

Text correction is a technology in the field of natural language processing that detects whether a piece of text contains typos and corrects them. It is generally used in the text preprocessing stage and can significantly alleviate the issues of inaccurate speech recognition (ASR) in scenarios like intelligent customer service.
This article will briefly introduce knowledge related to text correction through the following chapters.
1. Examples and Challenges of Text Correction
2. Common Techniques for Text Correction
3. How to Apply BERT to Text Correction
4. Optimal Model for Text Correction: Soft-Masked BERT (2020-ACL)
5. Recommended Tools for Immediate Use1. Examples and Challenges of Text Correction
Common text errors in daily life can be divided into two main categories: (1) errors caused by similar characters and (2) errors caused by similar pronunciations; for example: “咳数” -> “咳嗽”; “哈蜜” -> “哈密”. Typos often come from the following “similar character dictionary”.


Other errors also include those caused by dialects, colloquial expressions, and repeated inputs, which are more common in ASR.
Existing NLP technologies can already solve most spelling errors. The remaining challenges in correction mainly lie in the fact that some spelling errors require world knowledge to identify. For example:
Wrong: "I want to travel to the Egyptian pyramid."
Right: "I want to travel to the Egyptian pyramid."Correcting “金子塔” to “金字塔” requires certain background knowledge.
Additionally, some errors require the model to possess reasoning and analytical abilities similar to humans to detect. For example:
Wrong: "His desire to win is strong; he is digging a hole to escape."
Right: "His desire to survive is strong; he is digging a hole to escape."Both “求胜欲” and “求生欲” are correct in natural language, but analyzing the context makes it clear that the latter is more appropriate.
Finally, text correction technology has strict requirements for false positive rates, generally requiring it to be below 0.5%. If the false positive rate of the correction method is too high (incorrectly correcting the correct word to an error), it can have a negative impact on the system and user experience.
2. Common Techniques for Text Correction
Research on typo correction has a long history. Common methods can be summarized as typo dictionaries, edit distance, and language models.
Building a typo dictionary is labor-intensive and suitable for specific vertical fields with limited typos; edit distance uses string fuzzy matching methods to correct some common typos and grammatical errors by comparing with correct samples, but lacks generality.
Therefore, the current focus of research in academia and industry is generally on correction techniques based on language models. Before 2018, language model methods could be divided into traditional n-gram LM and DNN LM, which can correct at the character or word level. The semantic information of the “character level” is relatively weak, resulting in a higher false positive rate compared to the “word level”; the “word level” is more dependent on the accuracy of the word segmentation model.
To reduce the false positive rate, a CRF layer is often added to the output layer of the model to avoid unreasonable typo outputs by learning transition probabilities and the globally optimal path.
After 2018, pre-trained language models became popular, and researchers quickly adapted BERT-like models for text correction, achieving new optimal results.
3. Applying BERT to Text Correction

The main difference between BERT and previous deep learning models is that it uses two tasks during the pre-training phase: the “masked language model” (MLM) and “determine if s1 is the next sentence of s2” (NSP). Feature extraction uses a 12-layer bidirectional Transformer and larger training corpus. The MLM task forces the model to rely more on contextual information to predict vocabulary, giving it a certain correction ability.
A simple usage method is to sequentially mask each character c in the text s and rely on the context of c to predict the most suitable character for the position of c (assuming the vocabulary size is 20,000, which means a “20,000 classification” is performed at each position in the sentence). Set a tolerance threshold k=5; if the original character c appears in the top 5 of the prediction results, it is considered that the position is not a typo; otherwise, it is a typo.

