Delivering NLP technology insights to you every day!
In this issue, we continue from the last issue on BERT Chinese short sentence similarity calculation Docker CPU image, continuing to use huggingface transformer and sentence-transformer libraries, generating BERT embeddings for English sentences, and then introducing the faiss library to establish an index and finally query the closest sentences.
Relevant Docker CPU image links are as follows
BERT Chinese short sentence similarity calculation Docker CPU image
How to Obtain the Docker Image
This issue’s method to obtain the Docker image is to follow the MyEncyclopedia WeChat account and reply with docker-faiss-transformer to get the complete command as follows.
docker run -p 8888:8888 myencyclopedia/faiss-demo bash -c 'jupyter notebook --allow-root --port 8888 --NotebookApp.token= --ip 0.0.0.0'Then open your browser and enter http://localhost:8888/notebooks/faiss_demo.ipynb
Introduction to FAISS
FAISS stands for Facebook AI Similarity Search, an open-source library developed by Facebook for dense vector matching. As the pioneer of vectorized retrieval, FAISS provides a solution for querying massive high-dimensional datasets, improving the problems of brute-force search algorithms in two ways: reducing space occupancy and speeding up retrieval. Additionally, FAISS offers several methods for data compression, including PCA and Product-Quantization.
Main Features of FAISS:
-
Supports similarity search and clustering; -
Supports multiple indexing methods; -
Supports both CPU and GPU computations; -
Supports calls from Python and C++;
FAISS Usage Process
Using FAISS is divided into two steps: the first step is to create an index file for the original vectors, and the second step is to perform vector search operations on the index file.
When creating the index file for the first time, it goes through the train and add processes; subsequently, if new vectors need to be added to the index file, only an add operation is required for incremental index updates. However, if the scale of the increment is similar to that of the original index, the entire vector space may have undergone some changes, at which point the entire index file needs to be recreated, meaning going through the train and add processes again with all vectors. The specifics of how to train and add depend on the particular index type.
1. IndexFlatL2 indexFlatIP
For exact searches, such as Euclidean distance faiss.indexFlatL2 or inner product distance faiss.indexFlatIP, there is no train process; you can directly add and then search.
import faiss
# Create index, defined as dimension d = 128
index = faiss.IndexFlatL2(d)
# add vectors, xb is a numpy array of size (100000,128)
index.add(xb)
print(index.ntotal)
# Number of vectors in the index, output 100000
# Find 4 nearest neighbors
k = 4
# xq is query embedding, size (10000,128)
D, I = index.search(xq, k)
## D shape (10000,4), representing the distance between each returned point's embedding and the query embedding,
## I shape (10000,4), representing the IDs of the k items closest to the query embedding,
print(I[:5])2. IndexIVFFlat
While the results from IndexFlatL2 are exact, the time complexity of brute-force search is quite high when the dataset is large. Therefore, we generally use other indexing methods to speed things up. For example, IndexIVFFlat divides the dataset into several parts during the train phase, a technical term known as Voronoi Cells, where each data vector can only fall into one cell. During search, we only need to query the data within the cell where the query vector falls, reducing the number of distance calculations. This process is essentially a high-dimensional KNN clustering algorithm. The search phase uses inverted indexing.
IndexIVFFlat requires a training phase, which is related to another index quantizer that determines which cell a vector belongs to. During the search phase, parameters nlist (number of cells) and nprob (number of cells to search) are introduced. Increasing nprobe can yield results closer to brute-force, where nprobe serves as a speed-accuracy regulator.
import faiss
nlist = 100
k = 4
# Create index, defined as dimension d = 128
quantizer = faiss.IndexFlatL2(d)
# Use Euclidean distance L2 to create index.
index = faiss.IndexIVFFlat(quantizer, d, nlist, faiss.METRIC_L2)
## xb: (100000,128)
index.train(xb)
index.add(xb)
index.nprobe = 10 # Default nprobe is 1, can be set higher to test
D, I = index.search(xq, k)
print(I[-5:]) # Results of the last five queries3. IndexIVFPQ
Both IndexFlatL2 and IndexIVFFlat must store all vector data. For extremely large datasets, this may not be practical. Therefore, the IndexIVFPQ index can be used to compress vectors, specifically using the Product-Quantization compression algorithm. Note that since high-dimensional vectors are compressed, the results returned during search are also approximate.
