Introduction
Remember not long ago in the field of machine reading comprehension, where Microsoft and Alibaba surpassed humans on SQuAD with R-Net+ and SLQA respectively, and Baidu topped the MS MARCO leaderboard with V-Net while exceeding human performance on BLEU? These networks can be said to be increasingly complex, and it seems that the research direction of “how to design a more effective task-specific network” has become politically correct in the NLP field. In this trend, whether it’s word2vec, glove, or fasttext, they can only play a supplementary role. Where is the promised transfer learning and pre-training? It seems they have never taken center stage in NLP.
While writing this article, I felt a bit ashamed. After spending a considerable amount of time on representation and transfer, I intuitively felt that this should be the core issue of NLP, yet I haven’t produced any satisfactory experimental results until BERT came out a few days ago, which made me realize that poverty has limited my imagination╮( ̄▽ ̄””)╭ (crossed out), and I realized that my focus was too narrow.
Everyone has a different understanding of BERT. This article attempts to discuss BERT from the perspective of word2vec and ELMo. Let’s first briefly review the essence of word2vec and ELMo, and those who already understand it well can quickly scroll down to the BERT section.
Word2Vec
It’s all a cliché that is written repeatedly with enthusiasm. The release of Google’s word2vec in 2013 allowed various fields of NLP to flourish. It seemed that writing papers without using pre-trained word vectors was somewhat embarrassing. So what exactly is word2vec?
Model
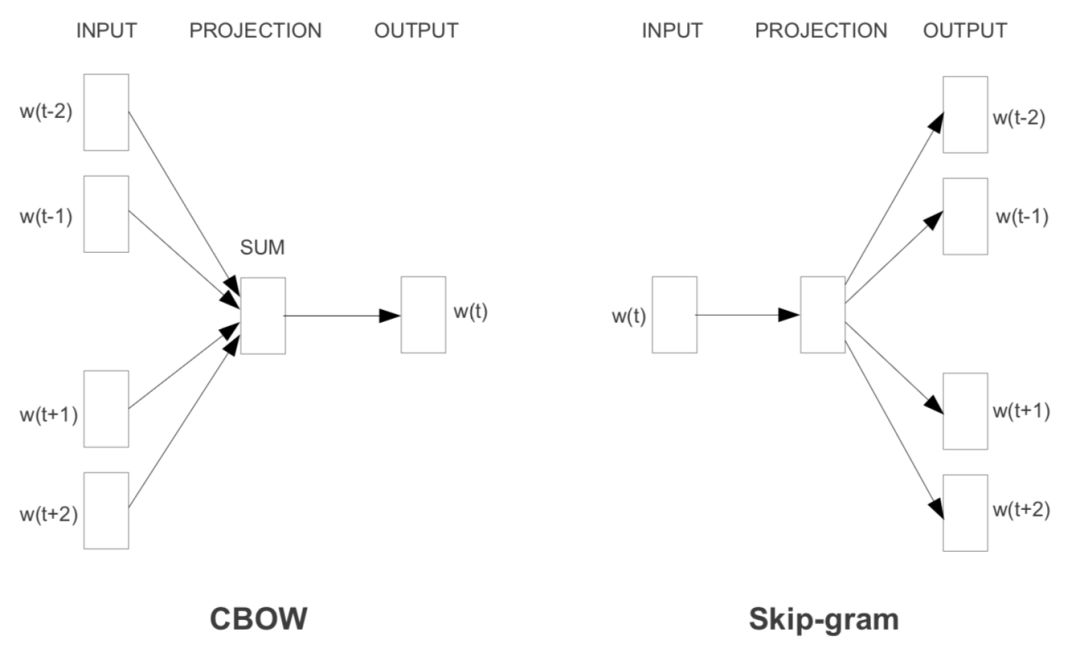
It’s clearly a “linear” language model. Since our goal is to learn word vectors, and word vectors should support some “linear semantic operations” semantically, such as “emperor – empress = man – woman” (ignoring Wu Zetian), then using a linear model is naturally sufficient, running fast and completing the task elegantly.  One essence of word2vec is that it optimized the softmax acceleration method from the language model, using a seemingly brain-opening method called “negative sampling” to replace traditional hierarchical softmax and NCE methods. But what exactly is this high-sounding “negative sampling”?
