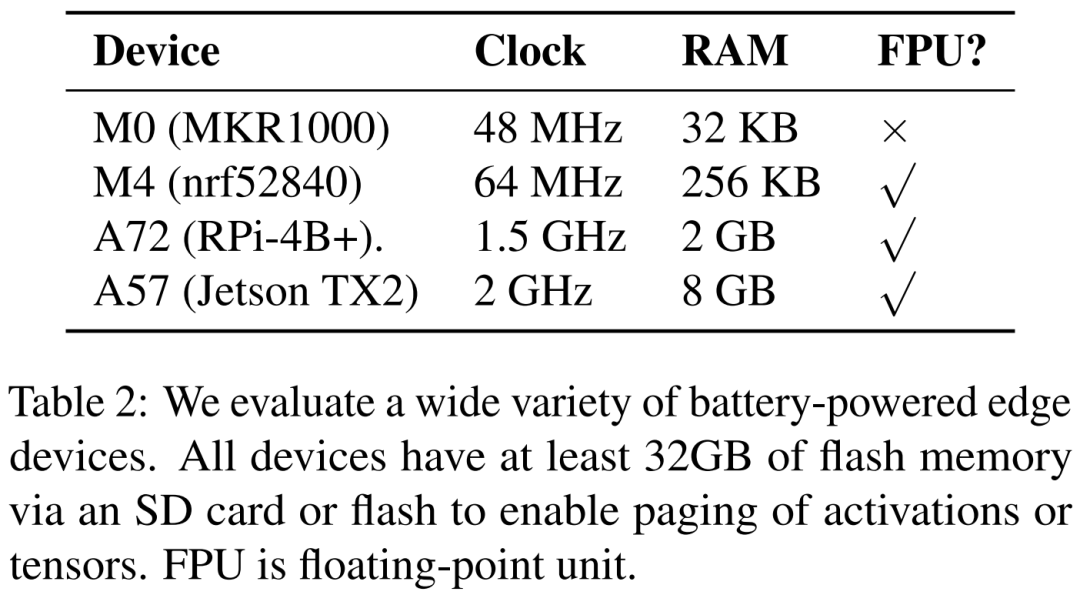
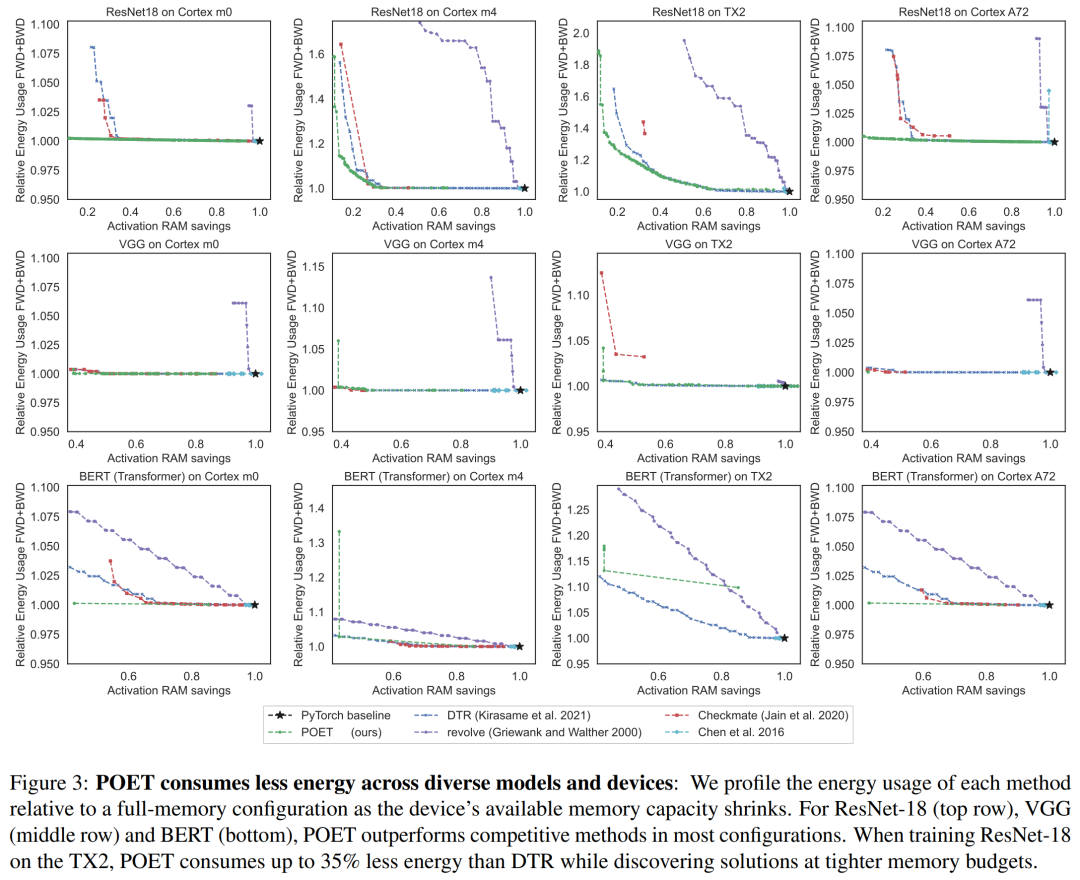
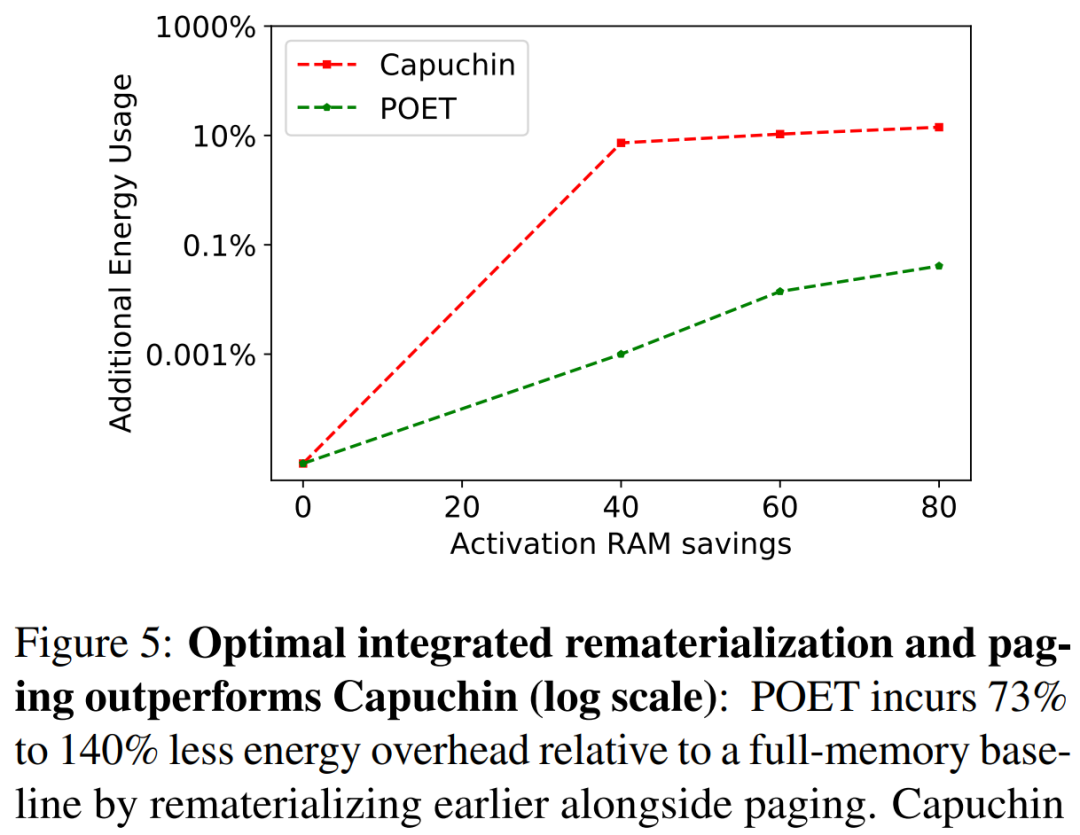
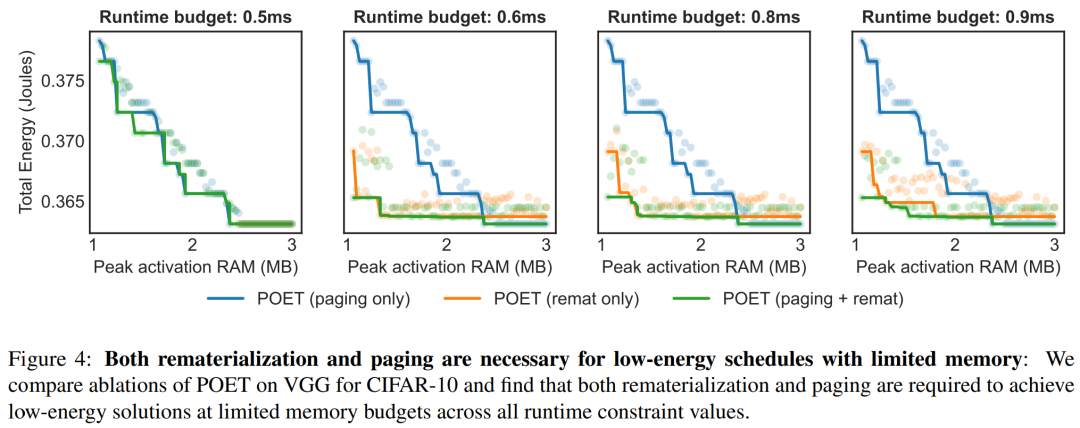
Researchers state that they see edge