

Source|PaperWeekly
©PaperWeekly Original · Author|Su Jianlin
Unit|Zhuiyi Technology
Research Direction|NLP, Neural Networks
As we all know, GPT-3 is currently very popular, however, everywhere we see promotions for GPT-3, do readers remember the name of the GPT-3 paper? In fact, the paper is titled Language Models are Few-Shot Learners [1], and the title no longer contains the words G, P, T; it is simply referred to as GPT because it is a continuation of the original GPT.
As the name suggests, GPT-3 focuses on Few-Shot Learning, which is small sample learning. Additionally, another feature of GPT-3 is its size, with the largest version having up to 175 billion parameters, which is over a thousand times that of BERT Base.
Because of this, a recent paper on Arxiv titled It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners [2] caught my attention, which can be interpreted as “Who says you need to be large? Small models can also perform few-shot learning.”

The Rising MLM
MLM, short for “Masked Language Model”, can be translated as “masking language model”, which is essentially a fill-in-the-blank task where certain words in the text are randomly masked, and the model is required to predict the masked words, as illustrated below:
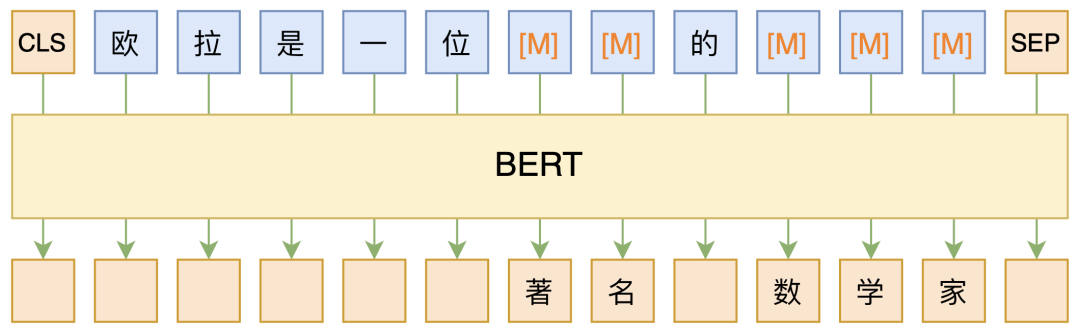
▲ Simple illustration of BERT’s MLM model
The masked parts can either be randomly selected tokens or can be a random selection of consecutive tokens that form a whole word, the latter referred to as WWM (Whole Word Masking).
Initially, MLM was only regarded as a pre-training task for BERT, something that could be discarded after training, hence some open-source models did not retain the weights of the MLM part, such as the brightmart version [3] and clue version [4] of RoBERTa, while the Harbin Institute of Technology’s open-source RoBERTa-wwm-ext-large [5] had its MLM weights randomly initialized for unknown reasons, thus these versions are not suitable for reproducing the results discussed later in this article.
However, as research deepened, researchers found that not only BERT’s Encoder is useful, but the pre-training MLM itself is also quite valuable.
For instance, the paper BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model [6] suggests that MLM can be used as a general generative model, while the paper Spelling Error Correction with Soft-Masked BERT [7] utilizes MLM for text correction.

