Selected from arXiv
Translation by Machine Heart
Contributors:Mo Wang
Performing numerical reasoning on natural language text is a long-standing challenge for end-to-end models. Researchers from the Allen Institute for AI, Peking University, and the University of California, Irvine, attempt to explore whether “out-of-the-box” neural NLP models can solve this problem, and how they do so.
-
Paper: Do NLP Models Know Numbers? Probing Numeracy in Embeddings
-
Paper link: https://arxiv.org/pdf/1909.07940.pdf

-
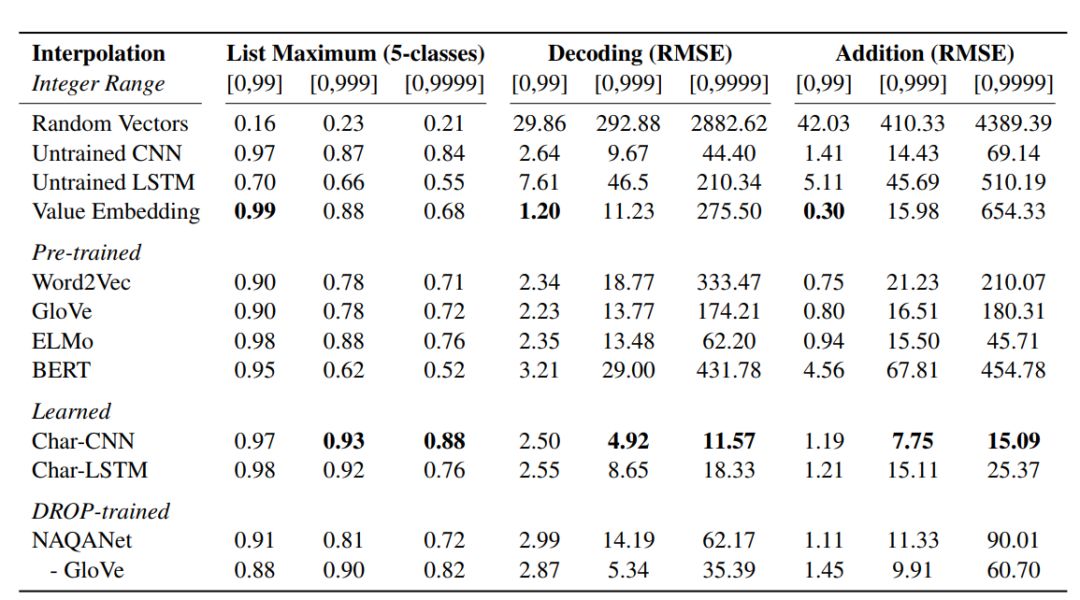
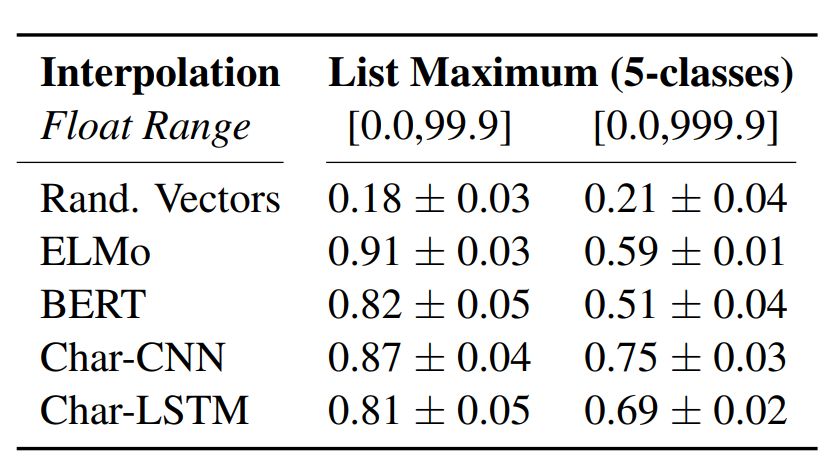
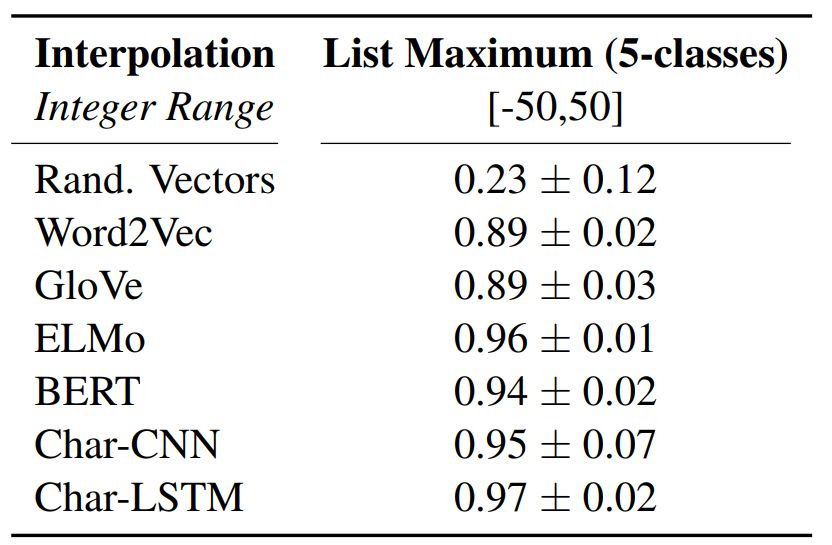
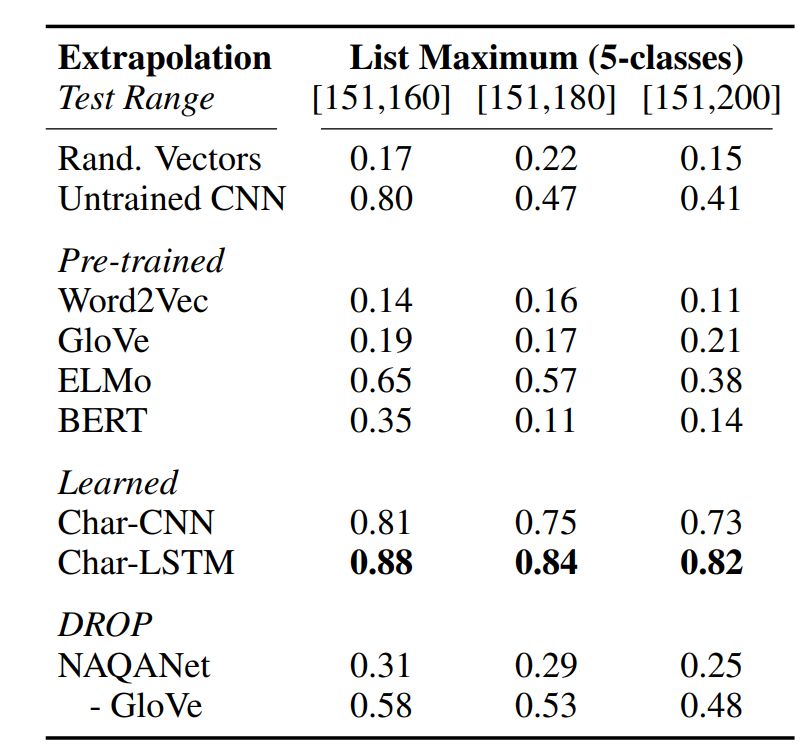
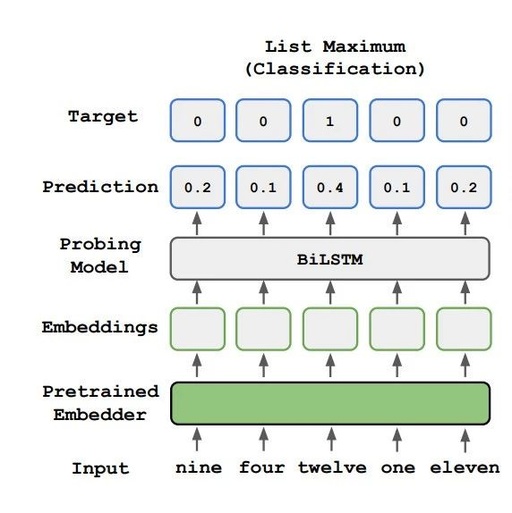
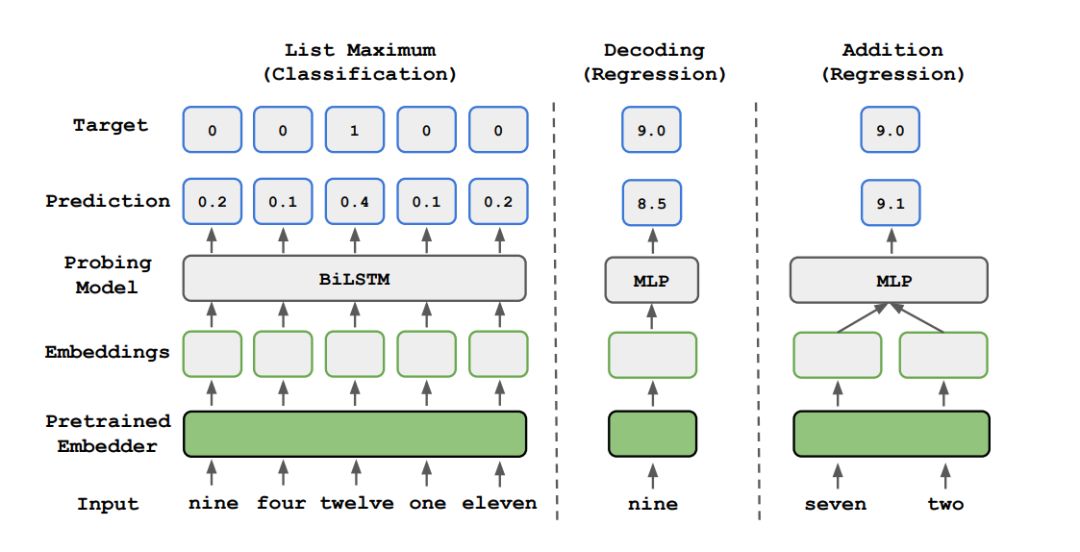
List maximum: Given an embedding list containing 5 numbers, the task is to predict the index of the maximum value.
-
Decoding: Explore whether the size of numbers can be recognized.
-
Addition: This task requires numerical operations: given the embeddings of two numbers, the task is to predict their sum.
