
Zheng Jiyang from Aofeisi QbitAI Report | WeChat Official Account QbitAI
Recently, the Amazon Alexa team released a research achievement: researchers performed parameter selection on the BERT model, obtaining the optimal parameter subset of BERT—Bort.
The research results indicate that Bort is only 16% the size of BERT-large, but its speed on CPU is 7.9 times faster, and its performance on NLU benchmark tests surpasses that of BERT-large.
This is a relatively successful result against the backdrop of the rapid “expansion” of NLP models and the urgent need for model lightweighting.
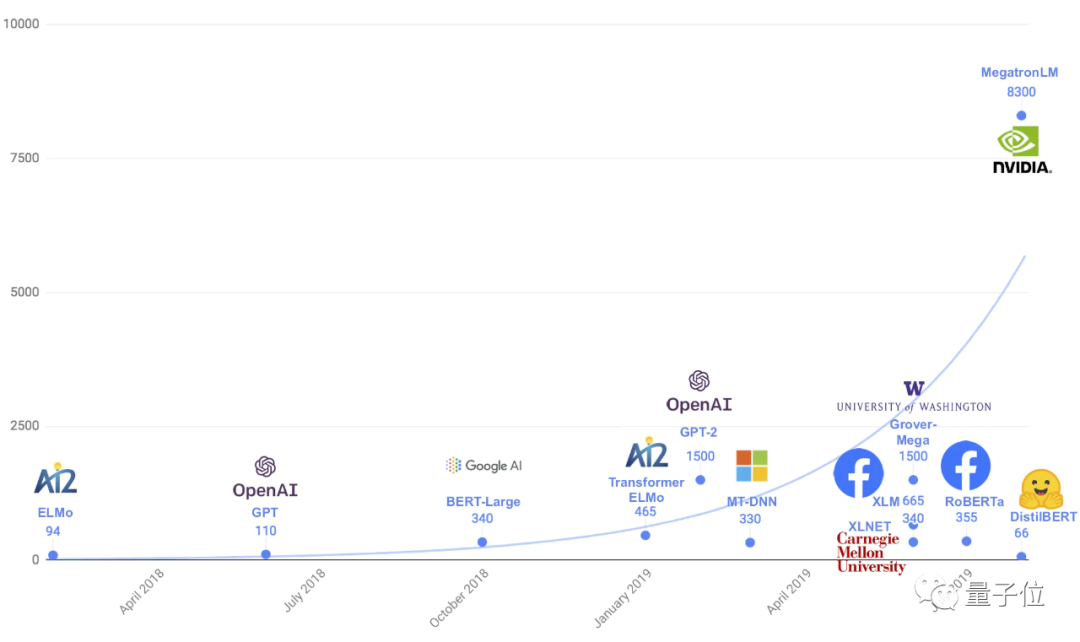
NLP Model Size △ Image Source: DistilBERT
Unlike the model structure optimizations performed with ALBERT and MobileBERT, Bort was developed through optimal subset selection on the original model architecture.
In simple terms: “slimming down”.
So, how did the researchers “slim down” BERT?
Next, let us take a closer look.
FPTAS Assists in “Slimming Down”
First, it should be clear that this is not the first time researchers have attempted to “slim down” BERT.
Due to BERT’s large scale, slow inference speed, and complex preprocessing, some researchers have previously tried to slim it down, achieving certain results: maintaining the same performance as its predecessor, simplifying the pre-training process while reducing inference time.
However, in terms of accuracy, the slimmed-down subsets have always been somewhat unsatisfactory—failing to reach the original performance of BERT.

