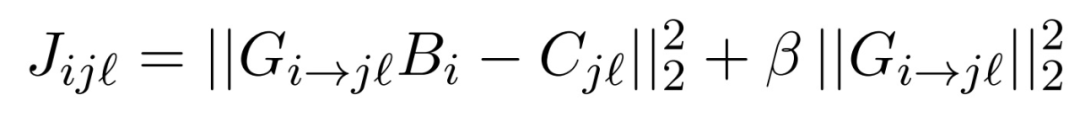
Analyst Network of Machine Heart
Analyst: Wu Jiying
Editor:Joni Zhong
As an important research topic in the fields of computer science and artificial intelligence, Natural Language Processing (NLP) has been extensively studied and discussed across various domains. With the deepening of research, some scholars have begun to explore whether there are connections between natural language processing in machines and in the brain, extending to the intersection of neuroscience and NLP pre-training methods like BERT. This article selects three papers from the CMU Wehbe research group (2 papers) and MIT Professor Roger P. Levy’s group (1 paper) to provide a detailed analysis and discussion on this topic.
-
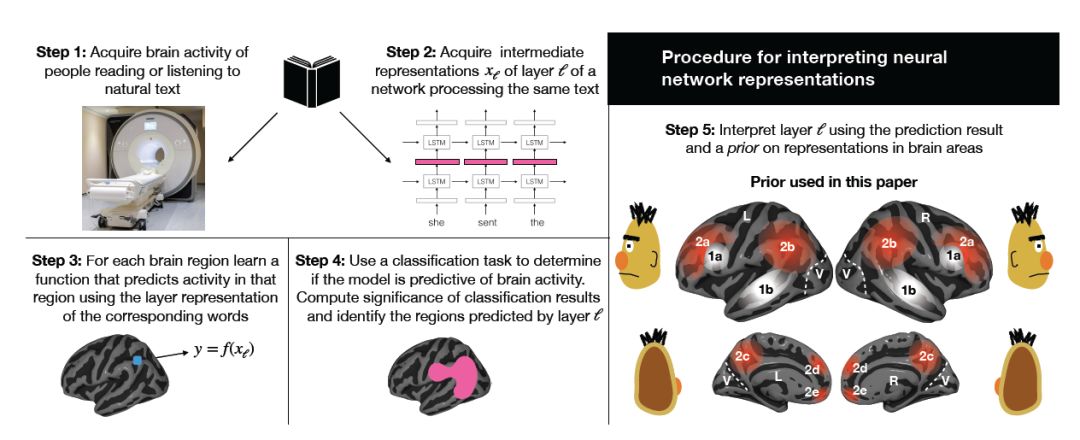
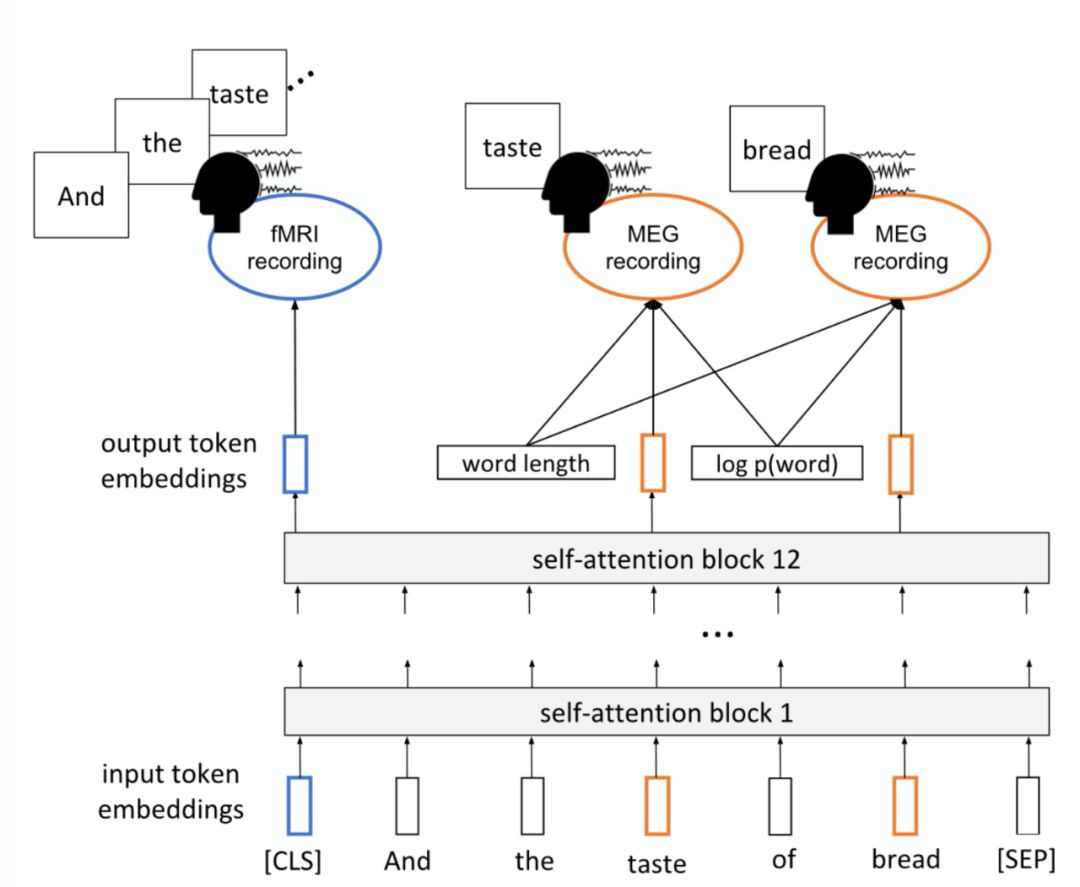
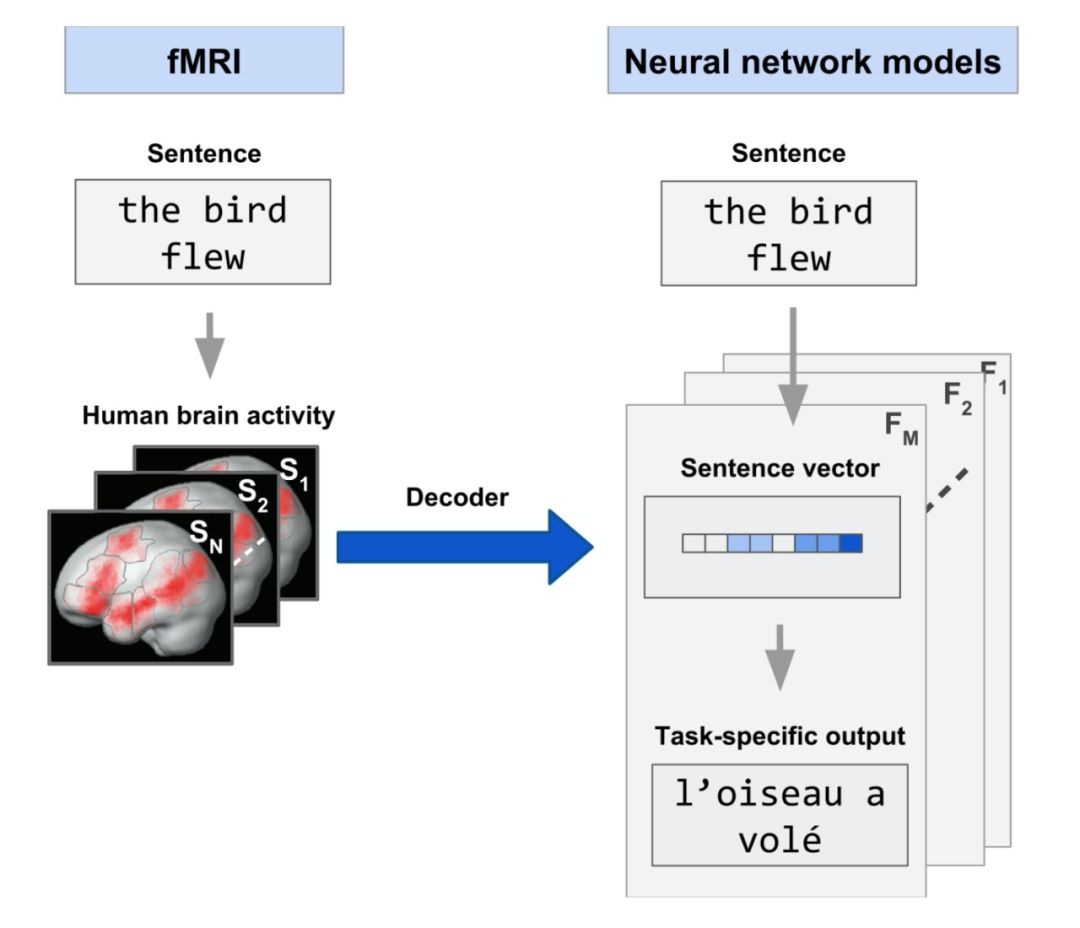
A method that utilizes brain activity records from subjects reading natural text to compare and explain the representations generated by different neural networks (“Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain)”). This paper aligns four NLP models: ELMO, BERT, USE, T-XL, with two methods of brain activity recording: functional magnetic resonance imaging (fMRI) and magnetoencephalography (MEG), demonstrating what information corresponding to brain recordings is contained in the representations extracted by different NLP models, such as contextual information, part-of-speech information, etc.
-
Encoding target information from prediction tasks into model parameters to improve BERT’s capability in predicting neural activity related to language processing in the brain (“Inducing brain-relevant bias in natural language processing models”). While recording brain activity using neuroimaging devices (fMRI, MEG), subjects are presented with language stimuli (e.g., reading a chapter of a book word by word or listening to a story), using the representations extracted from NLP models corresponding to the presented text to simulate the recorded brain activity. By fine-tuning BERT to find representations that generalize well to both human brains and the types of recordings, improvements to BERT are achieved.
fMRI is very sensitive to changes in oxygen content in the blood caused by neural activity, possessing high spatial resolution (2-3 mm) but low temporal resolution (multiple seconds). MEG is primarily used to measure changes in the magnetic field outside the skull caused by neural activity, characterized by low spatial resolution (multiple centimeters) but high temporal resolution (up to 1KHz).
A voxel (volume pixel) is a volume element in three-dimensional space, representing the smallest unit of digital data in three-dimensional space (volume and pixel). In fMRI, the MRI pixel intensity is proportional to the signal intensity of the corresponding voxel.
