
Machine Heart Reprint
Source: Xixiaoyao’s Cute Selling House
Author: Sheryc_Wang Su
There are two types of highly challenging engineering projects in this world: the first is to maximize something very ordinary, like expanding a language model to write poetry, prose, and code like GPT-3; while the other is exactly the opposite, to minimize something very ordinary. For NLPers, this kind of “small project” is most urgently needed for BERT.

-
Paper Title: EdgeBERT: Optimizing On-Chip Inference for Multi-Task NLP
-
Paper Link: https://arxiv.org/pdf/2011.14203.pdf
-
Source: ALBERT: A Lite BERT for Self-supervised Learning of Language Representations (ICLR’20)
-
Link: https://arxiv.org/pdf/1909.11942.pdf
-
Embedding Layer Decomposition: In BERT, the embedding dimension of WordPiece is consistent with the hidden layer dimension in the network. The authors propose that the embedding layer encodes context-independent information, while the hidden layer adds context information on this basis, so it should have a higher dimension; at the same time, if the embedding layer and hidden layer dimensions are consistent, increasing the hidden layer dimension will significantly increase the embedding layer parameter count. Therefore, ALBERT decomposes the embedding layer into matrices, introducing an additional embedding layer E. Let the vocabulary size of WordPiece be V, the embedding layer dimension be E, and the hidden layer dimension be H, then the embedding layer parameter count can be reduced from O(V x H) to O(V x E + E x H).
-
Parameter Sharing: In BERT, each Transformer layer has different parameters. The authors propose sharing all parameters of the Transformer layers across layers, thus compressing the parameter count to only the level of a single Transformer layer.
-
Next Sentence Prediction Task → Sentence Order Prediction Task: In BERT, in addition to the MLM task of the language model, there is also a next sentence prediction task, which judges whether sentence 2 is the next sentence of sentence 1. However, this task has been confirmed to have mediocre performance by models such as RoBERTa and XLNET. The authors propose replacing it with a sentence order prediction task, which judges the order of sentences 2 and 1 to learn text consistency.
