[Introduction] The emergence of BERT has revolutionized the model architecture paradigm in many natural language processing tasks. As a representative of pre-trained language models (PLM), BERT has refreshed leaderboards in multiple tasks, attracting significant attention from both academia and industry. Stanford University’s classic natural language processing course, CS224N, invited the first author of BERT, Google researcher Jacob Devlin, to give a lecture on contextual word representation BERT and pre-trained language models, sharing practical experiences from major companies, which is worth noting!

Pre-trained word embeddings are key to the success of deep learning in NLP, as they allow models to leverage an almost unlimited amount of unlabeled text available on the web. In recent years, conditional language models have been used to generate pre-trained contextual representations, which are richer and more powerful than simple embeddings. This article introduces BERT (Bidirectional Encoder Representations from Transformers), which can generate deep bidirectional pre-trained language representations. BERT has achieved state-of-the-art results on the Stanford Question Answering Dataset, MultiNLI, Stanford Sentiment Treebank, and many other tasks.
-
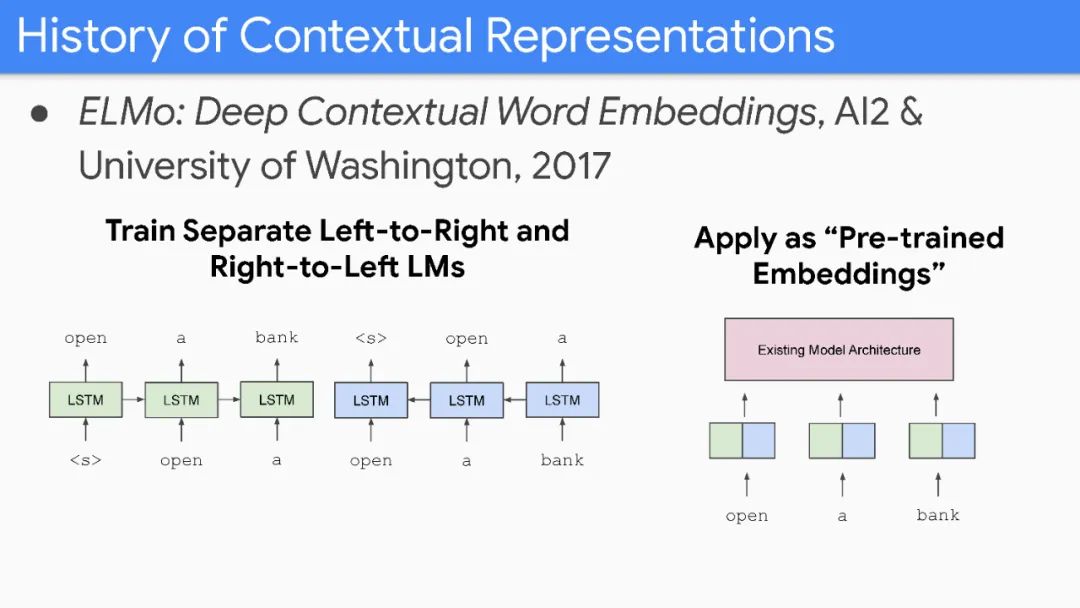
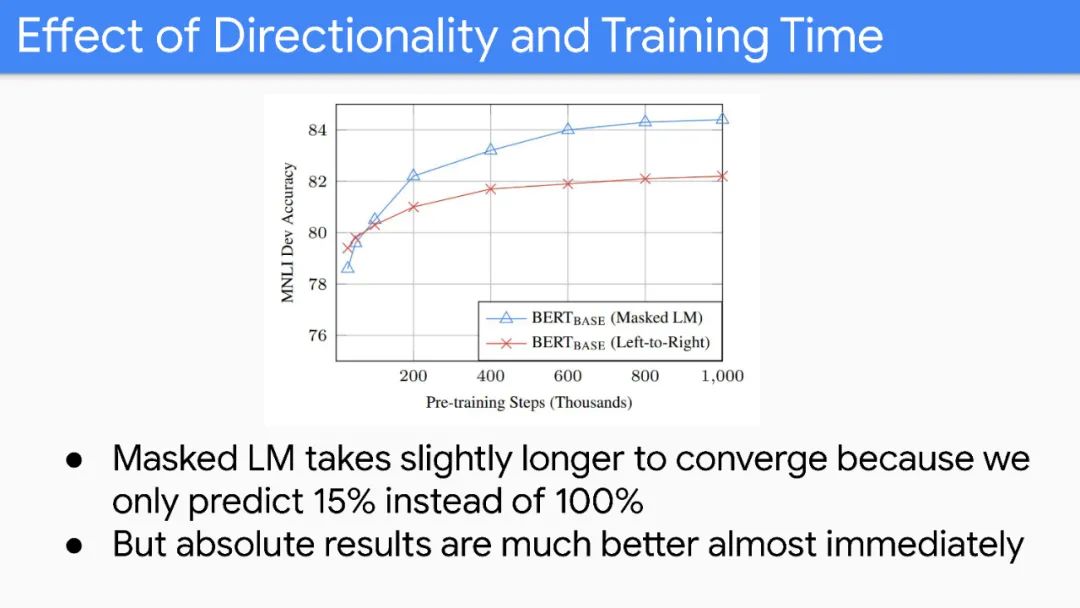
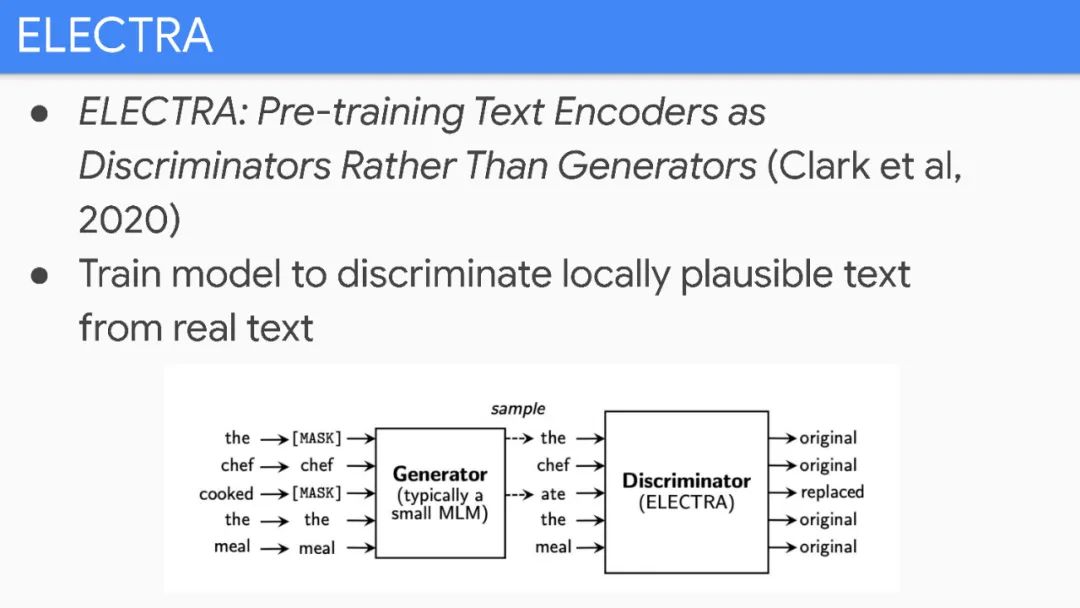
Pre-trained bidirectional language models are very effective.
-
However, these models are very expensive.