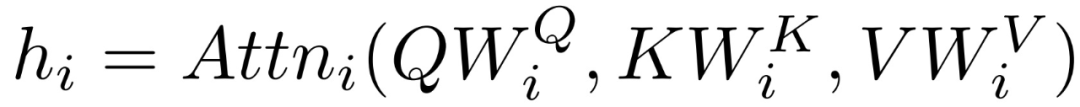

-
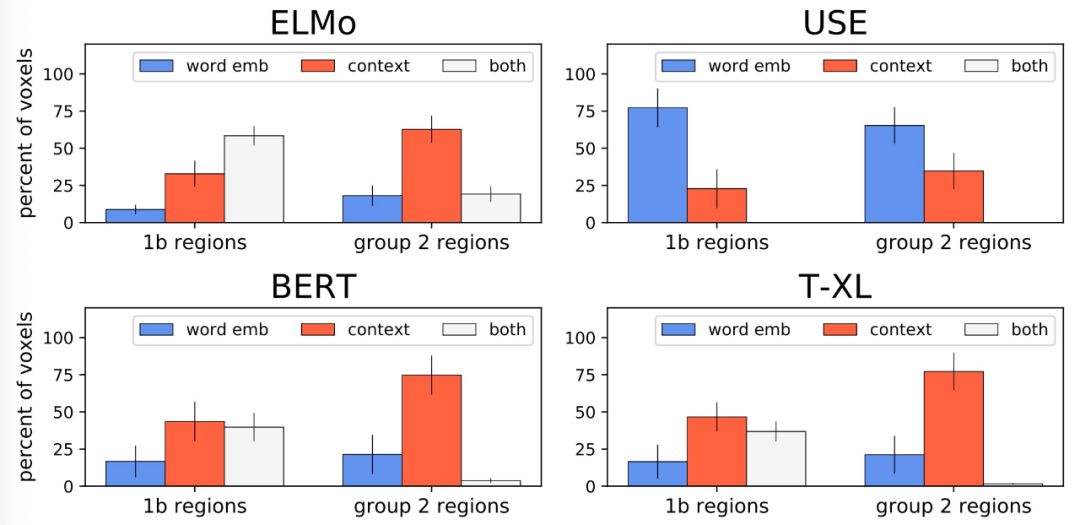
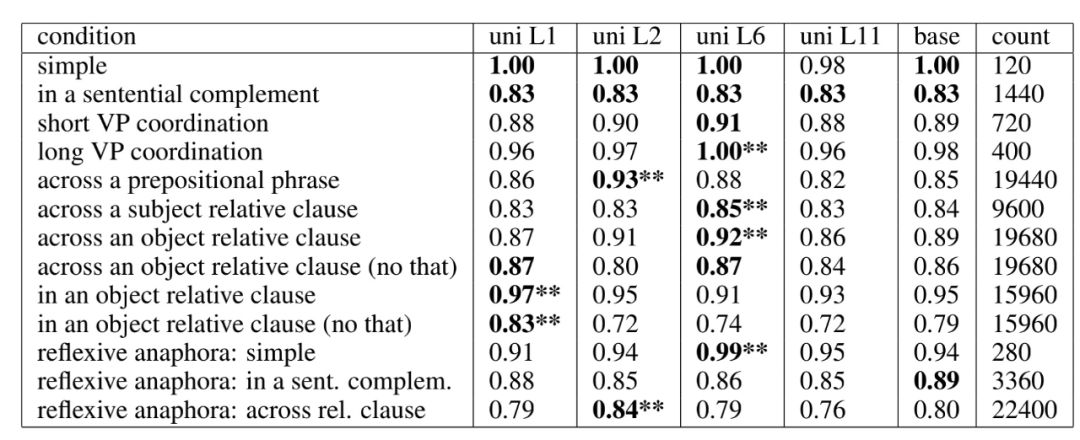
Using MEG data to demonstrate that ELMo (non-contextual) word embeddings contain information about word length and part of speech;
-
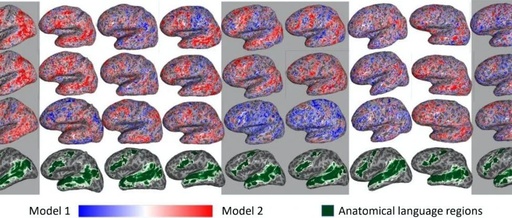
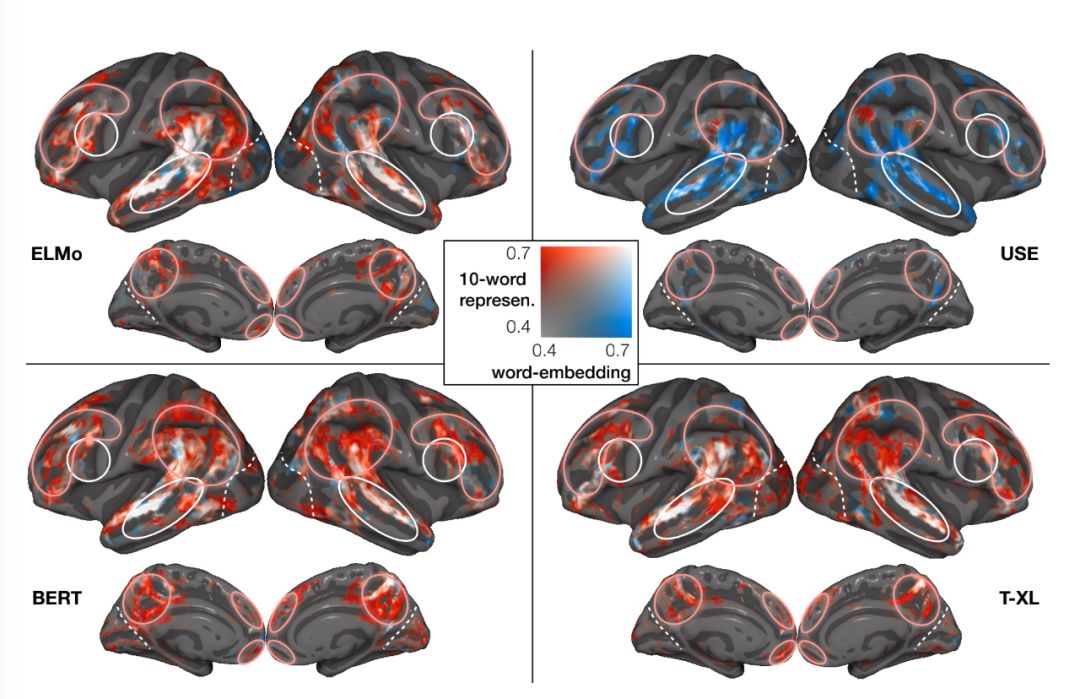
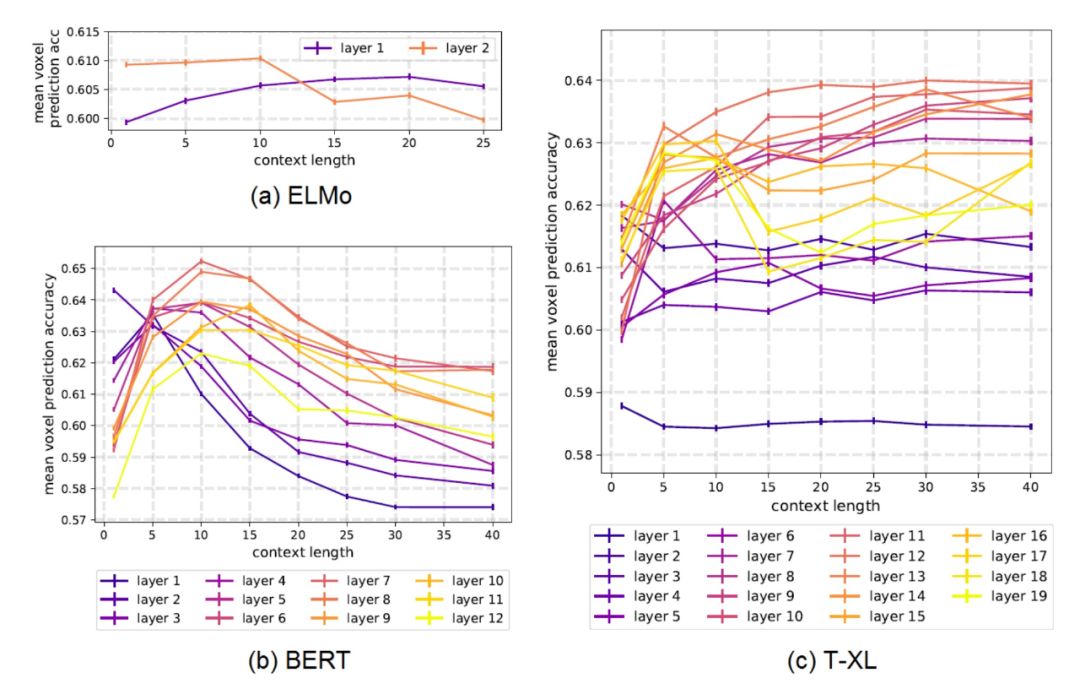
Using fMRI data to demonstrate that the representations obtained from different models (ELMo, USE, BERT, T-XL) contain information related to language processing encoded at different contextual lengths;