In this study, researchers used the Fully Polynomial Time Approximation Scheme (FPTAS) to further optimize this problem, as this algorithm has recently been proven to effectively extract such optimal subsets under certain conditions.
In this regard, the researchers stated:
This condition is referred to as the strong AB^nC property, and we have proven that BERT satisfies this set of conditions.
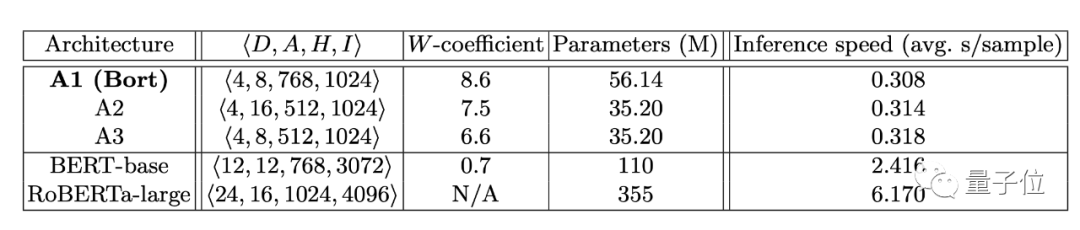
Researchers listed three metrics: inference speed, parameter size, and error rate. Using FPTAS, they extracted an optimal subset from a high-performance BERT, which is Bort.
In subsequent preliminary tests, Bort performed well. On CPU, its inference speed is 7.9 times faster than BERT-large.
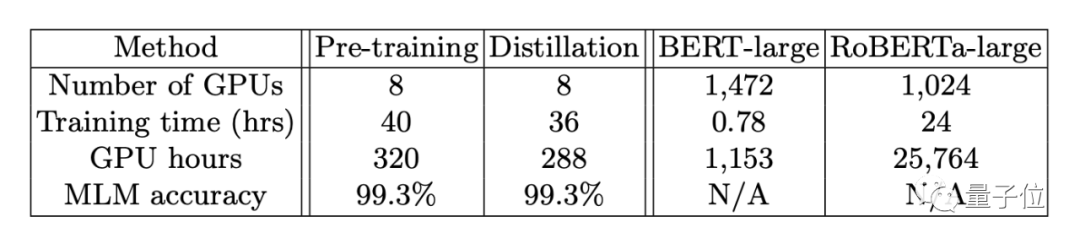
Additionally, on the same hardware, pre-training on the same dataset, Bort only took 288 GPU hours. In contrast, BERT-large took 1153 GPU hours, while RoBERTa-large required 25764 GPU hours.
“Slimming down” was successful!
Thinner and Stronger
After slimming down, does it mean that, like previous similar studies, the capability has decreased? This is a very critical question.
To validate Bort’s generalization ability, researchers tested Bort against other models on GLUE and SuperGLUE benchmarks and the RACE dataset.
First, testing on GLUE:
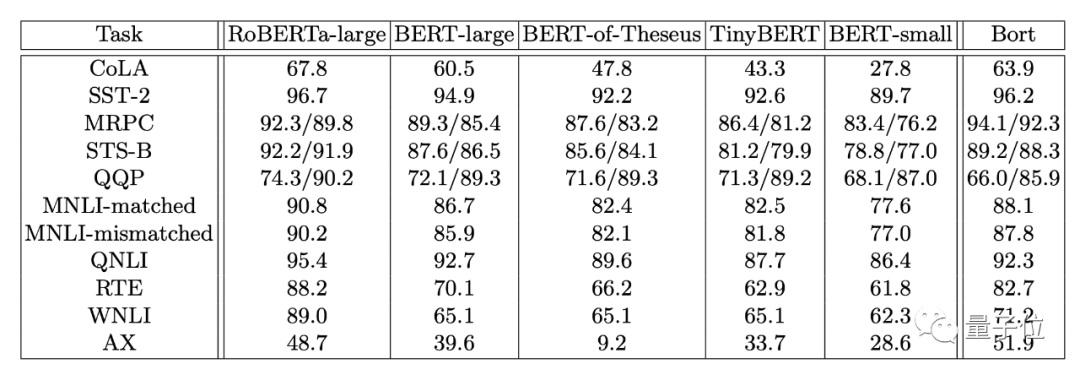
Bort achieved excellent results in almost all tasks: except for QQP and QNLI, its performance is significantly better than several other similar models based on BERT.
Notably, for BERT-large, Bort’s performance improved by 0.3% to 31%.
Next, testing on SuperGLUE:
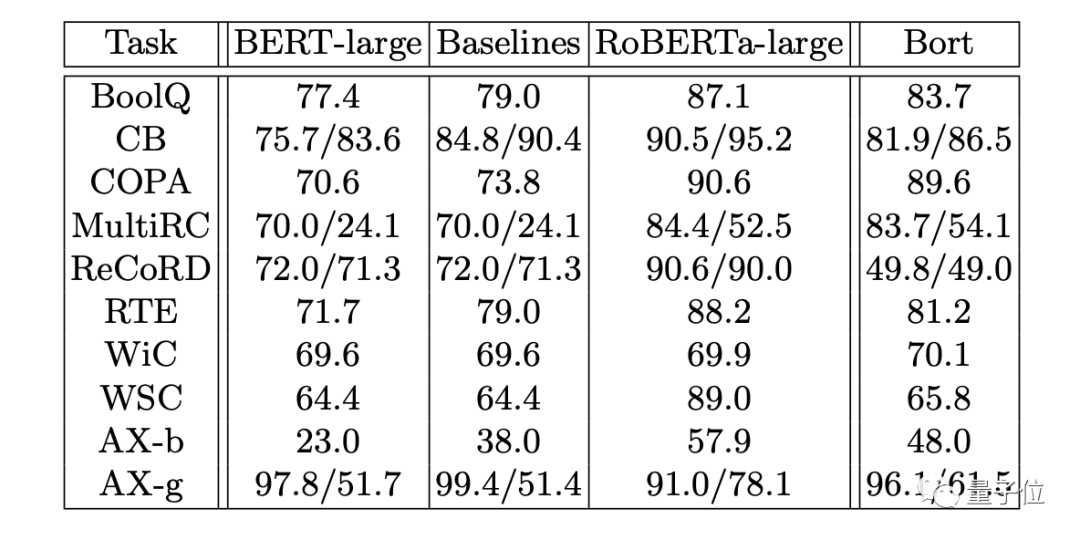
Bort also achieved good results, exhibiting performance superior to or equivalent to BERT-large in all tasks except one (ReCoRD).
Finally, testing on RACE:

Overall, Bort achieved good results, outperforming BERT-large by 9-10% on these two tasks.
Regarding the NLU test results, researchers summarized:
On the NLU benchmark tests of GLUE, SuperGLUE, and RACE, Bort has improved performance in various aspects compared to BERT-large, ranging from 0.3% to 31%.
Finally, researchers also published the code for Bort on GitHub. The paper and code links are as follows, readers in need can take them.
Paper link:https://arxiv.org/pdf/2010.10499.pdf
Code link:https://github.com/alexa/bort
— The End —
This article is original content from NetEase News • NetEase account special content incentive plan signed account【QbitAI】. Unauthorized reproduction is prohibited.
Quantum Bit Annual Intelligent Business Summit Commencement,
AI experts such as Li Kaifu gather,
inviting you to explore the development path of the intelligent industry under the new situation


Quantum BitQbitAI · Headline Account Signed Author
v’ᴗ’ v Tracking AI technology and product new dynamics
One-click three connections: “Share”, “Like” and “View”
Daily updates on cutting-edge technological advancements~