
Source: DeepHub IMBA
This article is about 2700 words long and suggests a reading time of 9 minutes. This article takes you into the details of Distil and provides a complete code implementation. This article provides a detailed introduction to DistilBERT and gives a complete code implementation.
Machine learning models have become increasingly large, and even using trained models, the inference time and memory costs can skyrocket when the hardware does not meet the expectations of the model. To alleviate this problem, distillation can be used to reduce the network to a reasonable size while minimizing performance loss.
In previous articles, we introduced how DistilBERT [1] introduces a simple and effective distillation technique that can be easily applied to any BERT-like model, but we did not provide any code implementation. In this article, we will delve into the details and provide a complete code implementation.
Initialization of Student Model
Since we want to initialize a new model from an existing model, we need to access the weights of the old model. This article will use the RoBERTa [2] large provided by Hugging Face as our teacher model, and to obtain the model weights, we must know how to access them.
Hugging Face Model Structure
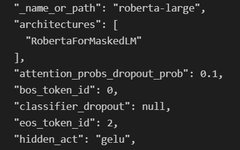
The first thing to try is to print the model, which should give us insight into how it works. Of course, we can also delve into the Hugging Face documentation [3], but that’s too cumbersome.
from transformers import AutoModelForMaskedLM
roberta = AutoModelForMaskedLM.from_pretrained("roberta-large")
print(roberta)After running this code, we get:
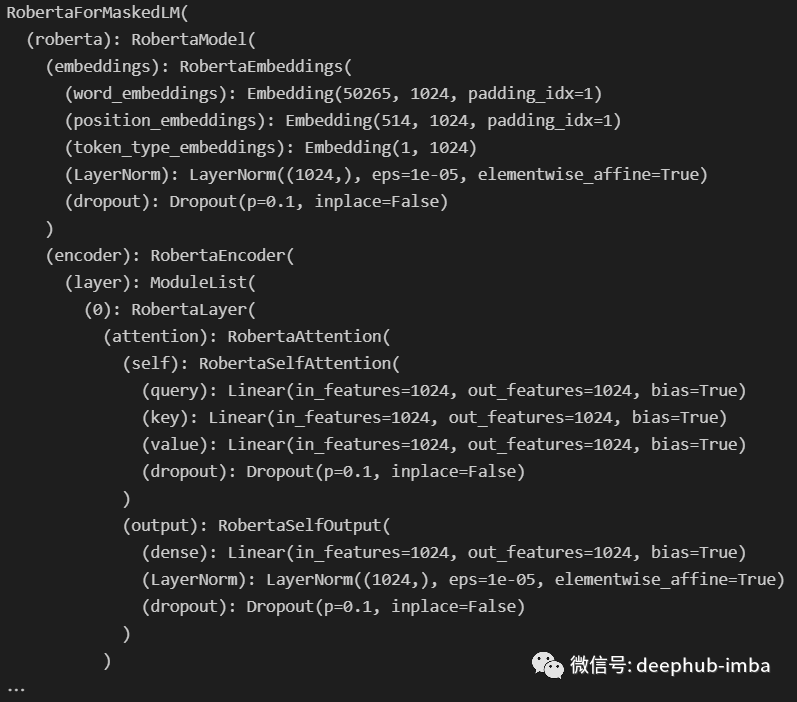
In the Hugging Face model, we can use the .children() generator to access the subcomponents of the module. Therefore, if we want to use the entire model, we need to call .children() on it and call it on each child node, which is a recursive function, as shown in the code below:
from typing import Any
from transformers import AutoModelForMaskedLM
roberta = AutoModelForMaskedLM.from_pretrained("roberta-large")
def visualize_children(object: Any, level: int = 0) -> None:
""" Prints the children of (object) and their children too, if there are any. Uses the current depth (level) to print things in an orderly manner. """
print(f"{' ' * level}{level}- {type(object).__name__}")
try:
for child in object.children():
visualize_children(child, level + 1)
except:
pass