Of course, this method is too crude and may result in a high false positive rate. As an optimization, we can fine-tune BERT using pre-training, which significantly improves correction performance. The domain of correction is best aligned with the fine-tuning domain (for example, if correction is needed in news articles, the “People’s Daily corpus” can be used for model fine-tuning).
4. Optimal Model for Text Correction: Soft-Masked BERT
To address the shortcomings of the baseline method and maximize the effectiveness of BERT, researchers from Fudan University published the latest paper at ACL 2020: Spelling Error Correction with Soft-Masked BERT
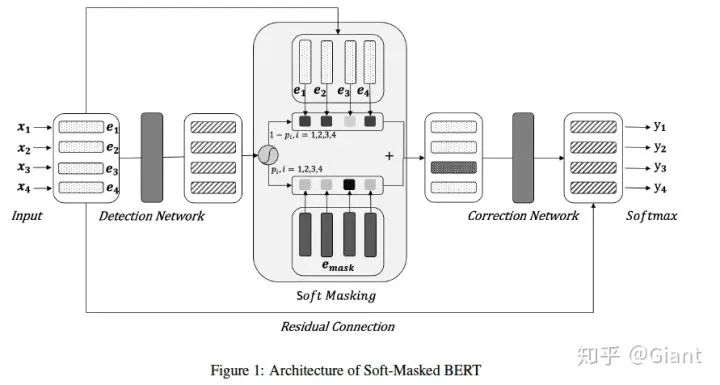
The paper first proposed the Soft-Masked BERT model, with the main innovations being:
(1) Dividing text correction into a detection network and a correction network, with the correction network’s input coming from the detection network’s output.
(2) Using the output of the detection network as weights, adding masking-embedding to each character feature in a “soft manner”, i.e., “Soft-Masked”.
Brief Analysis of the Paper
Specifically, the model input is character-level word-embedding, which can use the output of the BERT-Embedding layer or word2vec. The detection network consists of Bi-GRU, which fully learns the contextual information of the input, and the output is the probability p(i) that each position i may contain a typo, with a larger value indicating a higher likelihood of error at that position.
Detection Network and Soft Masking
In the Soft Masking part, the features of each position are multiplied by the probability  of the masking character’s feature
of the masking character’s feature  and multiplied by the probability
and multiplied by the probability  of the original input features, and finally, the two parts are added as the features for each character, which are input into the correction network. The original description:
of the original input features, and finally, the two parts are added as the features for each character, which are input into the correction network. The original description:

Correction Network
The correction network is a sequence multi-class tagging model based on BERT. The features output from the detection network serve as input to the 12-layer Transformer module of BERT, and the output of the last layer + the embedding features of the input  (residual connection) serve as the final feature representation for each character.
(residual connection) serve as the final feature representation for each character.
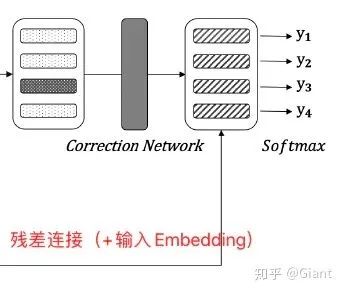
Finally, each character feature is passed through a Softmax classifier, outputting the character with the highest probability from the candidate word list as the correct character for each position.

The entire network is trained end-to-end, with the loss function composed of the weighted detection and correction networks.

Experimental Results
The authors conducted comparative experiments on two datasets: “SIGHAN” and “NEWs Title”. The “SIGHAN” dataset is a Chinese text correction dataset open-sourced in 2013, with about 1,000 entries. The “NEWs Title” dataset is automatically constructed from news headlines on Toutiao (based on the similar character and pronunciation dictionaries presented at the beginning of the article), containing 5 million entries.

Soft-Masked BERT achieved the best results on both datasets. At the same time, we found that fine-tuning had a significant positive effect on the performance of the original BERT.
The authors have not yet open-sourced the paper’s code, but the model and ideas in the paper should be very clear and easy to understand, making implementation not too difficult. I’ll set a flag here to implement it myself when I have time.
5. Recommended Text Correction Tools for Immediate Use
The author found through simple research that there are already many open-source toolkits available online for text correction. The most well-known is pycorrector. It supports various models such as kenlm, rnn_crf, seq2seq, BERT, etc. With fine-tuning in specific fields and a small number of rule corrections, it should be able to meet the text correction needs in most scenarios.

In the demo, I used a BERT model fine-tuned with the People’s Daily corpus, loaded via pycorrect, to perform MLM-based text correction. The recognition results were quite good, and even typos like “金字塔” that require common sense were corrected.
Of course, pycorrect also supports various language models and DNN models, leaving it for everyone to play with : )
Additionally, I found a JD customer service robot corpus-based correction model, which mainly addresses automatic correction of homophones, such as:
Significantly reducing trust in JD for newcomers --> Significantly reducing trust in JD
I want to buy brother's Apple phone --> I want to buy an Apple phoneHowever, the last update to the repository was 5 years ago, so its effectiveness may be limited.
These are some thoughts I had after recent research on text correction. I happened to share them in a lab meeting last week, so I wrote this article. If anyone finds good correction methods or papers, please feel free to leave a comment to share and discuss.
References
Important! The Yizhen Natural Language Processing – Academic WeChat group has been established.
You can scan the QR code below, and the assistant will invite you to join the group for discussion.
Note: Please modify the remark to [School/Company + Name + Direction] when adding.
For example – Harbin Institute of Technology + Zhang San + Dialogue System.
Please avoid adding if you are a micro-business. Thank you!

Recommended Reading:
PyTorch Cookbook (Collection of Common Code Snippets)
Easy to Understand! Implementing Transformer with Excel and TF!
Multi-task Learning in Deep Learning (Keras Implementation)