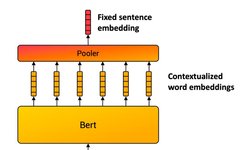
Training BERT and ResNet on Smartphones: 35% Energy Reduction

Researchers state that they see edge training as an optimization problem, thereby discovering the optimal scheduling to achieve minimal energy consumption under a given memory budget. Currently, deep learning models are widely deployed on edge devices such as smartphones and embedded platforms for inference. Training, however, is still primarily conducted on large cloud servers equipped … Read more