have successfully addressed visual problems using CNNs, such as recognizing objects in photos, identifying faces, and handwritten digit recognition. However, for a long time, language tasks (translation, text summarization, text generation, named entity recognition, etc.) did not have effective methods. This is unfortunate because language is our primary means of human communication.
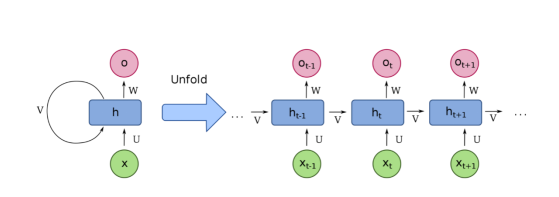
Before the introduction of Transformers in 2017, the method we used for understanding text with deep learning was a model called Recurrent Neural Networks (RNNs), which looked like this:
Recurrent Neural Networks, image from fdeloche, Wikimedia
Suppose you want to translate a sentence from English to French. RNNs take an English sentence as input, process one word at a time, and then output the corresponding French words in order. The key word here is “order.” In language, the order of words is important; you cannot rearrange them arbitrarily. For example, the following sentences:
“Jane went looking for trouble.” means something very different from: “Trouble went looking for Jane.”
Therefore, any model that can understand language must capture word order, and RNNs do this by processing one word at a time in a sequence.
However, RNNs have issues. First, they struggle to handle long text sequences, such as long paragraphs or articles. When they reach the end of a paragraph, they forget what happened at the beginning. For example, an RNN-based translation model might have difficulty remembering the gender of the subject in a long paragraph.
Worse, RNNs are difficult to train. They are prone to the so-called vanishing/exploding gradient problem (sometimes you just have to restart training and pray). More problematic is that because RNNs process words sequentially, they are hard to parallelize. This means you cannot speed up training by adding more GPUs, which also means you cannot train them on as much data.
This is where Transformers shine. They were developed by researchers at Google and the University of Toronto in 2017, initially designed for translation. But unlike RNNs, Transformers can be very effectively parallelized. This means that, with the right hardware, you can train some very large models.
How large? Extremely large!
GPT-3 is a particularly impressive text generation model, with writing abilities almost on par with humans, trained on 45TB of text data, including almost all public web data.
So, to summarize Transformers in one sentence: When a highly scalable model meets a massive dataset, the results can be astonishing.
How Do Transformers Work?
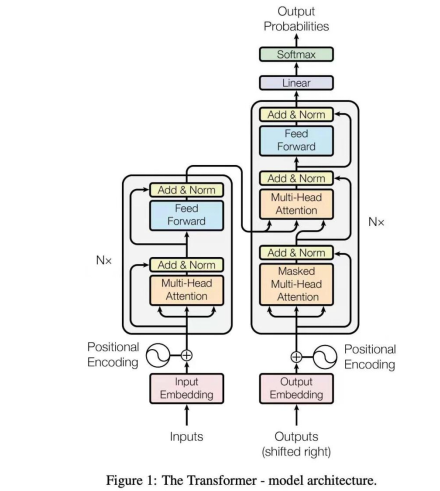
Transformer, image from the original paper: https://arxiv.org/abs/1706.03762
Although the diagrams in the original paper might look intimidating, the innovations behind Transformers can be summarized into three main concepts:
3. Self-Attention Mechanism
Let’s start with the first one, positional encodings. Suppose we want to translate text from English to French. Recall that the previous method, RNNs, understood word order by processing words sequentially. But this is also what makes them difficult to parallelize.
Transformers bypass this obstacle with an innovative approach called positional encoding. The idea is to add a number indicating the position of each word in the input sequence—all the words in this case are an English sentence. So, you provide your network with the following sequence:
[("Dale", 1), ("says", 2), ("hello", 3), ("world", 4)]
Conceptually, you shift the burden of understanding word order from the neural network’s structure to the data itself.
Initially, before training on any data, the Transformer does not know how to interpret these positional encodings. But as the model sees more and more sentences and their encodings, it learns how to use them effectively.
I’ve simplified this a bit—original authors used sine functions for positional encoding instead of simple integers 1, 2, 3, 4—but the point remains the same. Storing the order as data rather than relying on network structure makes your neural network easier to train.
The next important part of the Transformer is called the attention mechanism.
Attention is a neural network structure that is ubiquitous in machine learning. In fact, the paper that introduced Transformers in 2017 was not titled “We Present You the Transformer”; instead, it was called “Attention is All You Need.”
Attention is All You Need
https://arxiv.org/pdf/1706.03762.pdf
The attention mechanism was introduced in text translation in 2015. To understand it, refer to the example sentence in the original text:
The agreement on the European Economic Area was signed in August 1992.
Now imagine translating this sentence into French:
L’accord sur la zone économique européenne a été signé en août 1992.
For translating this sentence, a poor method would be to look at each word in the English sentence and try to translate the corresponding word in French one at a time. This does not work for several reasons, one of which is that some words in the French translation are reversed: in English, it is “European Economic Area,” while in French, it is “la zone économique européenne.” Additionally, French is a language with gendered vocabulary. The adjectives “économique” and “européenne” must be in feminine form to match the feminine noun “la zone.”
Attention is a mechanism that allows text models to “look at” every word in the original sentence when deciding how to translate the words in the output sentence. The following figure is a good visualization from the original attention paper:

Image from the paper, “Neural Machine Translation by Joint Learning to Align and Translate (2015)”, https://arxiv.org/abs/1409.0473
This is a heat map showing which words the model “pays attention to” when outputting each word in the French sentence. As you can imagine, when the model outputs “européenne,” it focuses on the input words “European” and “Economic.”