training as an optimization problem, thereby discovering the optimal scheduling to achieve minimal energy consumption under a given memory budget.


-
Paper link: https://arxiv.org/pdf/2207.07697.pdf -
Project homepage: https://poet.cs.berkeley.edu/ -
GitHub link: https://github.com/shishirpatil/poet
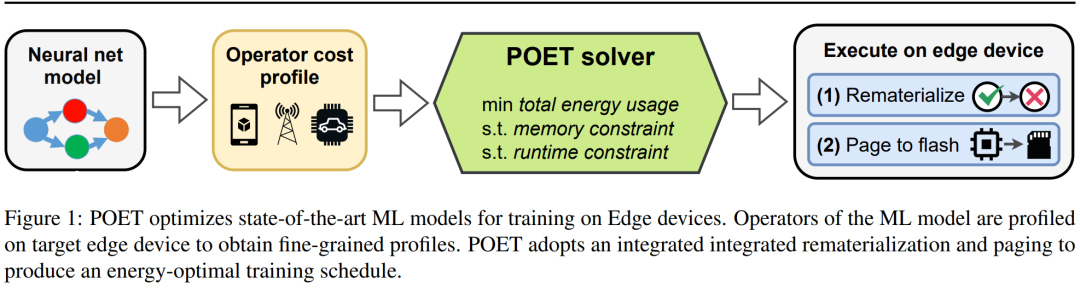
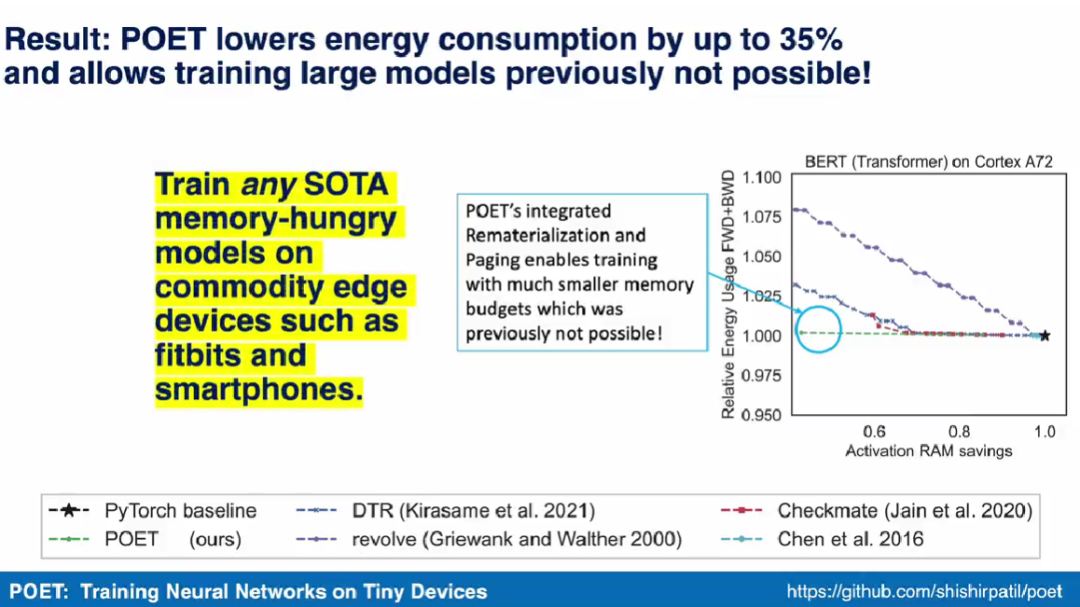