visualize_children(roberta)This gives the following output:
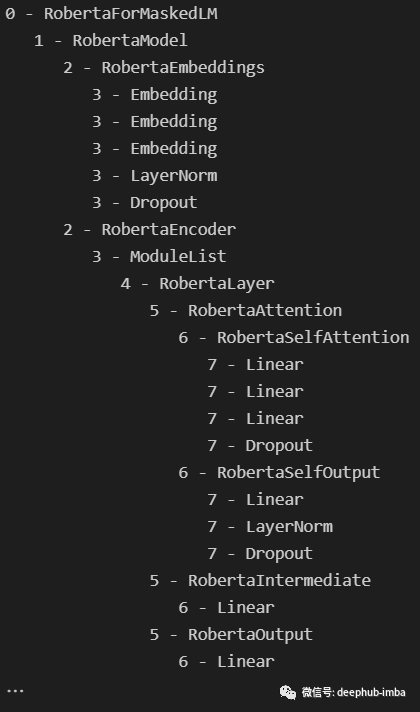
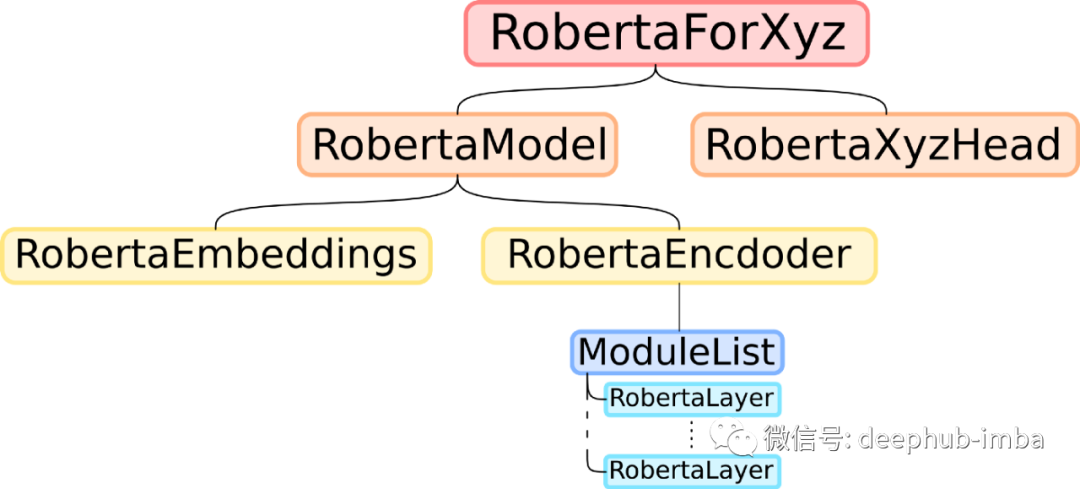
It seems that the structure of the RoBERTa model is similar to other BERT-like models, as shown below:
Copying Teacher Model Weights
To initialize a BERT-like model in the manner of DistilBERT [1], we only need to copy everything except the deepest layer of the Roberta layer and delete half of it. So here are the steps: first, we need to create a student model with the same architecture as the teacher model, but with half the number of hidden layers. We only need to use the configuration of the teacher model, which is a dictionary-like object describing the architecture of the Hugging Face model. When looking at the roberta.config attribute, we can see the following:

We are interested in the num_hidden_layers attribute. Let’s write a function to copy this configuration by dividing the attribute by 2, and then create a new model with the new configuration:
from transformers.models.roberta.modeling_roberta import RobertaPreTrainedModel, RobertaConfig
def distill_roberta(teacher_model: RobertaPreTrainedModel) -> RobertaPreTrainedModel:
""" Distills a RoBERTa (teacher_model) like would DistilBERT for a BERT model. The student model has the same configuration, except for the number of hidden layers, which is // by 2. The student layers are initialized by copying one out of two layers of the teacher, starting with layer 0. The head of the teacher is also copied. """ # Get teacher configuration as a dictionary configuration = teacher_model.config.to_dict() # Half the number of hidden layers configuration['num_hidden_layers'] //= 2 # Convert the dictionary to the student configuration configuration = RobertaConfig.from_dict(configuration) # Create uninitialized student model student_model = type(teacher_model)(configuration) # Initialize the student's weights distill_roberta_weights(teacher=teacher_model, student=student_model) # Return the student model return student_modelThis function distill_roberta_weights will copy half of the teacher’s weights into the student layers, so it still needs to be coded. Since recursion works well for exploring the teacher model, the same idea can be used to explore and copy certain parts. Here we will iterate through both the teacher and student models simultaneously and copy from one to the other. The only thing to note is the hidden layer part, which only copies half.
