
Click the “MLNLP” above and select “Star” to follow the public account
Heavyweight content delivered to you first
Author:Old Song’s Tea Book Club
Zhihu Column:NLP and Deep Learning
Research Direction:Natural Language Processing
Introduction
A few days ago, during an interview, an interviewer directly asked me to analyze the source code of BERT. Emm, that was quite impressive. Fortunately, I have a solid foundation, as I had previously looked at the implementation of Transformer and also used Transformer to write a text classification task, so it didn’t stump me, haha.
However, it seems that interviewers nowadays are no longer satisfied with just asking theoretical questions. Indeed, how to assess a person’s coding ability can be seen through their ability to read source code.
Therefore, I think it’s really important for everyone to take a look at the source code of BERT. So, I spent an afternoon clarifying various pieces of code and annotating key parts. You can check out my repository: BERT-pytorch (https://github.com/songyingxin/BERT-pytorch)
1. Overall Description
BERT-Pytorch mainly sets two major functions during package distribution:
-
bert-vocab: statistics of word frequency, token2idx, idx2token, etc. Corresponds to the
bert_pytorch.dataset.vocabin thebuildfunction. -
bert: corresponds to the train function under
bert_pytorch.__main__.
To facilitate debugging, I created two separate files to debug these two major functions.
1. bert-vocab
python3 -m ipdb test_bert_vocab.py # Debugging bert-vocabIn fact, there isn’t much important information in bert-vocab, just some common preprocessing techniques in natural language processing. Spending ten minutes debugging it will make it clear, and I added a few annotations, making it easy to understand.
The internal inheritance relationship is:
TorchVocab --> Vocab --> WordVocab2. Model Architecture
-
Debugging command:
python3 -m ipdb test_bert.py -c data/corpus.small -v data/vocab.small -o output/bert.model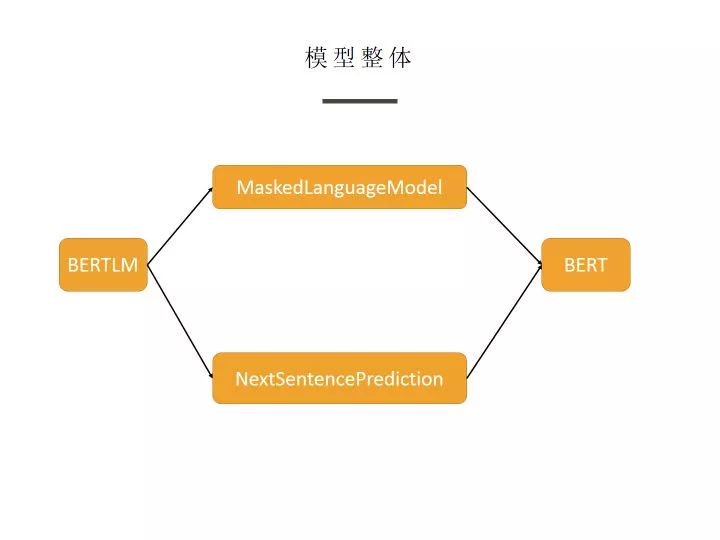
From the overall model perspective, it is divided into two main parts: MaskedLanguageModel and NextSentencePrediction, both of which use BERT as the base model, adding a fully connected layer and a softmax layer respectively to obtain the outputs.
This piece of code is relatively simple and easy to understand, so I will skip it.
1. Bert Model
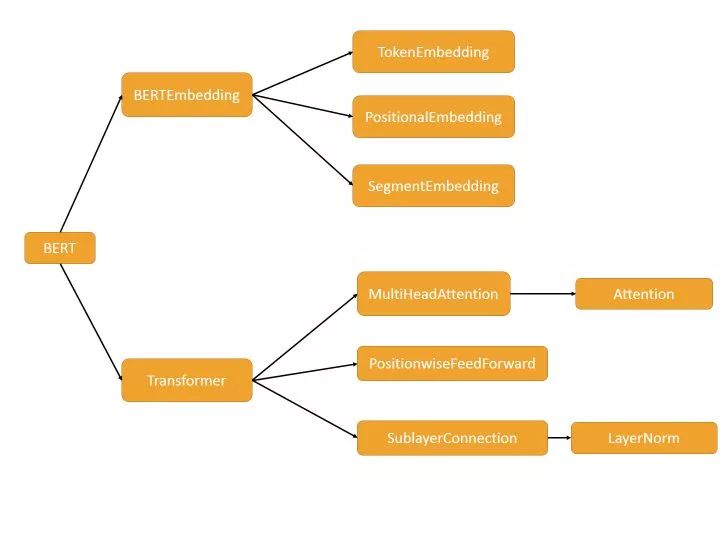
This part is essentially the Transformer Encoder part + BERT Embedding. If you’re not familiar with Transformer, this is a good place to deepen your understanding.
For reading the source code in this part, I suggest browsing through the overall structure first to understand the dependencies between different classes, and then gradually understand the details, i.e., read from right to left in the above diagram for better results.
1. BERTEmbedding
It is divided into three main parts:
-
TokenEmbedding: encoding of tokens, inheriting from
nn.Embedding, initialized by default as:N(0,1) -
SegmentEmbedding: encoding of sentence information, inheriting from
nn.Embedding, initialized by default as:N(0,1) -
PositionalEmbedding: encoding of positional information, refer to the paper, generating a fixed vector representation that does not participate in training
It is important to note the PositionalEmbedding, as some interviewers may be very detail-oriented, and I generally just get a basic understanding of things that I think are not very helpful, but it has been proven that not clarifying the details can lead to loss.
2. Transformer
It is highly recommended to refer to the paper while reviewing this part. Of course, if you are very familiar with it, you can skip it. I have added annotations at key places, and if you still don’t understand, you can raise an issue; I won’t elaborate here.
Conclusion
I personally think that Google really wrote this code beautifully, with a clear structure. You can understand it in just a few hours. I recommend using my debugging method to debug it from start to finish, which will make things clearer.
Recommended Reading:
In the Era of Deep Learning, Is Tokenization Really Necessary?
From Word2Vec to BERT, Talking About the Past and Present of Word Vectors (Part 1)
Chen Lijie, a PhD student born in the 1995 Tsinghua Yao Class, won the Best Student Paper at a Top Conference on Theoretical Computer Science.