-
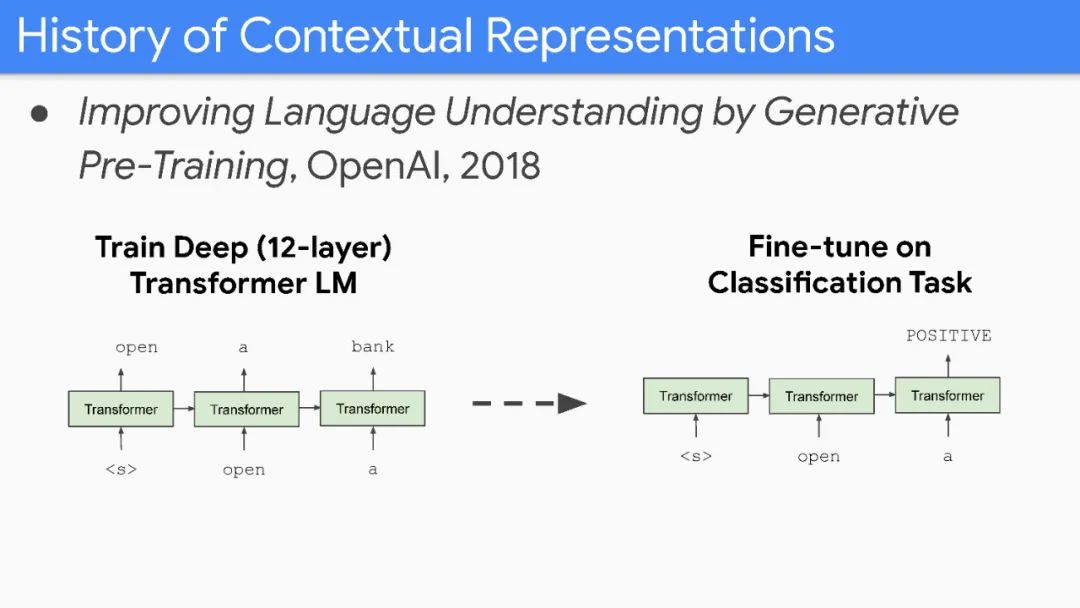
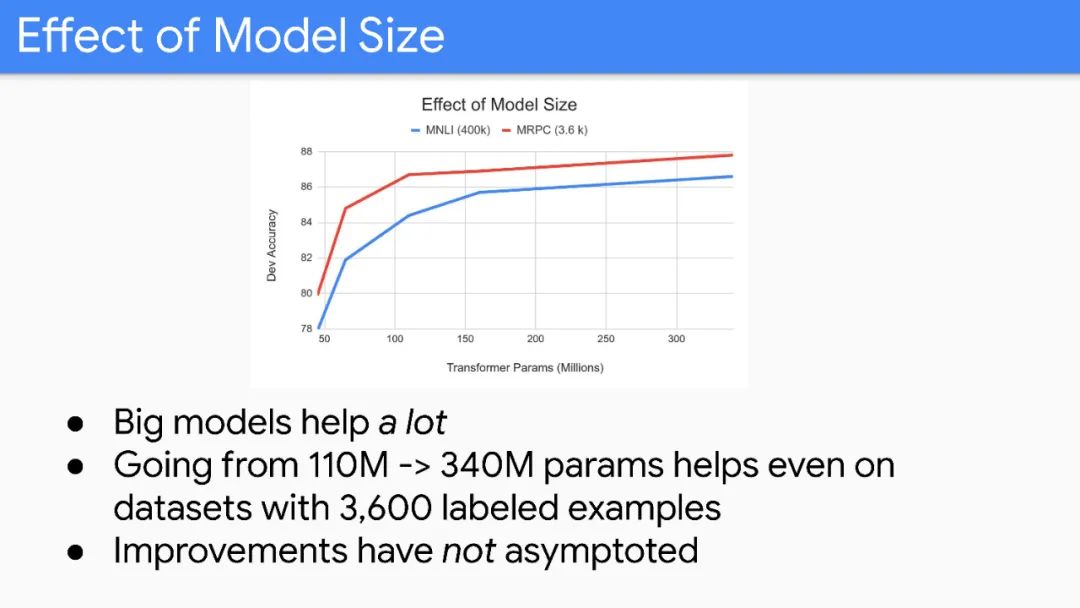
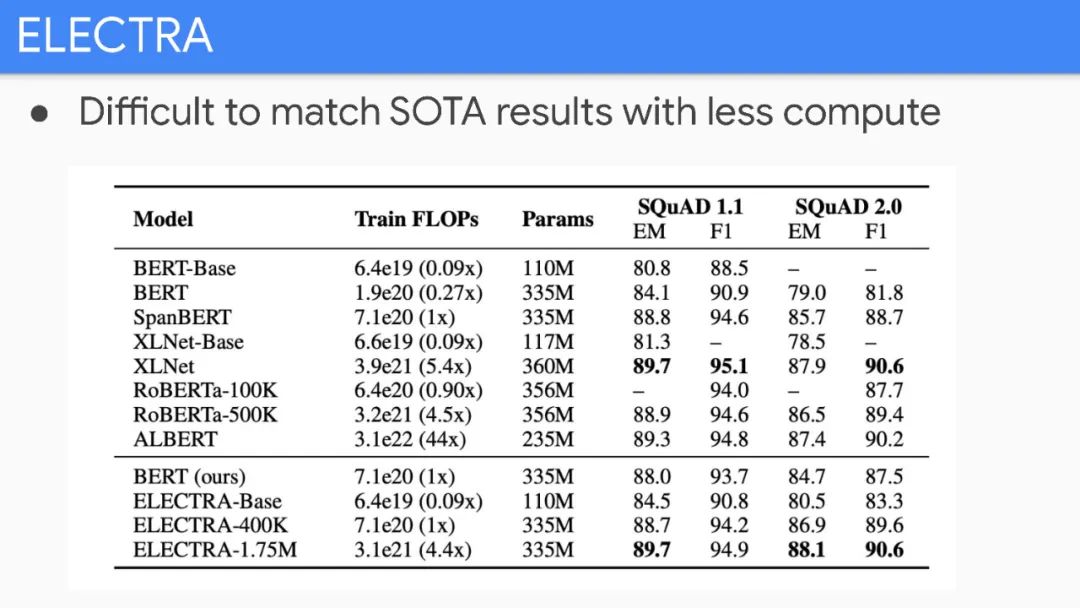
Unfortunately, improvements seem to primarily come from more expensive models and more data.
