Limitations and Solutions of Federated Learning Privacy Protection in the AI Era

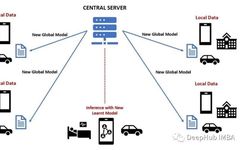
Limitations and Solutions of Federated Learning Privacy Protection in the AI Era Liu Zegang (Associate Professor, Southwest University of Political Science and Law) [Abstract] Legislation on artificial intelligence (AI) often tends to favor specific technologies. Federated learning is a mainstream machine learning technology whose greatest advantage lies in its architecture design that fully considers privacy … Read more