Transforming Tasks into Fill-in-the-Blank
In this article, we will learn another exciting application of MLM: using it for few-shot learning or semi-supervised learning, and in some scenarios, even achieving zero-shot learning.
How do we combine the tasks we want to do with MLM? It’s simple, give the task a text description and then convert it into a fill-in-the-blank question. For example, if we have the sentence “I feel quite good about this trip to Beijing.”, we can add a description and construct the following fill-in-the-blank:
______ satisfied. I feel quite good about this trip to Beijing.
Furthermore, we can limit the blank to only be filled with either “very” or “not”, making the question clear, which is to determine whether the sentiment is positive based on contextual consistency. If the probability of “very” is greater than “not”, it indicates a positive sentiment, otherwise negative. Thus, we have transformed the sentiment classification problem into a fill-in-the-blank question that can be predicted using the MLM model, and the training of the MLM model can be done without supervised data, theoretically enabling zero-shot learning.
Multi-class problems can also be transformed similarly, for instance, for news topic classification, the input sentence is “After eight months, I can finally see the women’s volleyball team back on the field.” We can construct:
Here comes a ______ news report. After eight months, I can finally see the women’s volleyball team back on the field.
Thus, we have transformed news topic classification into a fill-in-the-blank problem, and a good MLM model should be able to predict the word “sports”.
Some simple reasoning tasks can also be transformed in this way. A common approach is to determine whether two sentences are compatible, for example, “I went to Beijing” and “I went to Shanghai” are contradictory, while “I went to Beijing” and “I am at Tiananmen Square” are compatible. The common practice is to concatenate the two sentences and input them into the model as a binary classification task. To transform this into a fill-in-the-blank, a natural construction could be:
Did I go to Beijing? ______, I am at Tiananmen Square.

Pattern-Exploiting Training
At this point, readers should notice the pattern, which is to add a prefix or suffix description to the input text and mask certain tokens, transforming it into a fill-in-the-blank question. This transformation is referred to as Pattern in the original paper, and it should form a natural sentence with the original sentence, avoiding stiffness, as the pre-trained MLM model is trained on natural language.
Clearly, the same question can have many different patterns. For example, in the sentiment classification case, the description can be placed at the end, becoming “I feel quite good about this trip to Beijing. ____ satisfied.”; or we can add a few more words, such as “How do you feel? ____ satisfied. I feel quite good about this trip to Beijing.”.
It is not difficult to understand that many NLP tasks can undergo this transformation, but this transformation is generally only applicable to tasks with limited candidate space, essentially for multiple-choice questions, with common tasks being text classification.
1. For each pattern, separately finetune an MLM model using the training set;
2. Then, integrate the models corresponding to different patterns to obtain a fusion model;
3. Use the fusion model to predict pseudo-labels for unannotated data;
4. Finetune a conventional (non-MLM) model using pseudo-labeled data.
The specific integration method can be found in the paper, which is not the focus. This training mode is referred to as Pattern-Exploiting Training (PET), first appearing in the paper Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference [8].
 ▲ PET’s few-shot learning results on SuperGLUE
▲ PET’s few-shot learning results on SuperGLUE

Chinese Practice, Testing Effectiveness
To truly confirm the value of a method or model, it is not enough to look at the experimental tables in papers; the experimental results provided by papers are not necessarily reproducible. Moreover, even if they can be reproduced in English, it does not mean they are valuable in Chinese. Thus, the most practical approach is to conduct experiments personally for verification. Below is my experimental code for readers’ reference:
Github Address:
https://github.com/bojone/Pattern-Exploiting-Training
We will explore the feasibility of PET from the following angles:
The following mainly presents the sentiment binary classification experimental results. Additionally, there is also a multi-class classification for news topics, and the code is also available on Github, so I won’t repeat it here.
4.1 Zero-Shot Learning 1
Here we mainly explore the accuracy of predictions using existing MLM models after supplementing the corresponding patterns to the input text. Since the entire model construction process does not involve supervised training with labeled data, this is considered a form of “zero-shot learning.” We need to compare the effects across different patterns and different MLM models:
Below are several patterns for the experiment, where the candidates for the blank are “very” and “not”:
M1: Google’s open-source Chinese BERT Base:
https://github.com/google-research/bert
M2: Harbin Institute of Technology’s open-source RoBERTa-wwm-ext Base:
https://github.com/ymcui/Chinese-BERT-wwm
M3: Tencent UER’s open-source BERT Base:
https://share.weiyun.com/5QOzPqq
M4: Tencent UER’s open-source BERT Large:
https://share.weiyun.com/5G90sMJ
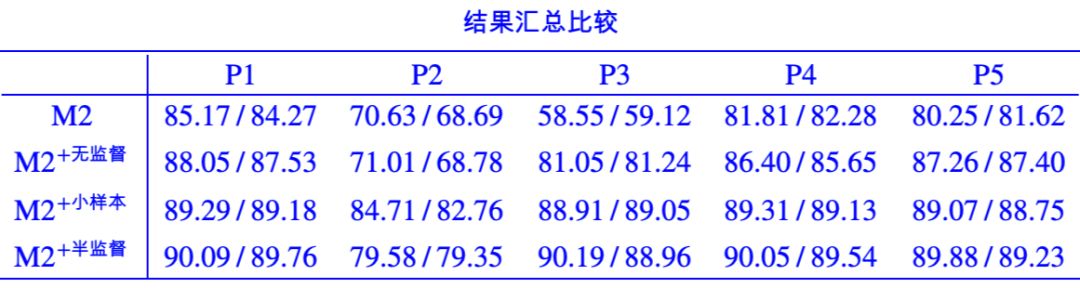
The experimental results are shown in the table below (validation/test set):

