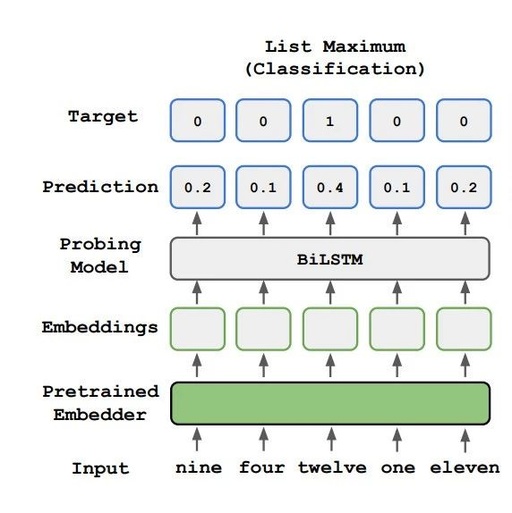
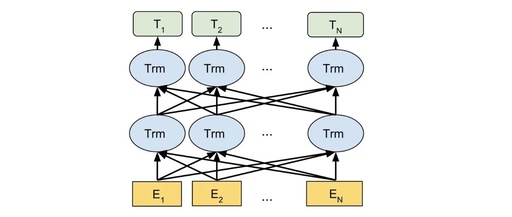
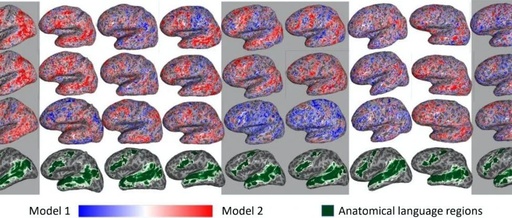
Contextual Word Vectors and Pre-trained Language Models: From BERT to T5

[Introduction] The emergence of BERT has revolutionized the model architecture paradigm in many natural language processing tasks. As a representative of pre-trained language models (PLM), BERT has refreshed leaderboards in multiple tasks, attracting significant attention from both academia and industry. Stanford University’s classic natural language processing course, CS224N, invited the first author of BERT, Google … Read more