-
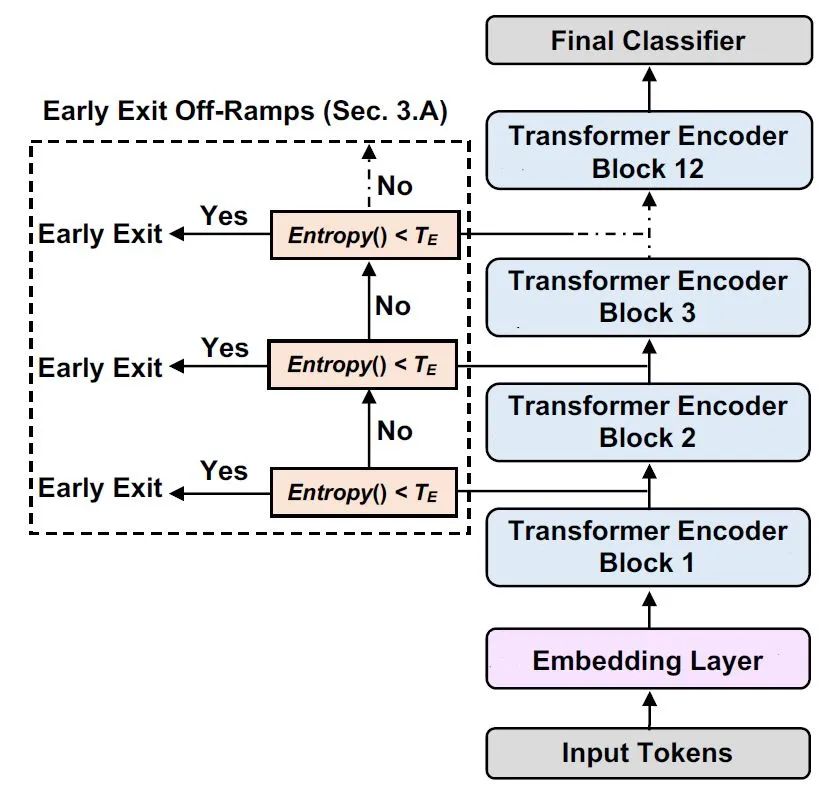
Source: DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference (ACL’20)
-
Link: https://arxiv.org/pdf/2004.12993.pdf
-
Source: Adaptive Attention Span in Transformers (ACL’19)
-
Link: https://arxiv.org/pdf/1905.07799.pdf
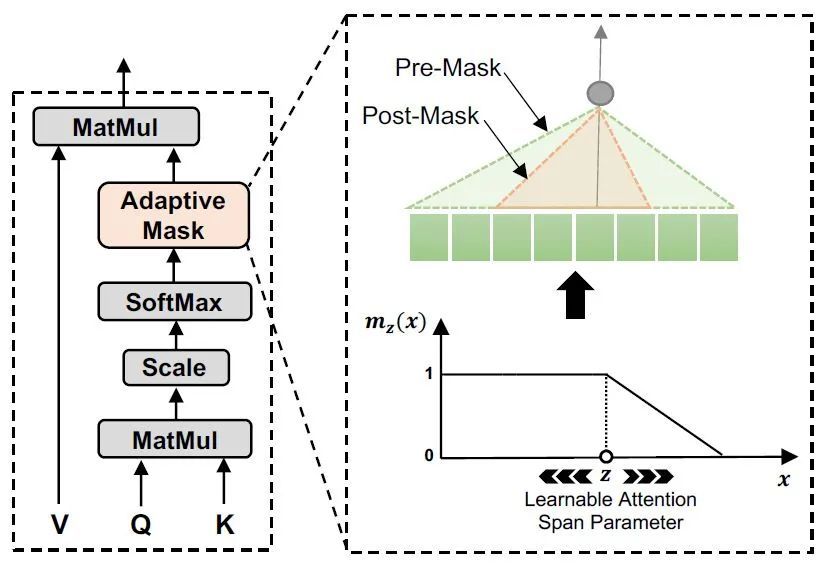
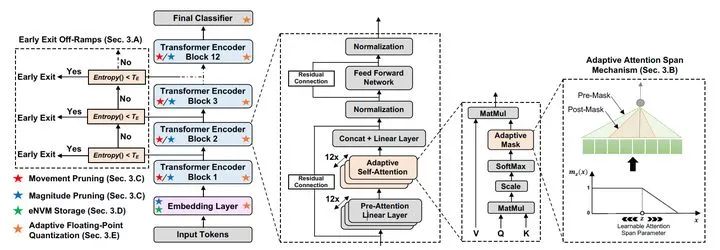
 calculates attention weights based on the distance between two tokens using soft masking. The weights in the attention mechanism
calculates attention weights based on the distance between two tokens using soft masking. The weights in the attention mechanism  become:
become:
 is a hyperparameter that controls the degree of soft masking, and
is a hyperparameter that controls the degree of soft masking, and  is the length of the sequence up to token
is the length of the sequence up to token  (the original text used a Transformer Decoder structure to learn the language model, so each token can only compute attention with its preceding tokens. In EdgeBERT, the formula is not mentioned, but based on the model diagram structure, the denominator should be modified to sum over the entire sequence). The boundary of the mask function
(the original text used a Transformer Decoder structure to learn the language model, so each token can only compute attention with its preceding tokens. In EdgeBERT, the formula is not mentioned, but based on the model diagram structure, the denominator should be modified to sum over the entire sequence). The boundary of the mask function  will vary with the head-related parameters and the current input sequence: for each head in the attention mechanism
will vary with the head-related parameters and the current input sequence: for each head in the attention mechanism  , there are
, there are  where
where  and
and  are trainable, and
are trainable, and  is a sigmoid function.