One essence of word2vec is that it optimized the softmax acceleration method from the language model, using a seemingly brain-opening method called “negative sampling” to replace traditional hierarchical softmax and NCE methods. But what exactly is this high-sounding “negative sampling”?
Negative Sampling
We know that for training language models, the softmax layer is very difficult to calculate. After all, you need to predict which word is at the current position, so the number of categories is equivalent to the size of the dictionary, which can reach tens of thousands or even hundreds of thousands. Calculating the softmax function is naturally very labor-intensive. However, if our goal is not to train an accurate language model but just to train the byproduct of the language model – the word vectors, then we only need to use a less computationally intensive “sub-task” implied here.
Think about it, if you have 10,000 cards with numbers written on them and you need to find the maximum value among them, isn’t that particularly laborious? But if you extract the maximum value beforehand, mix it with five randomly drawn cards, isn’t it much easier to find the maximum value among them?
Negative sampling is this idea, which means that instead of directly letting the model find the most likely word from the entire vocabulary, we directly provide this word (the positive example) and several randomly sampled noise words (the sampled negative examples). As long as the model can find the correct word from these, it is considered to have completed the goal. So the corresponding objective function is:
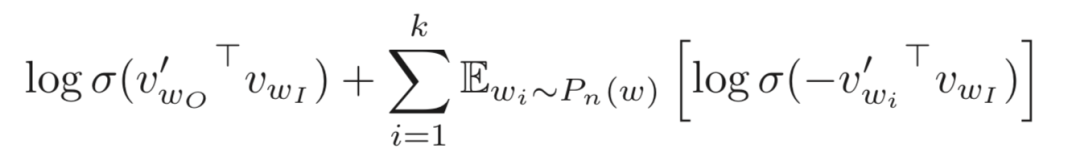
Here 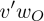 is the positive example,
is the positive example, 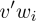 is the randomly sampled negative example (sampling k examples), and
is the randomly sampled negative example (sampling k examples), and 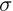 is the sigmoid function. Then we maximize the likelihood of the positive examples and minimize the likelihood of the negative examples.
is the sigmoid function. Then we maximize the likelihood of the positive examples and minimize the likelihood of the negative examples.
This idea of negative sampling has been successfully applied in the BERT model, but the granularity has shifted from words to sentences. Don’t rush; take your time to read on~
Character-level and Context
Although from 2015 to 2017, there were quite a few works trying to approach from the character-level, carving out a new path and breaking free from the game rules of pre-trained word vectors, the actual testing was just a flash in the pan, and they were soon criticized [8][9]. However, people also realized that character-level texts contain patterns that are difficult to describe with word-level texts. Therefore, on one hand, there appeared FastText, which can learn character-level features, while on the other hand, in supervised tasks, networks such as shallow CNN, HighwayNet, and RNN began to introduce character-level text representations.
However, until now, word vectors have been context-independent. That is to say, the same word always has the same word vector in different contexts, which clearly leads to a lack of word sense disambiguation (WSD) ability in word vector models. Thus, to make word vectors context-sensitive, people began encoding based on sequences of word vectors in specific downstream tasks.
The most common encoding method, of course, is using RNN-based networks. In addition, there have been successful works using deep CNN for encoding (such as text classification [6], machine translation [7], and machine reading comprehension [4]). However, Google said, CNN is too common; we want a fully connected network! (crossed out) self-attention! Thus, the Transformer model, customized for deep NLP, was born [11]. The introduction of the Transformer was for machine translation tasks, but it also played a significant role in other areas such as retrieval-based dialogue [3].