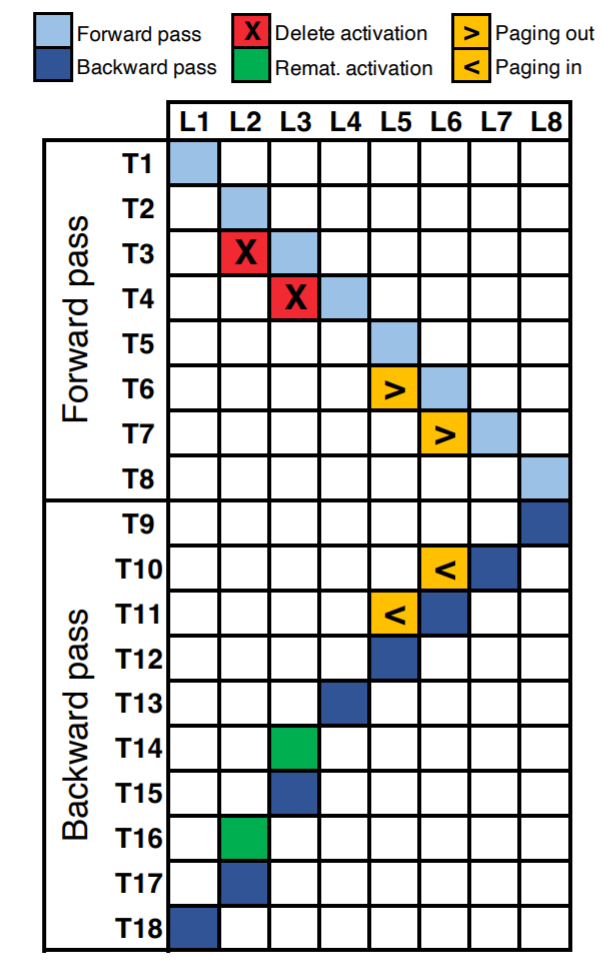

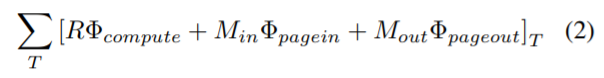
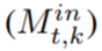 or page-out
or page-out 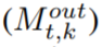 to output.
to output.