The best result can reach 88%! This means that by loading existing MLMs and using appropriate patterns, we can correctly identify the sentiment tendency of most samples without any labeled data. This makes us see the potential of MLM models in a new light.
It can be observed that there are still certain differences between different patterns and pre-trained models. Overall, the performance of the large versions is significantly better than that of the base versions, indicating that like the transition from GPT to GPT2 and then to GPT3, making the models larger generally leads to better performance.
4.2 Zero-Shot Learning 2

Having discussed the improvements from continuing pre-training with unlabeled data, what happens if we return to the target scenario of PET, directly training the MLM with a small amount of labeled data paired with specific patterns?

4.3 Semi-Supervised Learning

Again, the “suffix” clearly performs worse than the “prefix”, and the results are quite similar for the “prefix”. Specifically, the additional unlabeled data has been confirmed to be effective.
Readers can also compare the results from our previous article on generalization chaos: from random noise, gradient penalties to virtual adversarial training, showing that whether it is zero-shot learning, few-shot learning, or semi-supervised learning, the MLM model-based approach can match the results of VAT-based semi-supervised learning.
Our results in short news multi-class classification experiments are also similar. Therefore, this indicates that the MLM model can indeed serve as an excellent zero-shot/few-shot/semi-supervised learner.

It’s time for a summary
This article introduced a novel application of BERT’s MLM model: transforming tasks into fill-in-the-blank questions with specific descriptions, utilizing the MLM model for zero-shot learning, few-shot learning, and semi-supervised learning.

References

Download 1: Hands-on Learning Deep Learning
Reply "Hands-on Learning" in the backend of the Machine Learning Algorithms and Natural Language Processing official account
To obtain the 547-page eBook and source code of "Hands-on Learning Deep Learning."
This book covers both methods and practices of deep learning,
Not only explaining the techniques and applications of deep learning from a mathematical perspective,
But also includes runnable code,
Showing readers how to solve problems in practice.
Download 2: Repository address sharing
Reply "Code" in the backend of the Machine Learning Algorithms and Natural Language Processing official account
To obtain 195 papers from NAACL + 295 papers from ACL2019 with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Heavyweight! The Machine Learning Algorithms and Natural Language Processing exchange group has officially been established!
There are a lot of resources in the group, welcome everyone to join and learn!
Additional welfare resources! Qiu Xipeng's deep learning and neural networks, official PyTorch Chinese tutorial, data analysis using Python, machine learning notes, official pandas documentation in Chinese, effective java (Chinese version) and 20 other welfare resources
How to obtain: After entering the group, click on the group announcement to get the download link
Note: Please modify the remarks when adding as [School/Company + Name + Direction]
For example - Harbin Institute of Technology + Zhang San + Dialogue System.
The group owner, please avoid business. Thank you!
Recommended Reading:
Review of Open Domain Knowledge Base Question Answering Research
Use PyTorch Lightning to Automatically Train Your Deep Neural Network
Collection of Commonly Used PyTorch Code Snippets