How does the model know which words to “pay attention to” at each time step? This is something learned from the training data. By observing thousands of French and English sentences, the model learns what types of words are interdependent and how to adhere to parts of speech, plurality, and other grammatical rules.
Since its discovery in 2015, the attention mechanism has been a very useful tool in natural language processing, but in its original form, it was used with RNNs. Therefore, the innovation of the 2017 Transformer paper was to largely discard RNNs. This is why the paper from 2017 is called “Attention is All You Need.”
The last point of the Transformer (perhaps the most influential one) is a variant of attention called self-attention.
The type of attention we just discussed helps match words between English and French sentences, which is important for translation. However, what if you are not trying to translate words but rather build a model capable of understanding the underlying meanings and patterns of language—one that can be used for a myriad of language tasks?
Generally, what makes neural networks powerful is that they tend to automatically build meaningful internal representations of the training data. For example, when you inspect different layers of a visual neural network, you find that different neurons are responsible for “recognizing” different patterns, such as edges, shapes, and even high-level structures like eyes and mouths. A model trained on textual data may have automatically learned parts of speech, grammatical rules, and whether words are synonyms.
The better the neural network learns internal representations of language, the better it performs on any language task. It turns out that applying the attention mechanism to the input text itself is also a very effective way to achieve this.
For example, consider the following two sentences:
“Server, can I have the check?”
“Looks like I just crashed the server.”
Here, the word “server” carries two very different meanings, and we humans can easily disambiguate it by looking at the surrounding words. Self-attention allows the neural network to understand the word in the context of the words around it. Thus, when the model processes “Server” in the first sentence, it might “pay attention” to the word “check,” which helps disambiguate that the word refers to a waiter rather than a machine.
In the second sentence, the model might pay attention to the word “crashed” to determine that this “server” refers to a machine.
Self-attention helps neural networks disambiguate words, perform part-of-speech tagging, named entity recognition, learn semantic roles, and more.
We have highly summarized and concluded the Transformer here.
If you want a more in-depth technical explanation, I highly recommend checking out Jay Alammar’s blog post, The Illustrated Transformer.
What Can Transformers Do?
One of the most popular Transformer-based models is BERT, which stands for “Bidirectional Encoder Representations from Transformers.” It was introduced by researchers at Google around the time I joined the company in 2018 and quickly became integral to almost all NLP projects, including Google Search.
BERT refers not only to the model architecture but also to the trained model itself, which you can download and use for free here.
Here
https://github.com/google-research/bert
Google’s researchers trained it on a massive text corpus, and it has become a general-purpose model for natural language processing. It can be scaled to address a variety of tasks, such as:
— Named entity recognition
— Offensive content/profanity detection
— Understanding user queries
BERT has demonstrated that you can build very good language models on unlabeled data, such as text extracted from Wikipedia and Reddit, and that these large “foundation” models can be adapted to specific domain data for many different use cases.
Recently, the ability of models created by OpenAI, like GPT-3, to generate realistic text has astonished many. Google’s Meena, launched last year, is a Transformer-based chatbot (ahem, conversational agent) that can engage in captivating dialogues on virtually any topic (its creators once spent 20 minutes debating what it means to be human with Meena).
Transformers have also sparked a wave beyond natural language processing, such as music composition, generating images from textual descriptions, and predicting protein structures.
Now that you have been captivated by the power of Transformers, you might be wondering how to use them in your own applications. No problem.
You can download common Transformer-based models like BERT from TensorFlow Hub. For code tutorials, check out my article on building semantic language applications.
Article
https://daleonai.com/semantic-ml
But if you want to really stay on the cutting edge and you write Python, I highly recommend the Transformers library maintained by HuggingFace. This platform allows you to train and use most of the popular NLP models today, like BERT, Roberta, T5, and GPT-2, in a very developer-friendly way.
That concludes today’s article!
Transformers, Explained: Understand the Model Behind GPT-3, BERT, and T5
https://towardsdatascience.com/transformers-explained-understand-the-model-behind-gpt-3-bert-and-t5-cdbf3fc8a40a?source=collection_home———0—————————-
Wang Kehan, a direct PhD student in the Department of Mechanical Engineering at Tsinghua University. With a background in physics, I developed a strong interest in data science during my graduate studies and am curious about machine learning and AI. I look forward to the unique sparks that artificial intelligence and mechanical engineering, along with computational physics, will create on my research journey. I hope to make friends and share more data science stories, viewing the world through the lens of data science.
Translation Team Recruitment Information
Job Description: We need a meticulous heart to translate selected foreign articles into fluent Chinese. If you are a data science/statistics/computer science student studying abroad, or working overseas in related fields, or confident in your foreign language skills, you are welcome to join the translation team.
What You Will Get: Regular translation training to improve volunteers’ translation skills, enhance their awareness of cutting-edge data science, and allow overseas friends to stay connected with domestic technological developments. The THU Data Team’s industry-academia background offers good development opportunities for volunteers.
Other Benefits: You will have the opportunity to work with data scientists from well-known companies and students from prestigious universities such as Peking University and Tsinghua University, as well as overseas institutions.
Click on “Read the Original” at the end of the article to join the Data Team~
Reprint Notice
If you need to reprint, please prominently indicate the author and source at the beginning of the article (Reprinted from: Data Team ID: DatapiTHU), and include a prominent QR code for Data Team at the end of the article. For articles with original identification, please send [Article Title – Awaiting Authorization Public Account Name and ID] to the contact email to apply for whitelist authorization and edit as required.
After publishing, please provide the link to the contact email (see below). Unauthorized reprints and adaptations will be legally pursued.
Click “Read the Original” to embrace the organization