However, since it was discovered that there is a need for encoding in various NLP tasks, why not endow word vectors with context-sensitive capabilities from the very beginning? Thus, ELMo was created [2].
ELMo
Of course, ELMo is not the first model to attempt to produce context-sensitive word vectors, but it is a model that gives you sufficient reason to abandon word2vec (smiling manually). After all, sacrificing some inference speed for such a significant performance boost is worth it in most cases~ ELMo, at the model level, is a stacked bi-LSTM (strictly speaking, it trains two unidirectional stacked LSTMs), so it certainly has good encoding capability. Its source code implementation also supports using Highway Net or CNN to additionally introduce character-level encoding. Training it naturally involves maximizing the likelihood function standard for language models, which is:
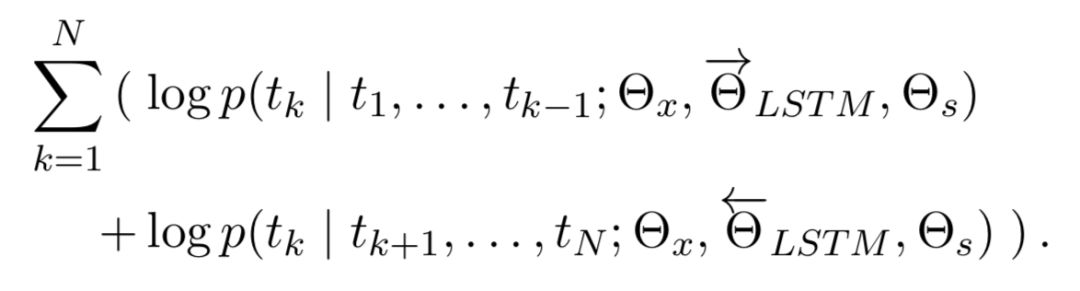
However, the highlight of ELMo is not at the model level, but rather its experimental evidence that shows that the features learned at different layers in multi-layer RNNs are indeed different. Therefore, ELMo suggests that when transferring to downstream NLP tasks after pre-training, a trainable parameter should be set for both the original word vector layer and the hidden layers of each RNN. These parameters are normalized through the softmax layer and multiplied by their corresponding layers and summed to achieve a weighting effect. Then, the word vectors obtained from the “weighted sum” are further scaled by a parameter to better adapt to downstream tasks.
ps: Actually, this last parameter is very important. For example, in word2vec, generally speaking, the variance of word vectors learned by cbow and sg is quite different. In this case, the variance that matches the word vectors suitable for the subsequent layers of downstream tasks converges faster and is more likely to perform better.
The mathematical expression is as follows
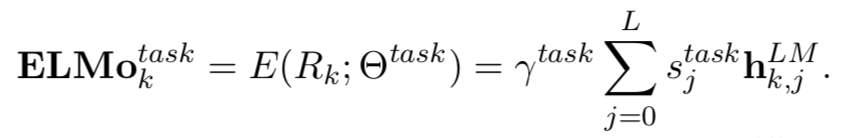 where L=2 is the setting in the ELMo paper, j=0 represents the original word vector layer, j=1 is the first hidden layer of LSTM, and j=2 is the second hidden layer.
where L=2 is the setting in the ELMo paper, j=0 represents the original word vector layer, j=1 is the first hidden layer of LSTM, and j=2 is the second hidden layer. 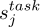 is the result after the parameters are normalized by softmax (that is,
is the result after the parameters are normalized by softmax (that is,  ).
).
Through this migration strategy, tasks that require word sense disambiguation can more easily train the second hidden layer with a significant weight, while tasks that have clear requirements for part of speech and syntax may learn larger values for the parameters of the first hidden layer (experimental conclusions). In summary, this results in a richer feature set of word vectors that can be customized for downstream tasks, making it unsurprising that the performance is much better than word2vec.