is a sigmoid function. doesn’t even need to be calculated; directly assign each head a learnable
doesn’t even need to be calculated; directly assign each head a learnable  without considering the input sequence, resulting in only 12 additional parameters
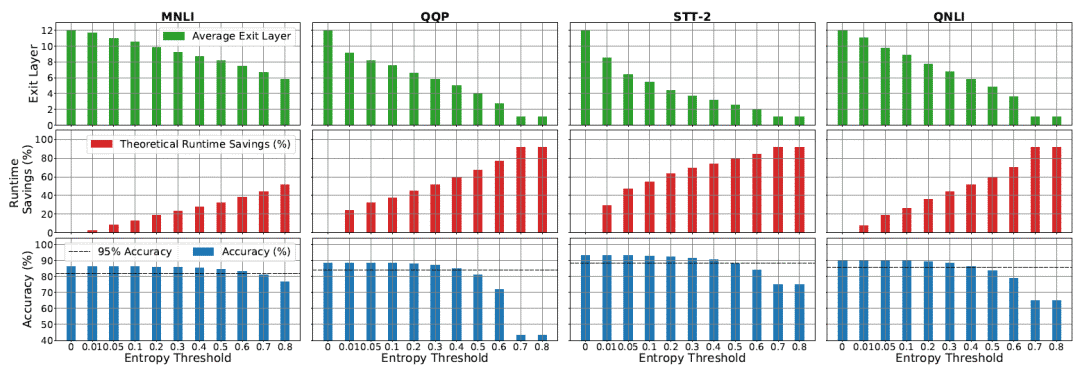
without considering the input sequence, resulting in only 12 additional parameters  (because there are 12 heads). So what are the results of this approach? The authors pad/truncate all sequences to a length of 128, and through experiments, they obtained an astonishing result:
(because there are 12 heads). So what are the results of this approach? The authors pad/truncate all sequences to a length of 128, and through experiments, they obtained an astonishing result: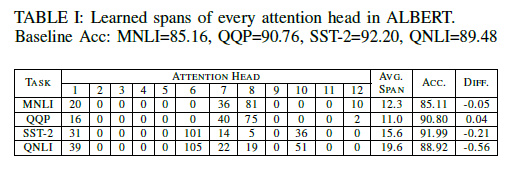
 values of each head after optimization, and the model’s accuracy on the four tasks (MNLI/QQP/SST-2/QNLI). With most heads effectively masked (
values of each head after optimization, and the model’s accuracy on the four tasks (MNLI/QQP/SST-2/QNLI). With most heads effectively masked ( ), the model surprisingly only lost 0.5 or even 0.05 in accuracy on these tasks! This method also brought the highest
), the model surprisingly only lost 0.5 or even 0.05 in accuracy on these tasks! This method also brought the highest  reduction in computation.
reduction in computation.-
Source: Movement Pruning: Adaptive Sparsity by Fine-Tuning (NeurIPS’20)
-
Link: https://arxiv.org/pdf/2005.07683.pdf
 , assign the same size importance scores
, assign the same size importance scores  to them, and the pruning mask
to them, and the pruning mask  .
.

 to obtain the gradient of the importance scores
to obtain the gradient of the importance scores  :
:


 is positive, the importance
is positive, the importance  increases, indicating that only when positive parameters increase or negative parameters decrease during backpropagation will a larger importance score be obtained, avoiding pruning.
increases, indicating that only when positive parameters increase or negative parameters decrease during backpropagation will a larger importance score be obtained, avoiding pruning.-
Source: Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding (ICLR’16)
-
Link: https://arxiv.org/pdf/1510.00149.pdf

-
Source: AdaptivFloat: A Floating-point based Data Type for Resilient Deep Learning Inference (arXiv Preprint)
-
Link: https://arxiv.org/pdf/1909.13271.pdf

 .
. .
. selection allows
selection allows  to be distributed almost evenly on both sides of the number line (for example, in 32-bit floating-point FP32, the exponent range is to), but such numbers as parameters for machine learning models are clearly not suitable: to increase the precision of fractions, we even have to allow
to be distributed almost evenly on both sides of the number line (for example, in 32-bit floating-point FP32, the exponent range is to), but such numbers as parameters for machine learning models are clearly not suitable: to increase the precision of fractions, we even have to allow  numbers that clearly will not occur, which is really a waste of memory!
numbers that clearly will not occur, which is really a waste of memory! based on model parameters. The so-called dynamic means that each tensor can receive a custom
based on model parameters. The so-called dynamic means that each tensor can receive a custom  . The method is also simple: find the largest number in the tensor and ensure that it can be covered by the exponent range. However, saying it’s simple requires many other modifications to the existing floating-point representation to achieve this method, so if you’re interested, you can check out the original AdaptivFloat paper, and also refer to the IEEE 754 standard [5]!
