

Written by / Radu Soricut and Zhenzhong Lan, Researchers, Google Research
Since the advent of BERT a year ago, natural language research has adopted a new paradigm: leveraging a large amount of existing text to pre-train model parameters in a self-supervised manner without the need for any data annotation. Therefore, instead of training machine learning models for natural language processing (NLP) from scratch, we can start our research with models that already possess language knowledge.
However, to improve this new NLP approach, we must delve into the specific factors that enhance language understanding performance, whether it be network depth (number of layers), network width (size of hidden layer representations), self-supervised learning standards, or other factors?
In “ALBERT: A Lightweight BERT for Self-Supervised Learning in Language Representation” (included in ICLR 2020), we introduce an upgraded model of BERT, which exhibits the best performance across 12 NLP tasks, including the Stanford Question Answering Dataset (SQuAD v2.0) and SAT-style reading comprehension RACE benchmark. ALBERT is now open-sourced on TensorFlow and includes many ready-to-use ALBERT pre-trained language representation models.
What Factors Enhance NLP Performance?
Identifying the main driving factors that enhance NLP performance is quite complex, as some settings are more critical than others, and as our research reveals, a simple investigation of one of these settings does not yield the correct answer.
The key takeaway from our optimized performance based on ALBERT design is how to allocate the model’s capacity more effectively. Input-level embeddings (words, subword tokens, etc.) need to learn representations that are context-independent. In contrast, hidden-layer embeddings need to distill this information into context-dependent representations; for example, the meaning of “bank” differs in financial transactions versus river management.
To effectively allocate the model’s capacity, we can factorize the embedding parameters, dividing the embedding matrix among input-level embeddings at relatively smaller dimensions (e.g., 128), while hidden-layer embeddings use higher dimensions (e.g., 768 or more for BERT). With just this step, the number of parameters in ALBERT’s projection blocks can be reduced by 80%, with only a slight drop in performance: SQuAD2.0 score drops from 80.4 to 80.3; or RACE score drops from 68.2 to 67.9, with all other conditions being the same as BERT.
Another key design decision for ALBERT is based on observations of redundancy in layers. Neural network architectures based on Transformer (e.g., BERT, XLNet, and RoBERTa) rely on independent layers stacked upon each other. However, we observed that networks often learn to perform similar operations across layers using different parameters. To eliminate this potential redundancy in ALBERT, we can share parameters across layers, i.e., stack identical layers on top of each other. Using this method, while accuracy decreases slightly, the network becomes significantly more compact, making it a worthwhile trade-off. After implementing parameter sharing, the parameters in the attention feed-forward block will reduce by 90% (total parameters reduced by 70%), and aside from factorizing embedding parameters, applying this method results in a slight decrease in performance on SQuAD2.0, dropping the score by 0.3 to 80.0, while the performance drop on RACE is more significant, with a score decrease of 3.9 to 64.0.
By implementing both design changes, we can produce an ALBERT-base model with only 12 million parameters, which is a reduction of 89% compared to the BERT-base model, yet its performance remains quite remarkable according to various reference benchmarks. However, with the reduction in parameters, we gain the opportunity to scale the model again. Assuming memory size permits, we can increase the size of hidden-layer embeddings by 10-20 times. When the hidden layer size is 4096, the total parameter count of the ALBERT-xxlarge configuration is 30% less than that of the BERT-large model, and more importantly, its performance significantly improves: an increase of 4.2 in SQuAD2.0 score (from 83.9 to 88.1); and an increase of 8.5 in RACE score (from 73.8 to 82.3).
These results indicate that accurate language understanding depends on developing stable, high-capacity context representations. Modeling context based on hidden-layer embeddings captures word meanings and subsequently enhances overall understanding, which can be directly measured by model performance.
Optimizing Model Performance Using the RACE Dataset
To evaluate the model’s language understanding capability, we can conduct reading comprehension tests (similar to SAT reading tests). The RACE dataset (2017) can be used for this assessment, as it is the largest publicly available resource for this test.
The performance of computers on reading comprehension challenges reflects the advancements in language modeling over the past few years: models pre-trained with context-independent word representations score low on this test (45.9; leftmost column), while BERT models with context-aware language knowledge score 72.0, which is relatively high. Optimized BERT models like XLNet and RoBERTa also perform well, scoring in the range of 82-83. When trained with the base BERT dataset (Wikipedia and Books), the model generated from the previously mentioned ALBERT-xxlarge configuration scored 82.3 on RACE, which is in the same range. When trained with a dataset as large as that used for XLNet and RoBERTa, this method clearly outperformed all previous methods, setting a new record with a high score of 89.4.
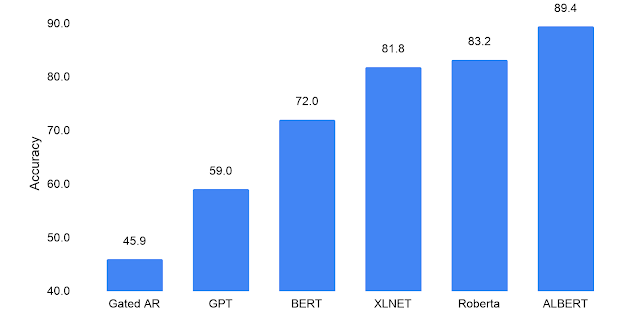
The performance demonstrated by computers in the RACE challenge (similar to SAT) shows that the random guessing baseline score is 25.0, and the highest score is 95.0
ALBERT’s success highlights the importance of understanding various aspects of the model and identifying strong context representations. Focusing on these aspects of model architecture in improvement work can significantly enhance the efficiency and performance of models across various NLP tasks. To further advance the NLP field, we will open-source ALBERT to the research community.
If you want to learn more about the topics mentioned in this article, please refer to the following documents. These documents delve deeper into many of the themes mentioned in this article:
-
ALBERT: A Lightweight BERT for Self-Supervised Learning in Language Representationhttps://arxiv.org/abs/1909.11942
-
ICLR 2020https://iclr.cc/Conferences/2020
-
Stanford Question Answering Dataset https://rajpurkar.github.io/SQuAD-explorer/
-
RACE Benchmarkhttp://www.qizhexie.com/data/RACE_leaderboard.html
-
TensorFlowhttps://tensorflow.google.cn/
-
SQuAD2.0https://rajpurkar.github.io/SQuAD-explorer/
-
RACEhttp://www.qizhexie.com/data/RACE_leaderboard.html
-
Transformerhttps://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
-
XLNethttps://www.borealisai.com/en/blog/understanding-xlnet/
-
RoBERTahttps://ai.facebook.com/blog/roberta-an-optimized-method-for-pretraining-self-supervised-nlp-systems/
-
Attention Feed-Forwardhttps://arxiv.org/abs/1706.03762
-
SAT Reading Testhttps://collegereadiness.collegeboard.org/sat/inside-the-test/reading
-
RACE Datasethttps://www.aclweb.org/anthology/D17-1082/
-
Release / ALBERT Open Sourcehttps://github.com/google-research/ALBERT
This article is reprinted from the WeChat account TensorFlow, author Google
Recommended Reading:
Deep Dive into LSTM Neural Network Design Principles
Complete Guide to Graph Convolutional Networks (GCN)
Paper Review [ACL18] Self-Attentive Constituent Parsing