However, that said, the goal of ELMo is merely to learn context-sensitive, more powerful word vectors, and its purpose is still to provide a solid foundation for downstream tasks, with no intention of usurping the throne.
We know that merely performing adequate and powerful encoding (i.e., obtaining very precise and rich features for each word position) is not enough to cover all NLP tasks. In tasks like QA, machine reading comprehension (MRC), natural language inference (NLI), and dialogue, there are many more complex patterns to capture, such as inter-sentence relationships. Therefore, networks in downstream tasks will incorporate various fancy attention mechanisms (see SOTA in NLI, MRC, Chatbot).
As the need to capture more magical patterns increases, researchers have customized various network structures for each downstream task, leading to the same model performing poorly when changing tasks, and even significant performance loss when switching to another dataset under the same task. This clearly does not align with human language behavior~ It is essential to know that humans possess strong generalization abilities, which suggests that perhaps the entire trajectory of NLP development is incorrect, especially under the guidance of SQuAD, exhausting various tricks and complex structures to climb the leaderboard. What is the real significance of this to NLP?
It seems to have strayed far, but fortunately, this increasingly diverging path was finally shut down by a model released just a few days ago, which is Google’s Bidirectional Encoder Representations from Transformers (BERT) [1].
BERT
The most important significance of this paper lies not in what model was used or how it was trained, but in its proposal of a completely new game rule.
Before starting the game, could you help me click on a small advertisement? (//∇//)
As mentioned earlier, customizing complex model structures with poor generalization ability for each NLP task is indeed very unwise and has gone off track. Since ELMo shows such a significant improvement compared to word2vec, it indicates that the potential of pre-trained models goes far beyond just providing an accurate word vector for downstream tasks. So, can we directly pre-train a backbone-level model? If it has already fully described the features at the character, word, sentence, and even inter-sentence levels, then in different NLP tasks, we only need to customize a very lightweight output layer for the task (like a single-layer MLP) since the model skeleton has already been built.
BERT does exactly this, or rather, it has truly accomplished this. It, as a general backbone model, easily challenges deep customized models across 11 tasks.
So how does it accomplish this?
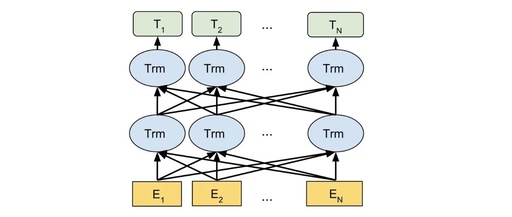
Deep Bidirectional Encoding
First, it points out that the previous pre-trained models are still not sufficient for learning context-sensitive word vectors! Although the encoding methods in supervised tasks have become very elaborate and sufficient, deep bidirectional encoding has basically become the standard for many complex downstream tasks (such as MRC, dialogue). However, in the pre-trained models, the previous state-of-the-art models were based on traditional language models, which are unidirectional (as mathematically defined). That is:
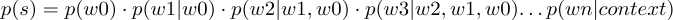
Moreover, they are often very shallow (imagine stacking three layers of LSTM, and it becomes untrainable, requiring various tricks). For example, ELMo.
Additionally, although ELMo uses bidirectional RNNs for encoding, these two directions of RNNs are actually trained separately, only combining them at the loss layer. This leads to the fact that for each word in a direction, when being encoded, it cannot see the words on the other side. Clearly, the semantics of some words in a sentence will depend on certain words on both sides, and encoding from a single direction cannot accurately describe this.
So why not perform true bidirectional encoding like in downstream supervised tasks?
The reason is obvious. After all, traditional language models are trained to predict the next word. However, if bidirectional encoding is performed, it means that the word to be predicted has already been seen ╮( ̄▽ ̄””)╭. Such predictions are, of course, meaningless. Therefore, BERT proposes a new task to train a model that can genuinely perform bidirectional encoding, called the Masked Language Model (Masked LM).