import faiss
nlist = 100
# Each vector is divided into 8 segments
m = 8
# Find 4 nearest neighbors
k = 4
quantizer = faiss.IndexFlatL2(d) # The internal indexing method remains unchanged
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8) # Each vector is encoded to a size of 8 bytes
index.train(xb)
index.add(xb)
index.nprobe = 10
D, I = index.search(xq, k) # Retrieval
print(I[-5:])In this issue, we only used the basic IndexIVFFlat and IndexFlatIP to complete the indexing and searching of BERT embeddings. Future content will interpret the principles and code practices of Product-Quantization.
AG News Dataset
The AG News Dataset 3.0 contains English news headlines, with the training part containing 120,000 pieces of data and the test part containing 7,600 pieces of data.
The AG News dataset can be automatically downloaded via the huggingface datasets API
def load_dataset(part='test') -> List[str]:
ds = datasets.load_dataset("ag_news")
list_str = [r['text'] for r in ds[part]]
return list_str
list_str = load_dataset(part='train')
print(f'{len(list_str)}')
for s in list_str[:3]:
print(s)
print('\n')The first three news headlines are displayed as follows:
120000
Wall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling band of ultra-cynics, are seeing green again.
Carlyle Looks Toward Commercial Aerospace (Reuters) Reuters - Private investment firm Carlyle Group, which has a reputation for making well-timed and occasionally controversial plays in the defense industry, has quietly placed its bets on another part of the market.
Oil and Economy Cloud Stocks' Outlook (Reuters) Reuters - Soaring crude prices plus worries about the economy and the outlook for earnings are expected to hang over the stock market next week during the depth of the summer doldrums.Sentence-Transformer
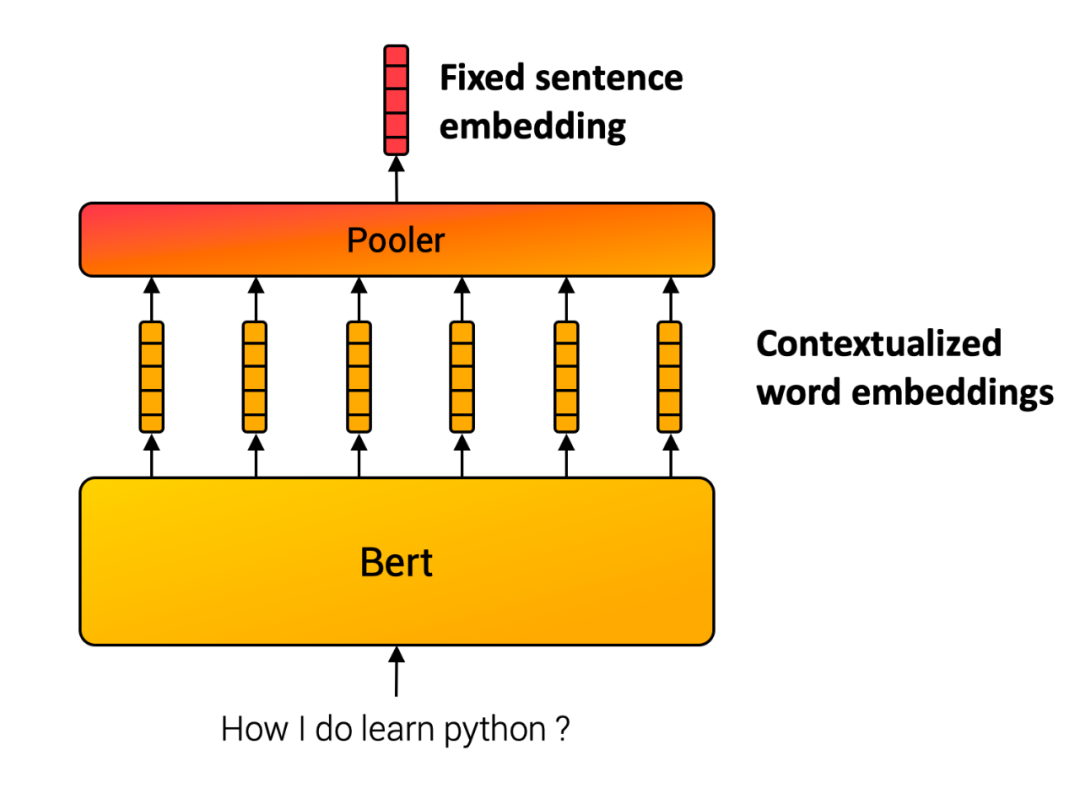
As in the previous issue, we use sentence-transformer to generate sentence-level embeddings. Its principle is based on the paper Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (https://arxiv.org/abs/1908.10084). The basic idea is straightforward: the BERT embeddings of each word in the sentence are fed into a pooling layer (pooling), for example, selecting the simplest average pooling layer, and the mean of all token embeddings is taken as output, resulting in a fixed-length sentence embedding that is independent of the input sentence length.
