
This article is sourced from Machine Heart.
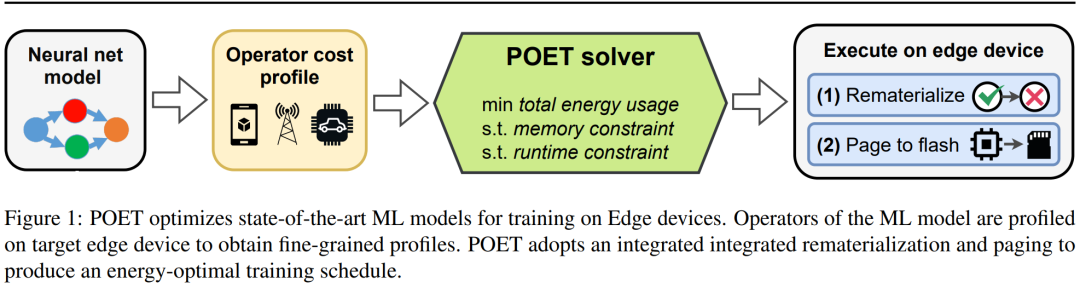
Researchers indicate that they viewedge training as an optimization problem, thus discovering the optimal scheduling to achieve minimal energy consumption under a given memory budget.


-
Paper link: https://arxiv.org/pdf/2207.07697.pdf -
Project homepage: https://poet.cs.berkeley.edu/ -
GitHub link: https://github.com/shishirpatil/poet

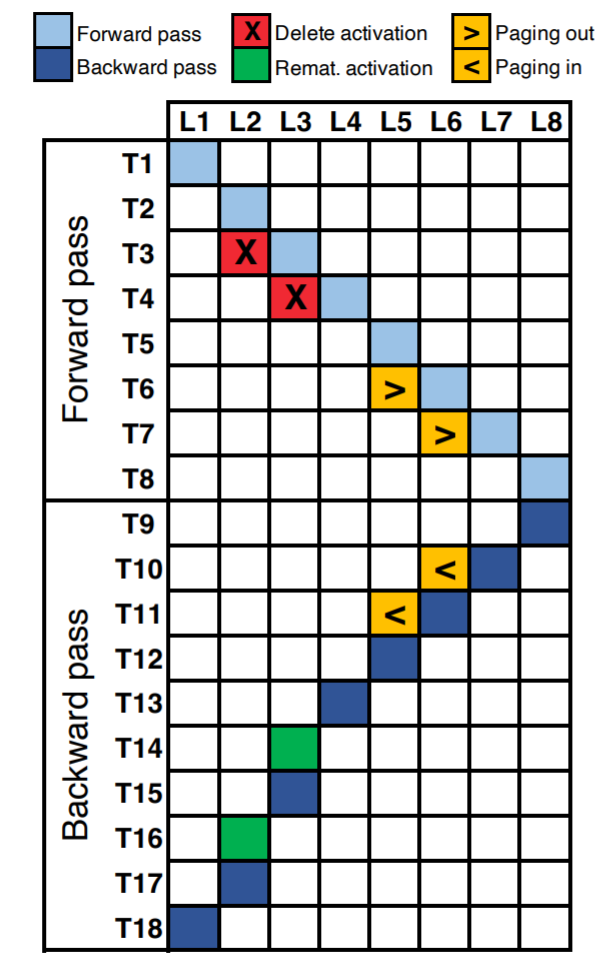


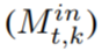 or page-out
or page-out 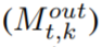 .
.


Extra, welcome to attend theGlobal Edge Computing Conference on August 6 in Shenzhen. Here you can see the best edge computing software and hardware solutions in the country. We have invited leading domestic players in edge computing such as Volcano Engine Edge Computing, Lenovo Group, Wangsu Technology, EMQ, and Wangxin Technology to discuss together.