Masked LM
As the name suggests, the Masked LM means that instead of providing already appeared words to predict the next word, we directly mask part of the words in the entire sentence (randomly selected), allowing the model to confidently perform bidirectional encoding and predict the masked words. This task was initially called the cloze test.
This obviously leads to some minor issues. Although this allows for confident bidirectional encoding, it also means that the masked tokens are encoded, and these mask tokens do not exist in downstream tasks… So what to do? To help the model ignore the influence of these tokens, the authors inform the model as follows: “These are noise! Ignore them!” For a masked word:
-
There is an 80% probability of being replaced with the “[mask]” token.
-
There is a 10% probability of being replaced with a randomly sampled word.
-
There is a 10% probability of no replacement (although no replacement is made, it must still be predicted).
Encoder
In terms of encoder selection, the authors did not use the common bi-LSTM but opted for a Transformer encoder that allows for deeper layers and better parallelism. This way, each word can be encoded directly without regard to direction and distance. On the other hand, I feel that the Transformer is less likely to be affected by mask tokens, as the self-attention process can specifically weaken the matching weights for mask tokens, while it is unclear how the input gate in LSTM perceives mask tokens.
Wait, I mentioned in a previous article that directly using the Transformer encoder would clearly lose positional information. Did the authors also use the scary sin and cos functions to encode position like in the original Transformer paper? No, the authors took a very simple and straightforward approach by training a position embedding ╮( ̄▽ ̄””)╭. This means, for example, if I truncate the sentence to a length of 50, we have 50 positions, so there are 50 words representing positions, from position 0 to position 49… Then we give each positional word a randomly initialized word vector and train them together (I really want to say, can this work? It seems too simple and crude…). Furthermore, in BERT, the position embedding and word embedding are combined by simple addition.
Finally, in terms of depth, the complete version of BERT’s encoder stacks an insane 24 layers of multi-head attention blocks (consider that the SOTA model in dialogue only uses 5 layers…)… Each block contains 16 heads and 1024 hidden units ╮( ̄▽ ̄””)╭. Here’s a slogan: money is all you need (crossed out).
Learning Sentence and Sentence Pair Representations
As mentioned earlier, in many tasks, relying solely on encoding is insufficient to complete the task (this only learns a bunch of token-level features). It is also necessary to capture sentence-level patterns to complete tasks that require sentence representation, inter-sentence interaction, and matching, such as SLI, QA, and dialogue. For this, BERT introduces another extremely important yet lightweight task to attempt to learn this pattern.
Sentence-Level Negative Sampling
Remember that one of the essences of word2vec is the elegant negative sampling task to learn word vectors (word-level representation)? So what if we generalize this negative sampling process to the sentence level? This is the key to BERT learning sentence-level representation.
BERT does something similar to word2vec, but constructs a sentence-level classification task. That is, given a sentence (equivalent to the context in word2vec), the next sentence is the positive example (equivalent to the correct word in word2vec), and a randomly sampled sentence is used as the negative example (equivalent to the randomly sampled word in word2vec). Then, a binary classification is performed on this sentence-level task (to determine whether the sentence is the next sentence of the current one or noise). Through this simple sentence-level negative sampling task, BERT can easily learn sentence representations just like word2vec learns word representations.
Sentence Representation
Wait, after talking so much, how should the sentence be represented?