. The method is also simple: find the largest number in the tensor and ensure that it can be covered by the exponent range. However, saying it’s simple requires many other modifications to the existing floating-point representation to achieve this method, so if you’re interested, you can check out the original AdaptivFloat paper, and also refer to the IEEE 754 standard [5]!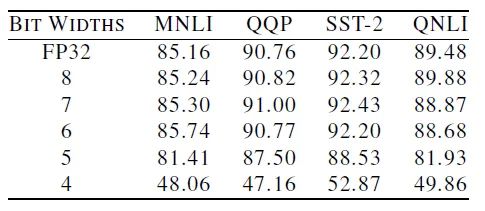
-
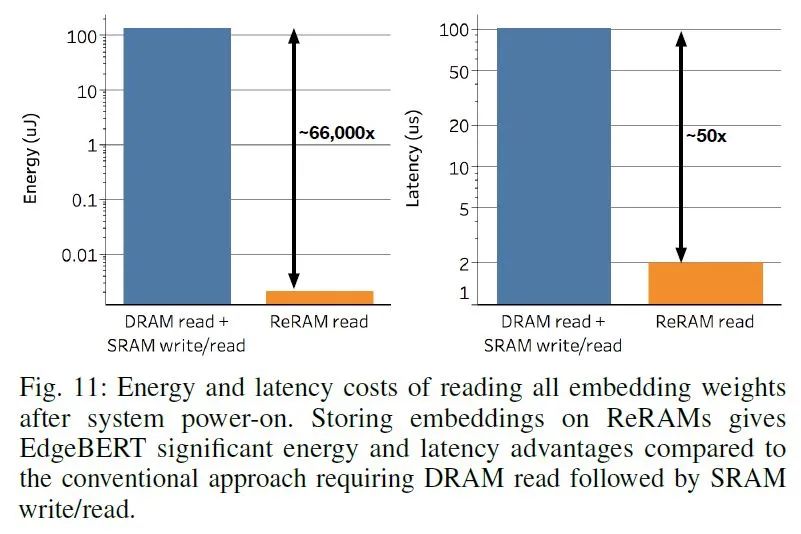
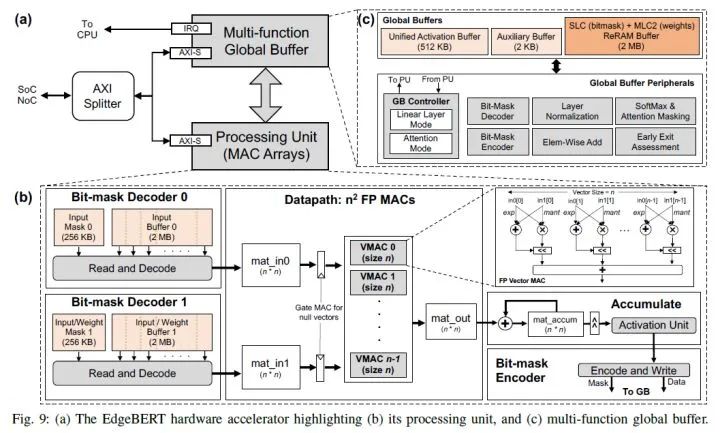
Embedding Layer: Stores the embedding vectors. EdgeBERT generally does not modify the embedding layer during downstream task fine-tuning. These parameters are equivalent to read-only parameters, requiring high-speed reading and hoping to retain original data during power loss to reduce data read/write overhead, so low-energy, fast-reading eNVM (Embedded Non-Volatile Memory) is suitable. The choice here is MLC-based ReRAM, a low-power, high-speed RAM.
-
Other Parameters: These parameters need to be changed during fine-tuning. SRAM is used here (unlike computer memory DRAM, SRAM is more expensive but consumes less power and has higher bandwidth, often used to make cache or registers).