-
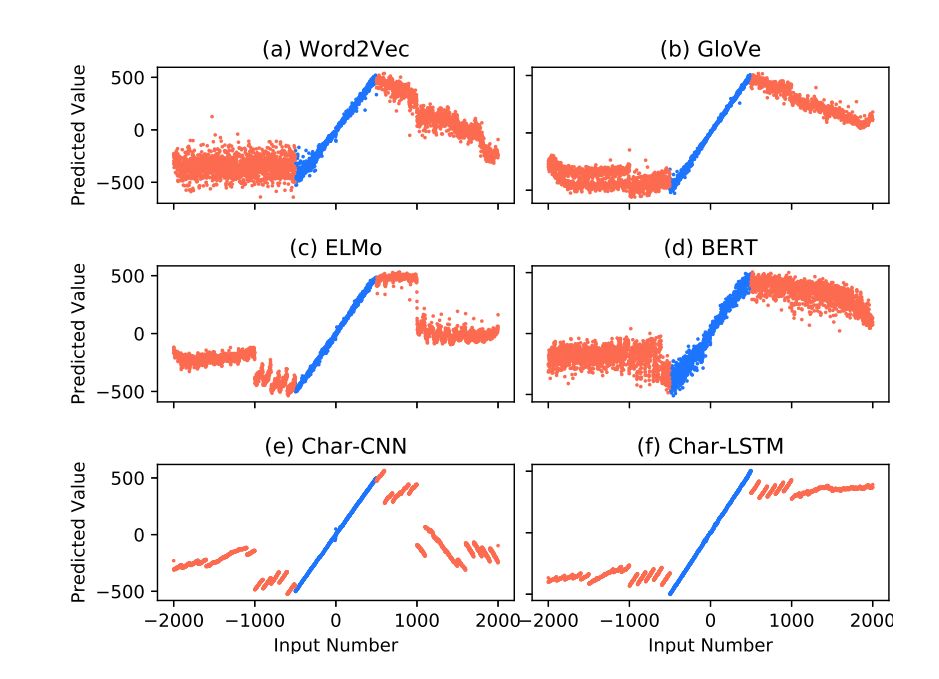
Word vectors: Using 300-dimensional GloVe and word2vec vectors.
-
Contextual embeddings: Using ELMo and BERT embeddings.
-
NAQANet embeddings: Training the NAQANet model on the DROP dataset, extracting GloVe embeddings and Char-CNN.
-
Pre-trained embeddings: Using character-level CNN (Char-CNN) and character-level LSTM (Char-LSTM).
-
Embedding numbers as values: Directly mapping the embeddings of numbers to their values.