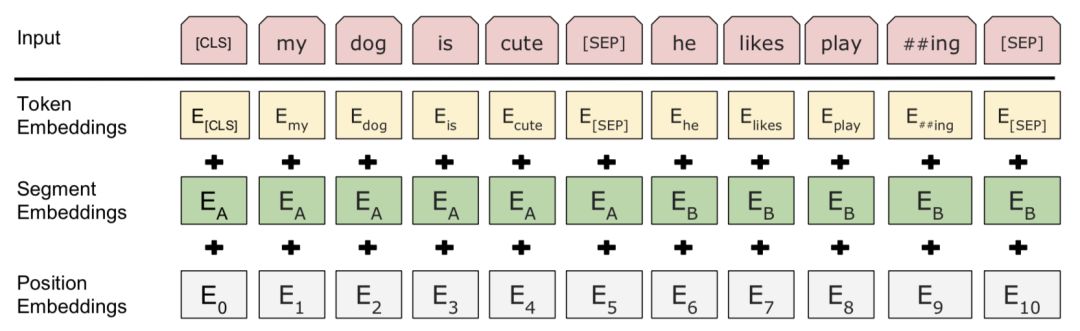
BERT does not adopt the common practice of adding a global pooling layer on top of the encoding as seen in downstream supervised tasks. Instead, it adds a special token, denoted as [CLS], at the beginning of each sequence (for sentence pair tasks, it is two sentences concatenated; for other tasks, it is a single sentence) as shown in the image 
ps: The [sep] here is the separator between sentences, and BERT supports learning sentence pair representations. The [SEP] is to indicate the cut-off point of the sentence pair.
Then, the encoder performs deep encoding on the [CLS] token. The highest hidden layer of deep encoding serves as the representation for the entire sentence/sentence pair. This approach may seem a bit confusing at first, but don’t forget that the Transformer can integrate global information into each position, and since [CLS] is directly connected to the output layer of the classifier, it will certainly learn the upper-layer features related to classification as a “checkpoint” in the gradient backpropagation path.
Furthermore, to help the model distinguish whether each word belongs to the “left sentence” or the “right sentence,” the authors introduced the concept of “segment embedding” to differentiate sentences. For sentence pairs, embedding A and embedding B are used to represent the left and right sentences, respectively; for single sentences, only embedding A is used. This embedding A and B are also trained with the model.
