Delivering NLP technology insights to you every day!
Source: Alchemy Notes

Paper Title:
Label Semantics for Few Shot Named Entity Recognition
https://arxiv.org/pdf/2203.08985.pdf

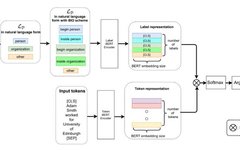
1.1 Architecture
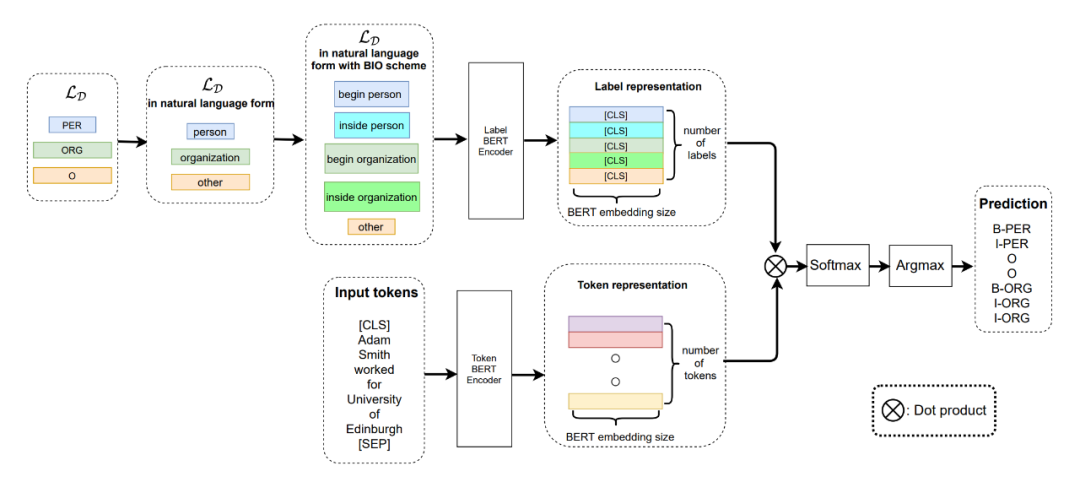
▲Figure 1. Overall Model Architecture