The function is as follows:
from transformers.models.roberta.modeling_roberta import RobertaEncoder, RobertaModel
from torch.nn import Module
def distill_roberta_weights(teacher: Module, student: Module) -> None:
""" Recursively copies the weights of the (teacher) to the (student). This function is meant to be first called on a RobertaFor... model, but is then called on every children of that model recursively. The only part that's not fully copied is the encoder, of which only half is copied. """ # If the part is an entire RoBERTa model or a RobertaFor..., unpack and iterate if isinstance(teacher, RobertaModel) or type(teacher).__name__.startswith('RobertaFor'):
for teacher_part, student_part in zip(teacher.children(), student.children()):
distill_roberta_weights(teacher_part, student_part) # Else if the part is an encoder, copy one out of every layer elif isinstance(teacher, RobertaEncoder):
teacher_encoding_layers = [layer for layer in next(teacher.children())]
student_encoding_layers = [layer for layer in next(student.children())]
for i in range(len(student_encoding_layers)):
student_encoding_layers[i].load_state_dict(teacher_encoding_layers[2*i].state_dict()) # Else the part is a head or something else, copy the state_dict else:
student.load_state_dict(teacher.state_dict())This function ensures that the student model is the same as the teacher model with Roberta layers through recursion and type checking. If you want to change which layers are copied during initialization, you only need to change the for loop in the encoder part.
Now that we have the student model, we need to train it. This part is relatively simple, the main issue is the loss function used.
Custom Loss Function
As a review of the DistilBERT training process, let’s look at the following diagram:
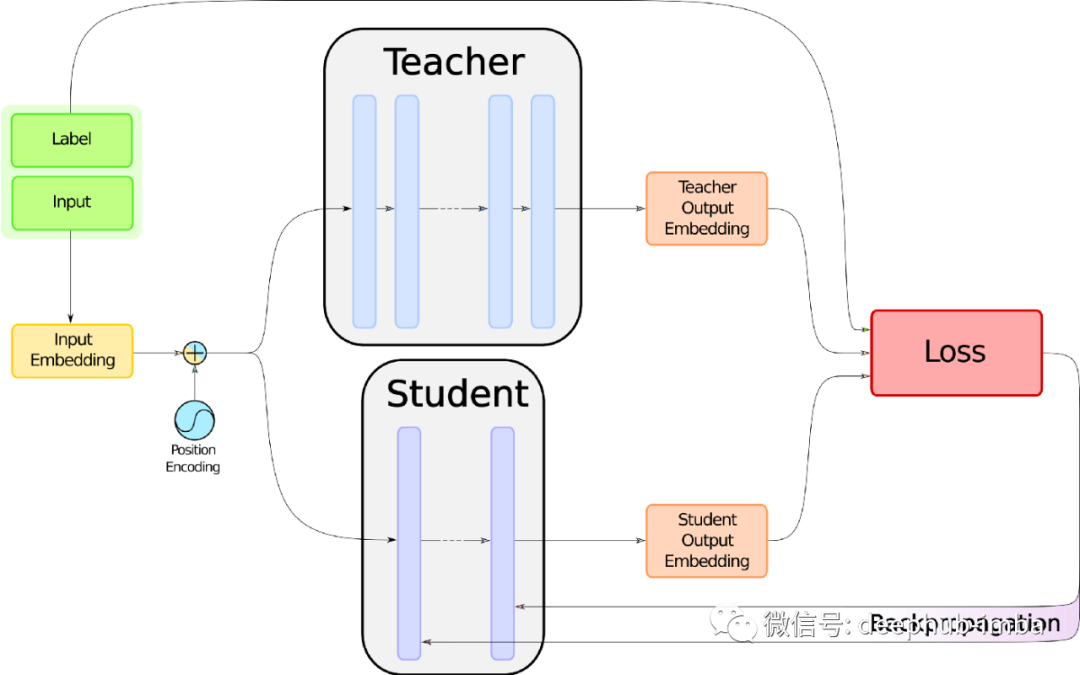
Please focus on the large red box labeled ‘Loss’ above. However, before detailing what it contains, we need to know how to collect the items we need to feed it. In this diagram, we can see that three items are needed: labels, student, and teacher embeddings. The labels are already available because it is supervised learning. Now let’s see how to obtain the other two.