This method feels simple and crude, and I really don’t understand why BERT can still work on theoretically symmetric tasks like “quora question pairs”. My feelings are complicated.

Thus, the representation of each token in BERT is formed by the summation of the token’s original word vector token embedding, the previously mentioned position embedding, and the segment embedding introduced here, as shown in the image:
Overly Simple Downstream Task Interfaces
What truly reflects that BERT is a backbone-level model rather than just a word vector is its interface design for various downstream tasks, or in more fashionable terms, the transfer strategy.
First, since we have obtained the upper-layer representations for sentences and sentence pairs, then for text classification tasks and text matching tasks (text matching is essentially a text classification task, just that the input is a text pair), we only need to use the obtained representations (the top output at the [CLS] token from the encoder) and add a layer of MLP.
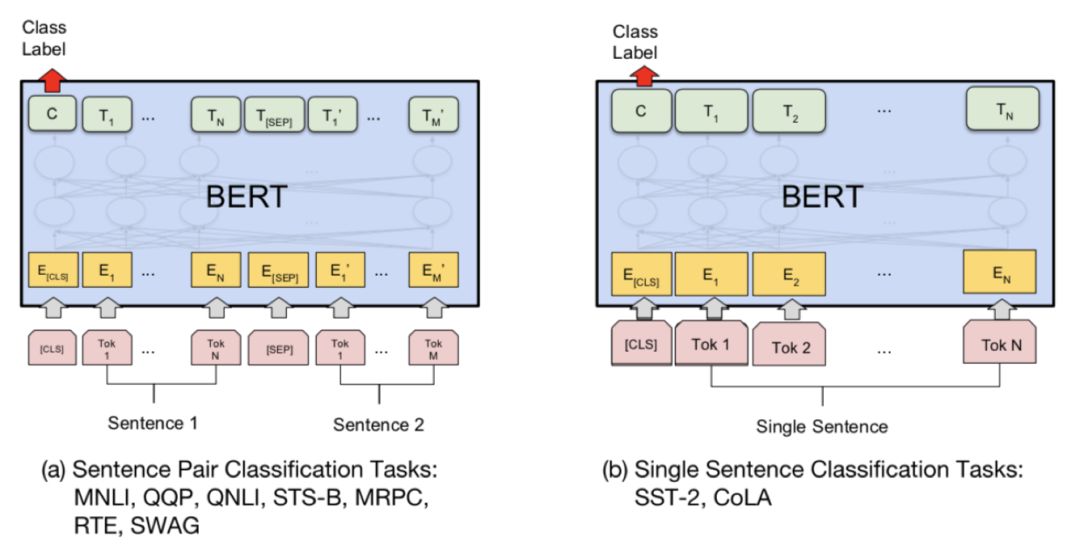
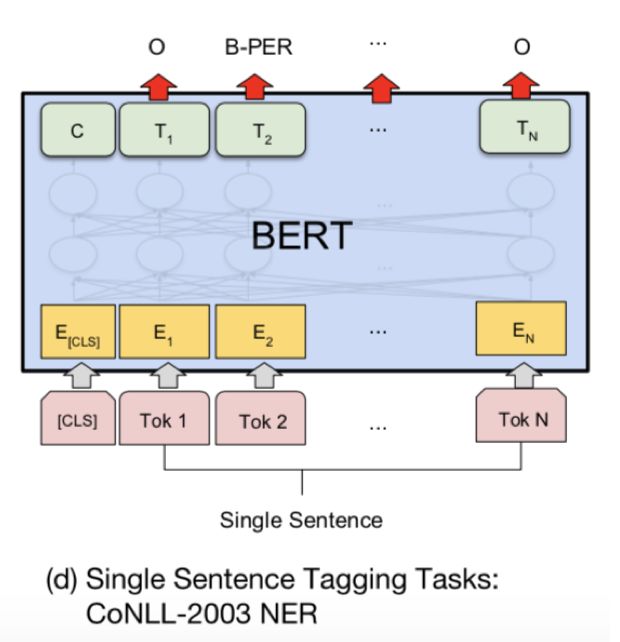
Since the text has been deeply bidirectionally encoded, for sequence labeling tasks, we only need to add a softmax output layer, without even needing CRF.
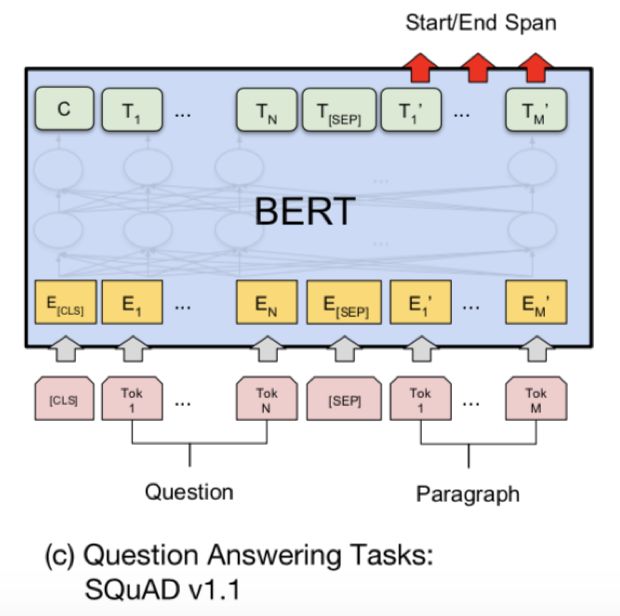
What surprised me even more is that in span extraction tasks like SQuAD, they even dared to discard the pointer net of the output layer and directly use two linear classifiers to output the start and end points of the span, just like DrQA? No more words, I am kneeling m(_ _)m