1.2 Detail
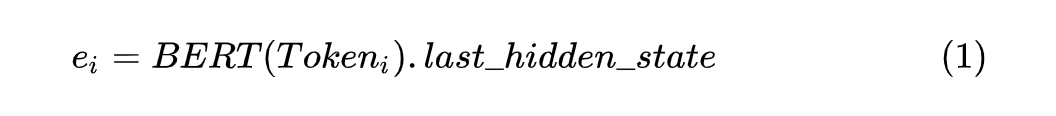
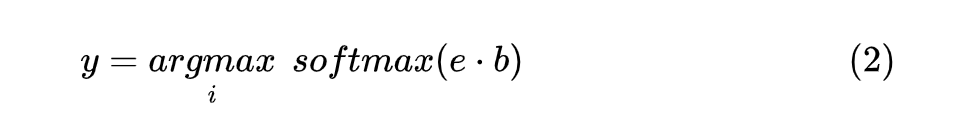
1.3 Label Transfer
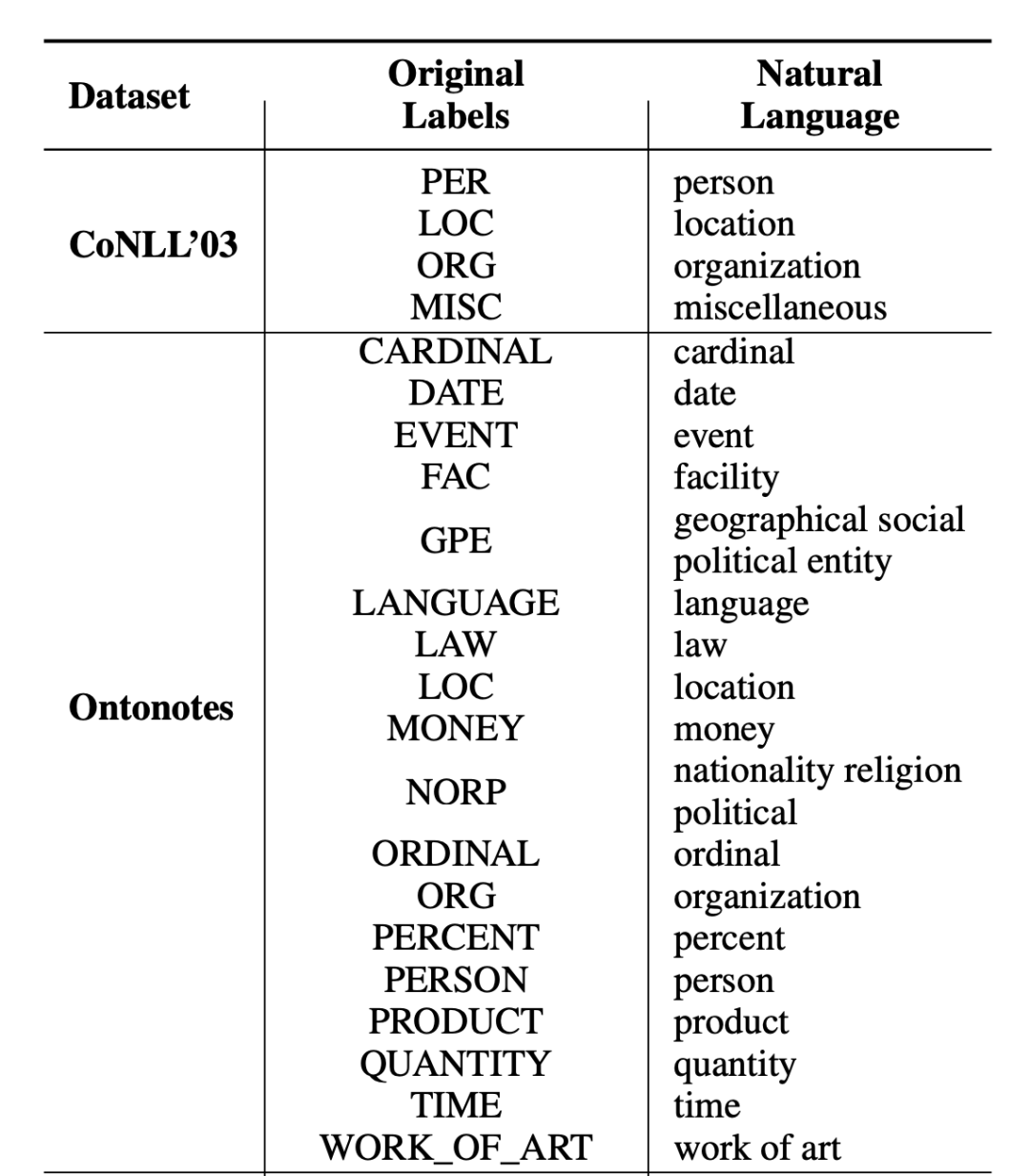
▲Figure 2. Label Transfer for Experimental Datasets
1.4 Support Set Sampling Algorithm
The sampling pseudocode is shown below:

▲Figure 3. Sampling Pseudocode


▲Figure 4. Partial Experimental Results
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2022/5/23 13:49
# @Author : SinGaln
import torch
import torch.nn as nn
from transformers import BertModel, BertPreTrainedModel
class SinusoidalPositionEmbedding(nn.Module):
"""Define Sin-Cos Position Embedding"""
def __init__(self, output_dim, merge_mode='add'):
super(SinusoidalPositionEmbedding, self).__init__()
self.output_dim = output_dim
self.merge_mode = merge_mode
def forward(self, inputs):
input_shape = inputs.shape
batch_size, seq_len = input_shape[0], input_shape[1]
position_ids = torch.arange(seq_len, dtype=torch.float)[None]
indices = torch.arange(self.output_dim // 2, dtype=torch.float)
indices = torch.pow(10000.0, -2 * indices / self.output_dim)
embeddings = torch.einsum('bn,d->bnd', position_ids, indices)
embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)
embeddings = embeddings.repeat((batch_size, *([1] * len(embeddings.shape))))
embeddings = torch.reshape(embeddings, (batch_size, seq_len, self.output_dim))
if self.merge_mode == 'add':
return inputs + embeddings.to(inputs.device)
elif self.merge_mode == 'mul':
return inputs * (embeddings + 1.0).to(inputs.device)
elif self.merge_mode == 'zero':
return embeddings.to(inputs.device)
class DoubleTownNER(BertPreTrainedModel):
def __init__(self, config, num_labels, position=False):
super(DoubleTownNER, self).__init__(config)
self.position = position
self.num_labels = num_labels
self.bert = BertModel(config=config)
self.fc = nn.Linear(config.hidden_size, self.num_labels)
if self.position:
self.sinposembed = SinusoidalPositionEmbedding(config.hidden_size, "add")
def forward(self, sequence_input_ids, sequence_attention_mask, sequence_token_type_ids, label_input_ids,
label_attention_mask, label_token_type_ids):
# Get the encoding of text and labels
# [batch_size, sequence_length, embed_dim]
sequence_outputs = self.bert(input_ids=sequence_input_ids, attention_mask=sequence_attention_mask,
token_type_ids=sequence_token_type_ids).last_hidden_state
# [batch_size, embed_dim]
label_outputs = self.bert(input_ids=label_input_ids, attention_mask=label_attention_mask,
token_type_ids=label_token_type_ids).pooler_output
label_outputs = label_outputs.unsqueeze(1)
# Position vector
if self.position:
sequence_outputs = self.sinposembed(sequence_outputs)
# Dot interaction
interactive_output = sequence_outputs * label_outputs
# full-connection
outputs = self.fc(interactive_output)
return outputs
if __name__=="__main__":
pretrain_path = "../bert_model"
from transformers import BertConfig
token_input_ids = torch.randint(1, 100, (32, 128))
token_attention_mask = torch.ones_like(token_input_ids)
token_token_type_ids = torch.zeros_like(token_input_ids)
label_input_ids = torch.randint(1, 10, (1, 10))
label_attention_mask = torch.ones_like(label_input_ids)
label_token_type_ids = torch.zeros_like(label_input_ids)
config = BertConfig.from_pretrained(pretrain_path)
model = DoubleTownNER.from_pretrained(pretrain_path, config=config, num_labels=10, position=True)
outs = model(sequence_input_ids=token_input_ids, sequence_attention_mask=token_attention_mask, sequence_token_type_ids=token_token_type_ids, label_input_ids=label_input_ids,
label_attention_mask=label_attention_mask, label_token_type_ids=label_token_type_ids)
print(outs, outs.size())
📝 Paper submission interpretation, let your article be seen by more people from different backgrounds and directions, not sinking into oblivion, and perhaps increasing citations!
Recent Articles
Which conference to submit to: EMNLP 2022 or COLING 2022?
A new easy-to-use unified model based on Word-Word relationships for NER
Alibaba + Peking University | Amazing effects from simple masking on gradients
ACL’22 | Kuaishou + CAS proposed a data augmentation method: Text Smoothing
For submissions or learning exchanges, please note:Nickname-School (Company)-Field, join the DL&NLP group.
There are many fields:Machine Learning, Deep Learning, Python, Sentiment Analysis, Opinion Mining, Syntax Analysis, Machine Translation, Human-Computer Dialogue, Knowledge Graphs, Speech Recognition, etc..

Remember to note!
It is not easy to organize, please give a thumbs up!