Results Display
Due to the large number of samples in the training part of the dataset, it takes some time to generate BERT embeddings. You can quickly experience it by using load_dataset(part='test'). Below we demonstrate a query for the closest results to ‘how to make money’.
index = load_index('news_train.index')
list_id = query(model, index, 'how to make money')
for id in list_id:
print(list_str[id])Profit From That Traffic Ticket Got a traffic ticket? Can't beat 'em? Join 'em by investing in the company that processes those tickets.
Answers in the Margins By just looking at operating margins, investors can find profitable industry leaders.
Types of Investors: Which Are You? Learn a little about yourself, and it may improve your performance.
Target Can Aim High Target can maintain its discount image while offering pricier services and merchandise.
Finance moves Ford into the black US carmaker Ford Motor returns to profit, as the money it makes from lending to customers outweighs losses from selling vehicles.Core Code
All runnable code and data have already been included in the Docker image. Below is the core code
Building the Index
def train_flat(index_name, id_list, embedding_list, num_clusters):
import numpy as np
import faiss
dim = 768
m = 16
embeddings = np.asarray(embedding_list)
quantiser = faiss.IndexFlatIP(dim)
index = faiss.IndexIVFFlat(quantiser, dim, num_clusters, faiss.METRIC_INNER_PRODUCT)
index.train(embeddings) ## clustering
ids = np.arange(0, len(id_list))
ids = np.asarray(ids.astype('int64'))
index.add_with_ids(embeddings, ids)
print(index.is_trained)
print("Total Number of Embeddings in the index", index.ntotal)
faiss.write_index(index, index_name)Query Results
def query(model, index, query_str: str) -> List[int]:
topk = 5
q_embed = model.encode([query_str])
D, I = index.search(q_embed, topk)
print(D)
print(I)
return I[0].tolist()📝 Submit Your Paper for Review, Let your article be seen by more people from different backgrounds and directions, so it doesn’t sink into obscurity, and perhaps it will increase citations~ Just add “submission” as a note when contacting via WeChat below.
Recent Articles
Which conference should I submit to: EMNLP 2022 or COLING 2022?
A new easy-to-use unified model based on Word-Word relationships for NER
Alibaba + Peking University | Amazing effects from simple masking on gradients
ACL’22 | Kuaishou + Chinese Academy of Sciences propose a data augmentation method: Text Smoothing
Download 1: Chinese version! Learn TensorFlow, PyTorch, machine learning, deep learning, and data structure five-piece set! Reply 【five-piece set】 in the background
Download 2: Nanjing University Pattern Recognition PPT Reply 【Nanjing University Pattern Recognition】 in the background
For submissions or learning exchanges, please note:Nickname – School (Company) – Field, to join the DL & NLP exchange group.
There are many fields:Machine learning, deep learning, Python, sentiment analysis, opinion mining, syntactic analysis, machine translation, human-computer dialogue, knowledge graphs, speech recognition, etc..

Remember to leave a note
Organizing is not easy, so please give it a read!