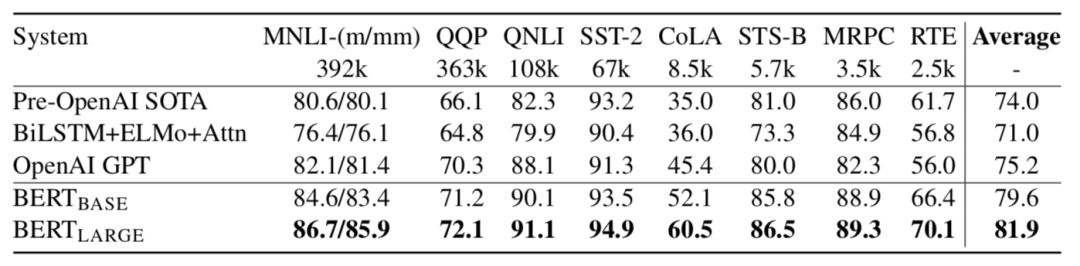
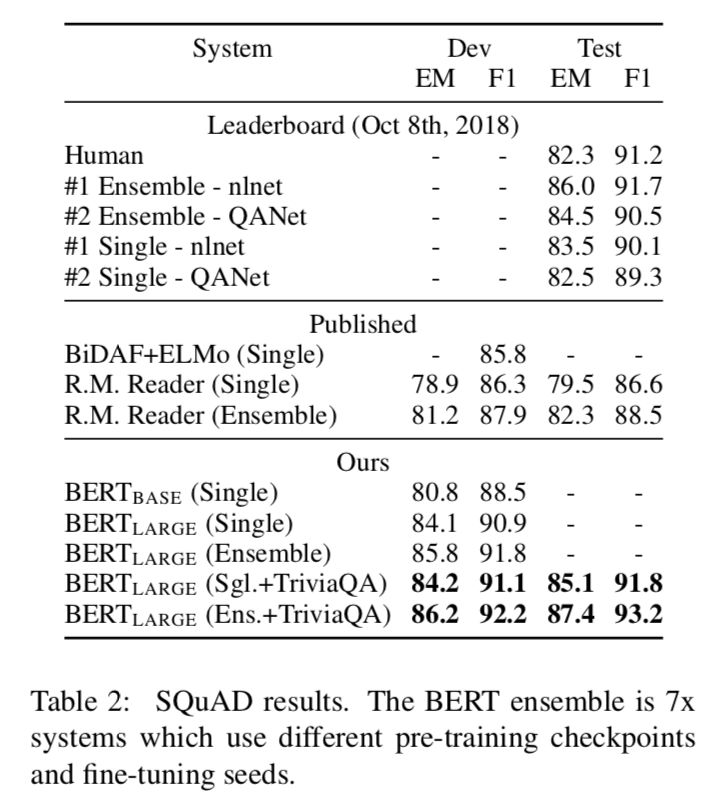
Finally, let’s take a look at the experimental results

Well, this is very Google.
With the release of this paper, I am very happy because many previous ideas no longer need to be experimentally verified, as they have already been crushed by BERT (。 ́︿ ̀。). Classification, labeling, and transfer tasks can all start from scratch, and the building plan for SQuAD can also stop. Thanks to BERT for not running a generative task, which leaves a bit of imagination space. Well, smiling manually with tears.
References
[1] 2018 | BERT- Pre-training of Deep Bidirectional Transformers for Language Understanding[2] 2018 NAACL | Deep contextualized word representations[3] 2018 ACL | Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network[4] 2018 ICLR | Fast and Accurate Reading Comprehension by Combining Self-Attention and Convolution[5] 2017 TACL | Enriching Word Vectors with Subword Information[6] 2017 ACL | Deep Pyramid Convolutional Neural Networks for Text Categorization[7] 2017 | Convolutional Sequence to Sequence Learning[8] 2017 | Do Convolutional Networks need to be Deep for Text Classification?[9] 2016 | Convolutional Neural Networks for Text Categorization/ Shallow Word-level vs. Deep Character-level[10] 2013 NIPS | Distributed-representations-of-words-and-phrases-and-their-compositionality