-
USE’s long contextual representations differ from those of other models, as its representation does not include any short-context textual information;
-
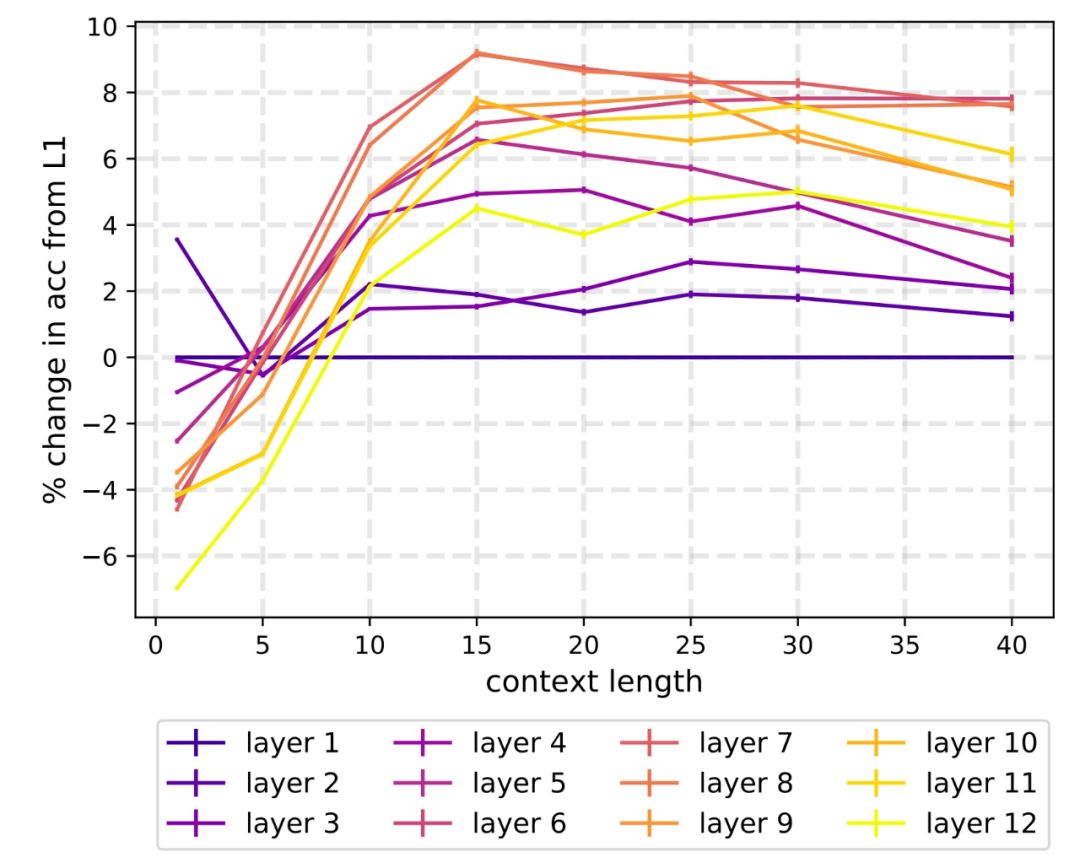
Transformer-based models (BERT and T-XL) capture context information most relevant to the brain in their intermediate layers;
-
T-XL combines recursive and transformer properties, unlike pure recursive models (e.g., ELMo) or transformers (e.g., BERT), maintaining performance even in long contextual situations.
-
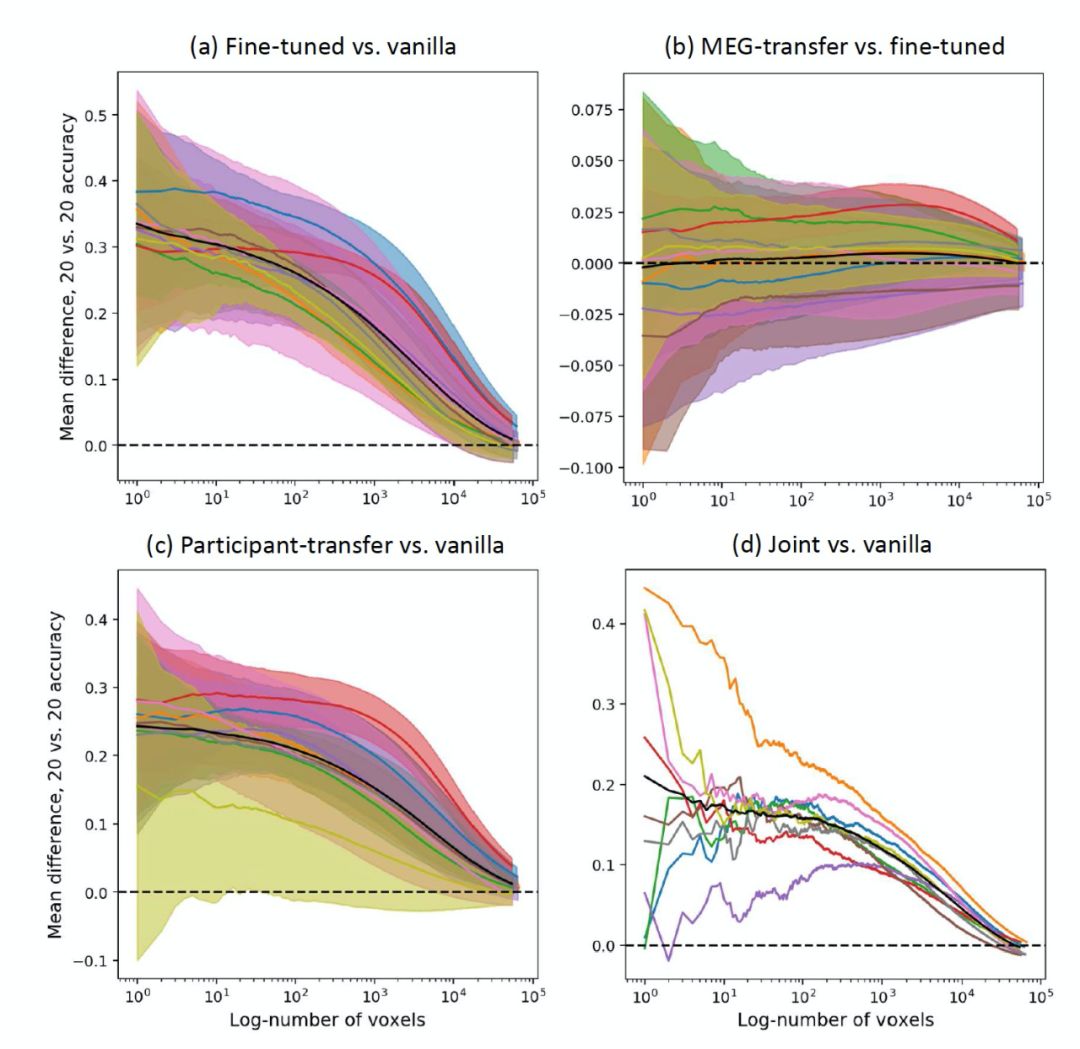
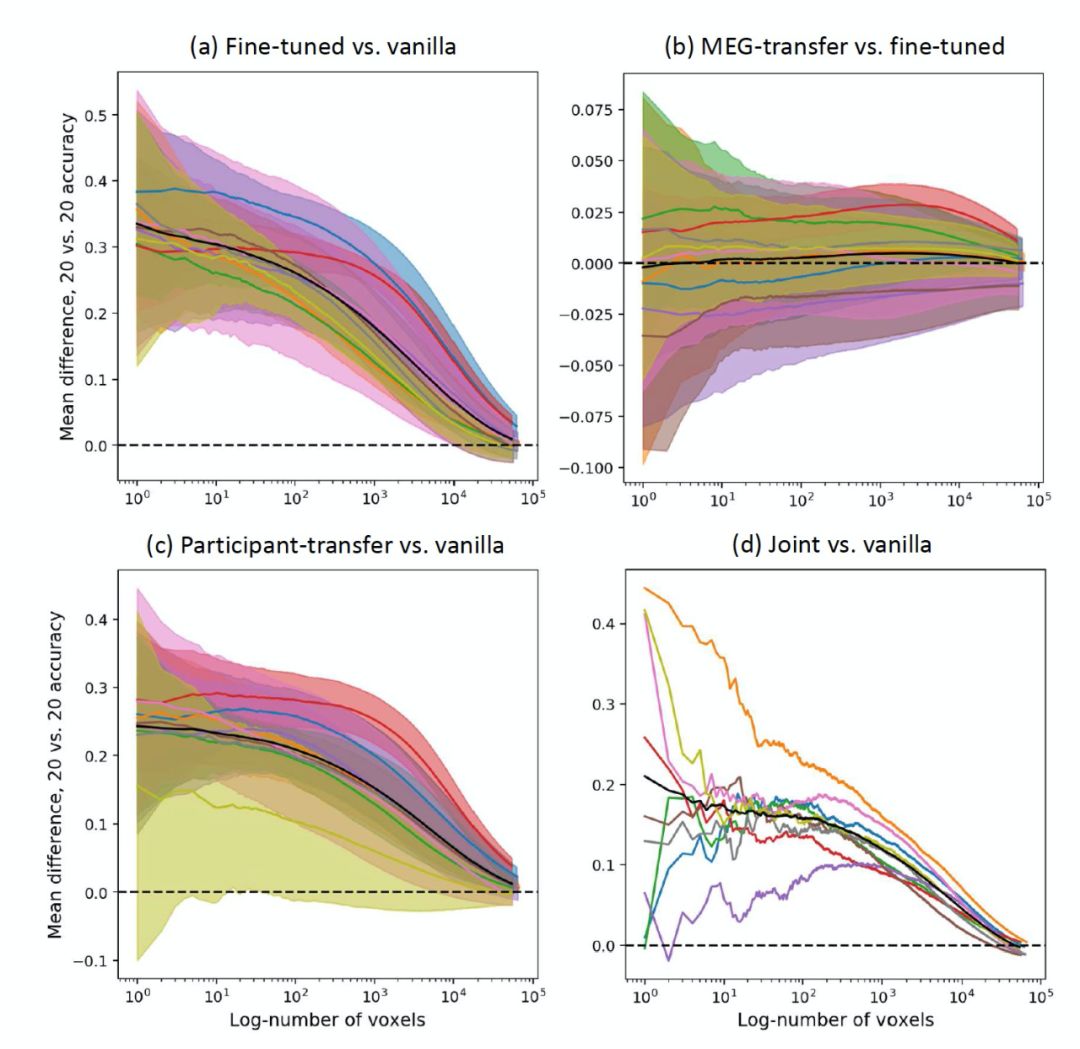
[Vanilla Model] The baseline BERT model, adding a linear layer to the pre-trained BERT model for each subject, training this linear layer to map the [CLS] embedding to the subject’s fMRI data. During training, the parameters of the pre-trained model are frozen to ensure that the embeddings do not change. Depending on the different comparative models in various experiments, the Vanilla model can train for 10, 20, or 30 phases.
-
[Participant-transfer Model] This model is used to study whether the relationship between text and brain activity learned through fine-tuning the BERT model is universally present across subjects. First, the model is fine-tuned based on the subject with the most predictable brain activity. In this fine-tuning process, only the linear layer is trained for 2 phases, followed by training the entire model for 18 phases, after which all parameters of the model are fixed. For other subjects, a linear layer is trained for the first subject under their current experimental conditions. These linear models were only trained for 10 phases, allowing for comparisons with the results of the Vanilla model trained for 10 phases.