Inputs of Teacher and Student
Here we need a function that, given an input for a BERT-like model, including two tensors input_ids and attention_mask and the model itself, will return the logits of that model. Since we are using Hugging Face, this is very simple. The only knowledge we need is to understand the code below:
from torch import Tensor
def get_logits(model: RobertaPreTrainedModel, input_ids: Tensor, attention_mask: Tensor) -> Tensor:
""" Given a RoBERTa (model) for classification and the couple of (input_ids) and (attention_mask), returns the logits corresponding to the prediction. """ return model.classifier(model.roberta(input_ids, attention_mask)[0])Both the student and teacher can use this function, but the first has gradients while the second does not.
Loss Function Code Implementation
For a detailed introduction to the loss function, please refer to our last published article. Here we use the following image for explanation:
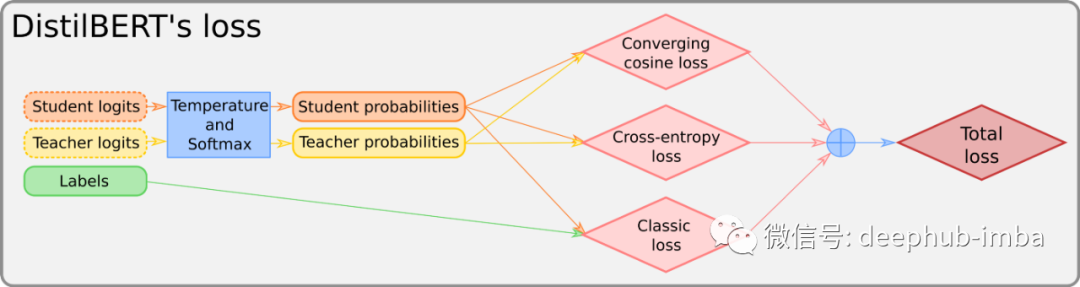
The “converging cosine-loss” we mentioned is a standard cosine loss used to align two input vectors. Here’s the code:
import torch
from torch.nn import CrossEntropyLoss, CosineEmbeddingLoss
def distillation_loss(teacher_logits: Tensor, student_logits: Tensor, labels: Tensor, temperature: float = 1.0) -> Tensor:
""" The distillation loss for distilling a BERT-like model. The loss takes the (teacher_logits), (student_logits) and (labels) for various losses. The (temperature) can be given, otherwise it's set to 1 by default. """ # Temperature and softmax student_logits, teacher_logits = (student_logits / temperature).softmax(1), (teacher_logits / temperature).softmax(1) # Classification loss (problem-specific loss) loss = CrossEntropyLoss()(student_logits, labels) # CrossEntropy teacher-student loss loss = loss + CrossEntropyLoss()(student_logits, teacher_logits) # Cosine loss loss = loss + CosineEmbeddingLoss()(teacher_logits, student_logits, torch.ones(teacher_logits.size()[0])) # Average the loss and return it loss = loss / 3 return lossThis implements all the key ideas of DistilBERT, but there are still some things missing, like GPU support, the entire training routine, etc., so the final complete code will be provided at the end of the article. If you need to actually use it, it is recommended to use the final Distillator class.
Results
How does the model distilled in this way ultimately perform? For DistilBERT, you can read the original paper [1]. For RoBERTa, there is already a distilled version similar to DistilBERT available on Hugging Face. On the GLUE benchmark [4], we can compare the two models:
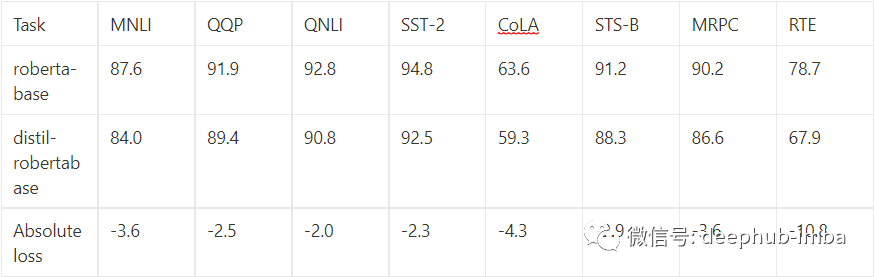
As for time and memory costs, this model is about two-thirds the size of roberta-base and is twice as fast.
Conclusion
With the above code, we can distill any BERT-like model. In addition, there are many other better methods, such as TinyBERT [5] or MobileBERT [6]. If you think one of these is more suitable for your needs, you should read those articles. You might even try a completely new distillation method since this is an ever-evolving field.