-
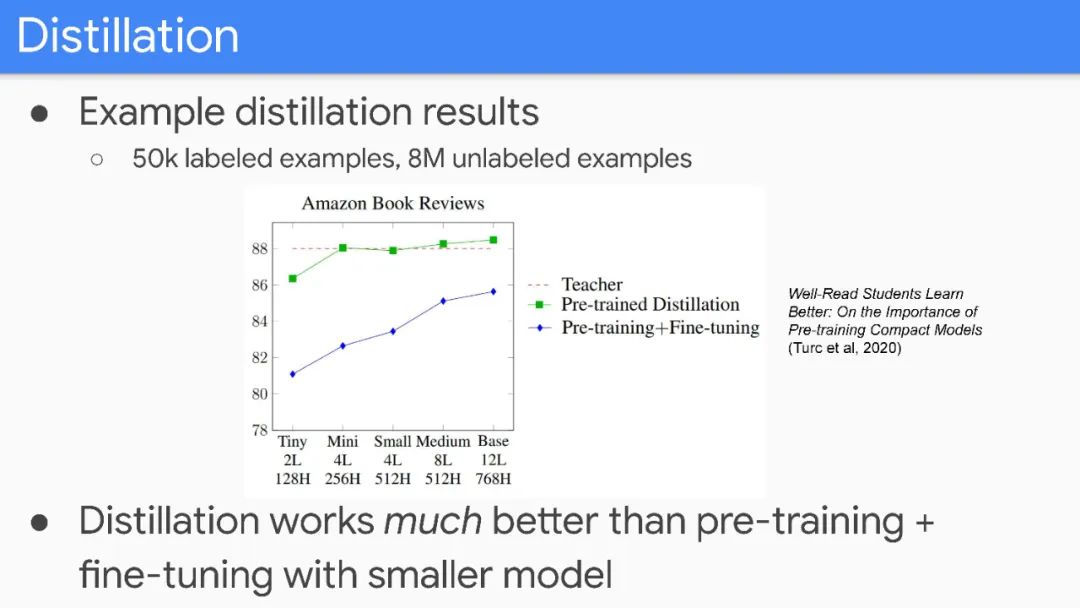
Inference/service issues are mostly “solved” through distillation.
Jacob Devlin is a researcher at Google. At Google, his primary research interest is developing fast, powerful, and scalable deep learning models for information retrieval, question answering, and other language understanding tasks. From 2014 to 2017, he served as a principal researcher at Microsoft Research, leading the transition from phrase-based translation to neural machine translation (NMT) for Microsoft Translator. Mr. Devlin is a recipient of the ACL 2014 Best Long Paper Award and the NAACL 2012 Best Short Paper Award. In 2009, he obtained a Master’s degree in Computer Science from the University of Maryland, under the supervision of Dr. Bonnie Dorr.
https://web.stanford.edu/class/cs224n/index.html#schedule























Easy Access via Zhuanzhi
Easy Download, please followZhuanzhi public account (click the above blue Zhuanzhi to follow)
Reply “B43” to obtain“Google BERT Author Jacob Stanford Teaches “Contextual Word Vectors and Pre-trained Language Models: From BERT to T5” 43-page PPT” download link