-
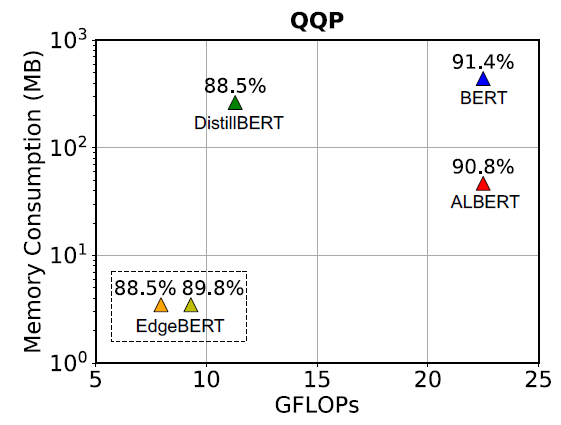
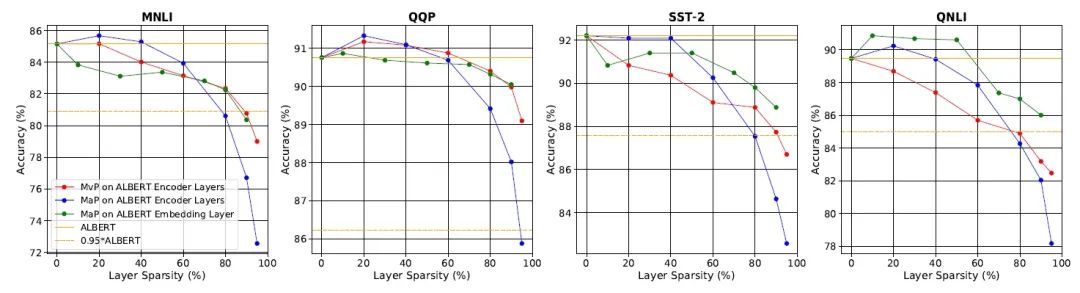
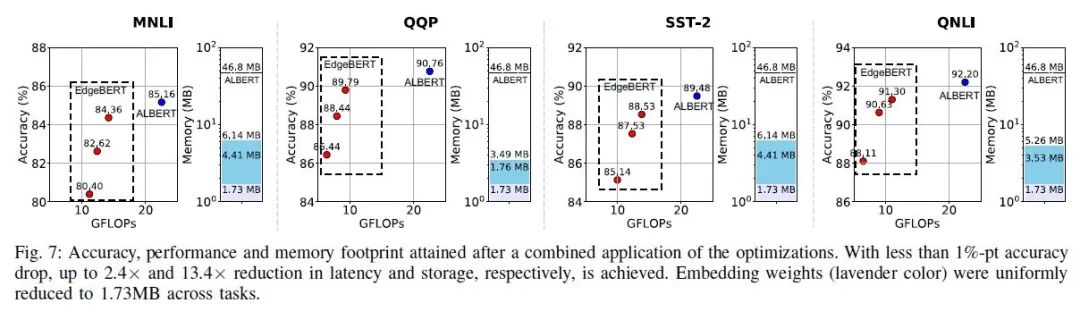
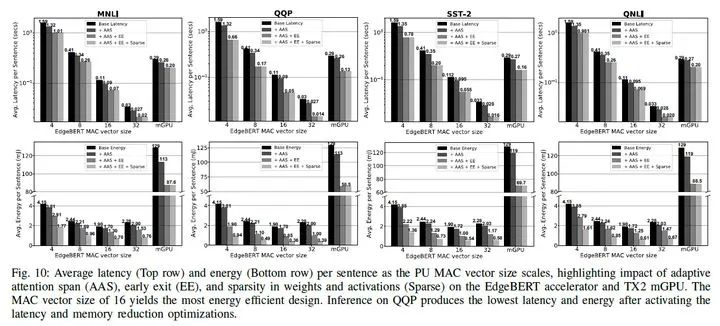
When the performance (accuracy) decreases by 1 percentage point compared to ALBERT, EdgeBERT can achieve reduced memory and inference speed; when the decrease is 5 percentage points, it can even achieve a reduction in inference speed.
-
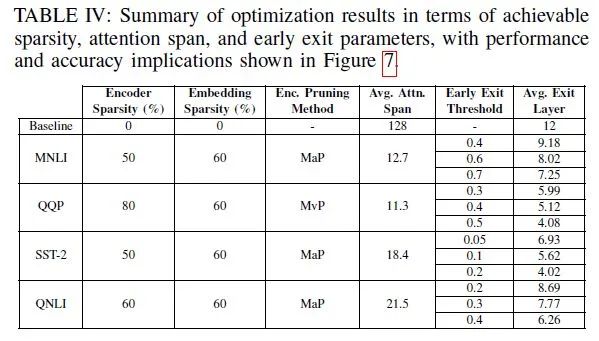
The embedding has been pruned to retain only 40%, resulting in the storage of the embedding layer parameters in eNVM being only 1.73MB.
-
The Transformer parameters of QQP have been masked by 80%, while those of MNLI, SST-2, and QNLI have been masked by 60% with only a 1 percentage point drop in performance.


© THE END
Reprint please contact this public account for authorization
Submission or seeking coverage: [email protected]