-
[Fine-tuned Model] This model verifies whether a fine-tuned model can predict data for each subject. Based on the linear mapping of the Vanilla model, the model for each subject undergoes fine-tuning. Only the linear layers of these models are trained for 10 phases, followed by training the entire model for 20 phases.
-
[MEG-transfer Model] This model is used to investigate whether the relationship between text and brain activity can be learned through a model that accurately transfers MEG data to fMRI data. First, BERT is fine-tuned to predict data from all 8 MEG subjects (jointly). In the MEG training, only the linear output layer is trained for 10 phases, followed by 20 phases of full model training. Then, the MEG fine-tuned model is applied to predict data from each fMRI subject. This training also uses 10 phases, only training the linear output layer, followed by 20 phases of complete fine-tuning.
-
[Fully Joint Model] This model trains to predict data from all MEG subjects and fMRI subjects simultaneously. Only the linear output layer is trained for 10 phases, followed by training the complete model for 50 phases.
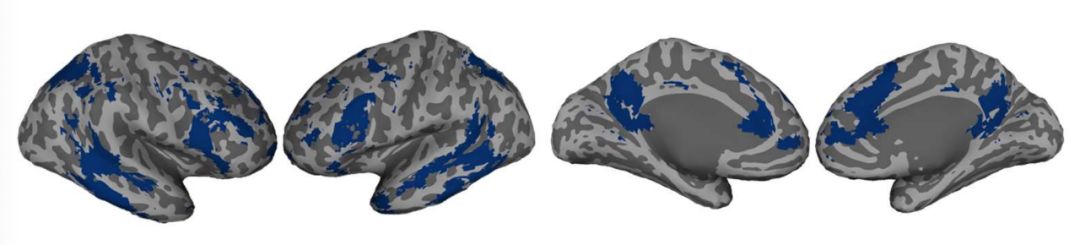
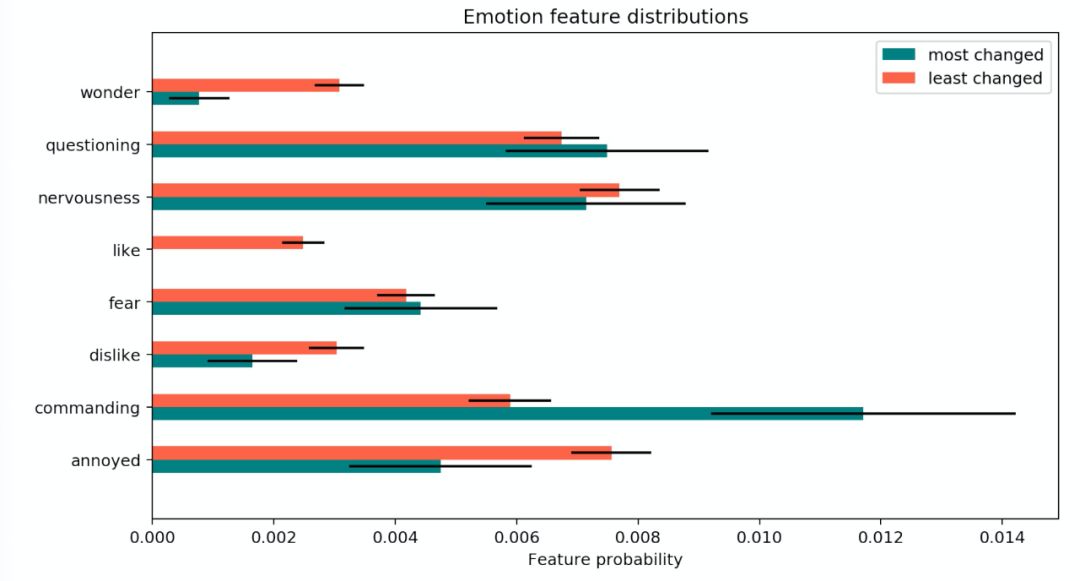
-
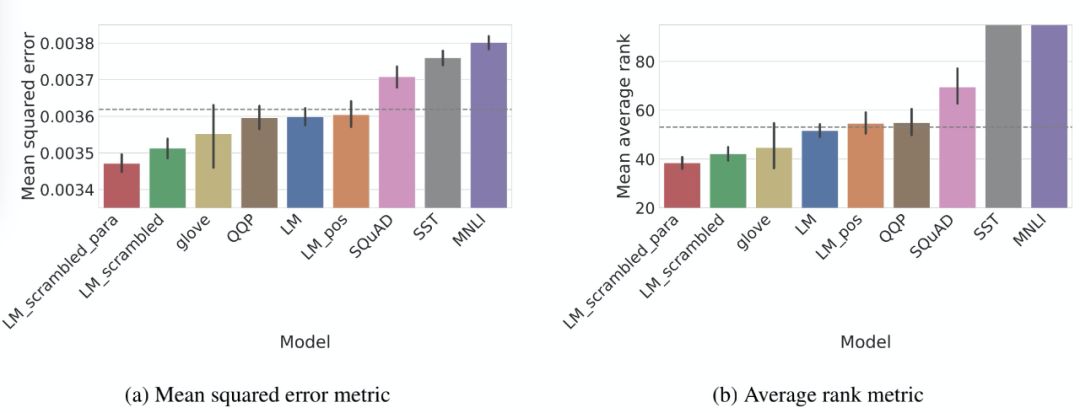
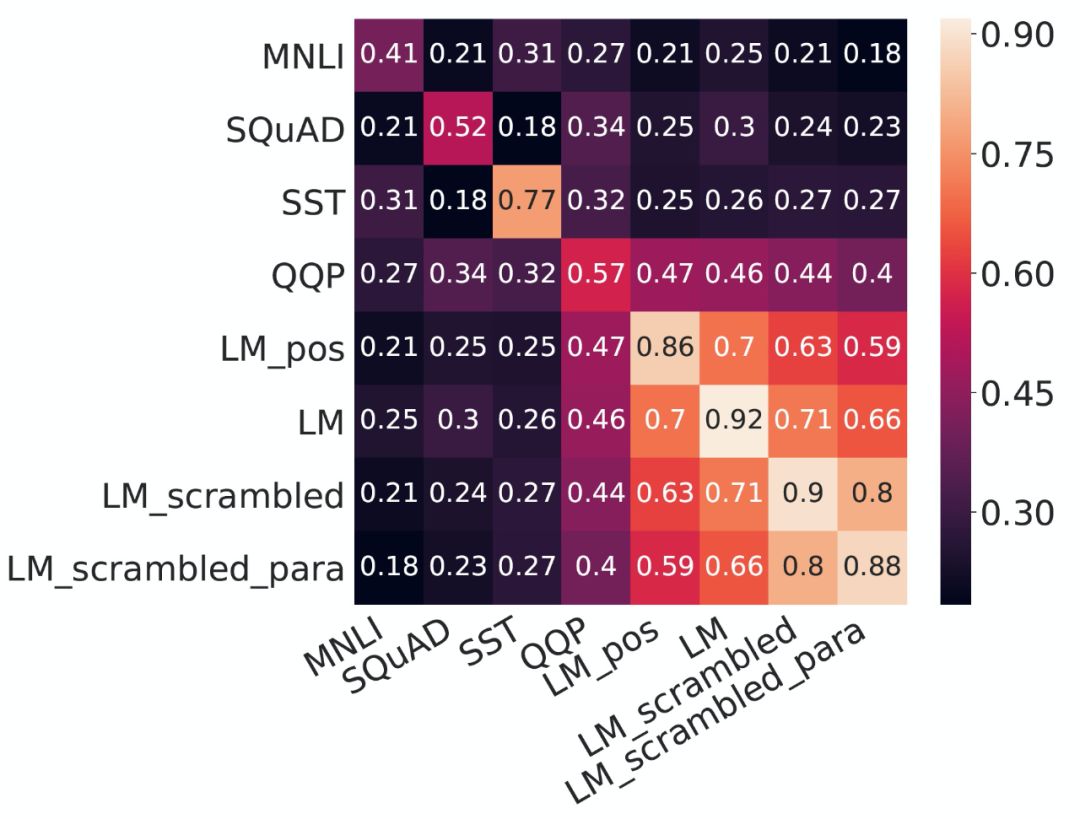
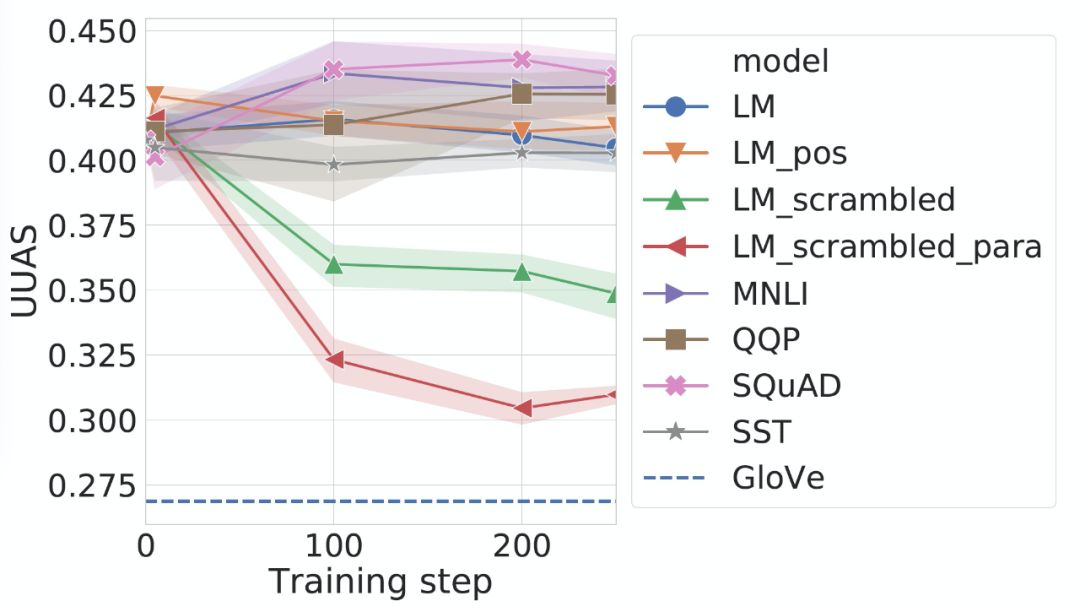
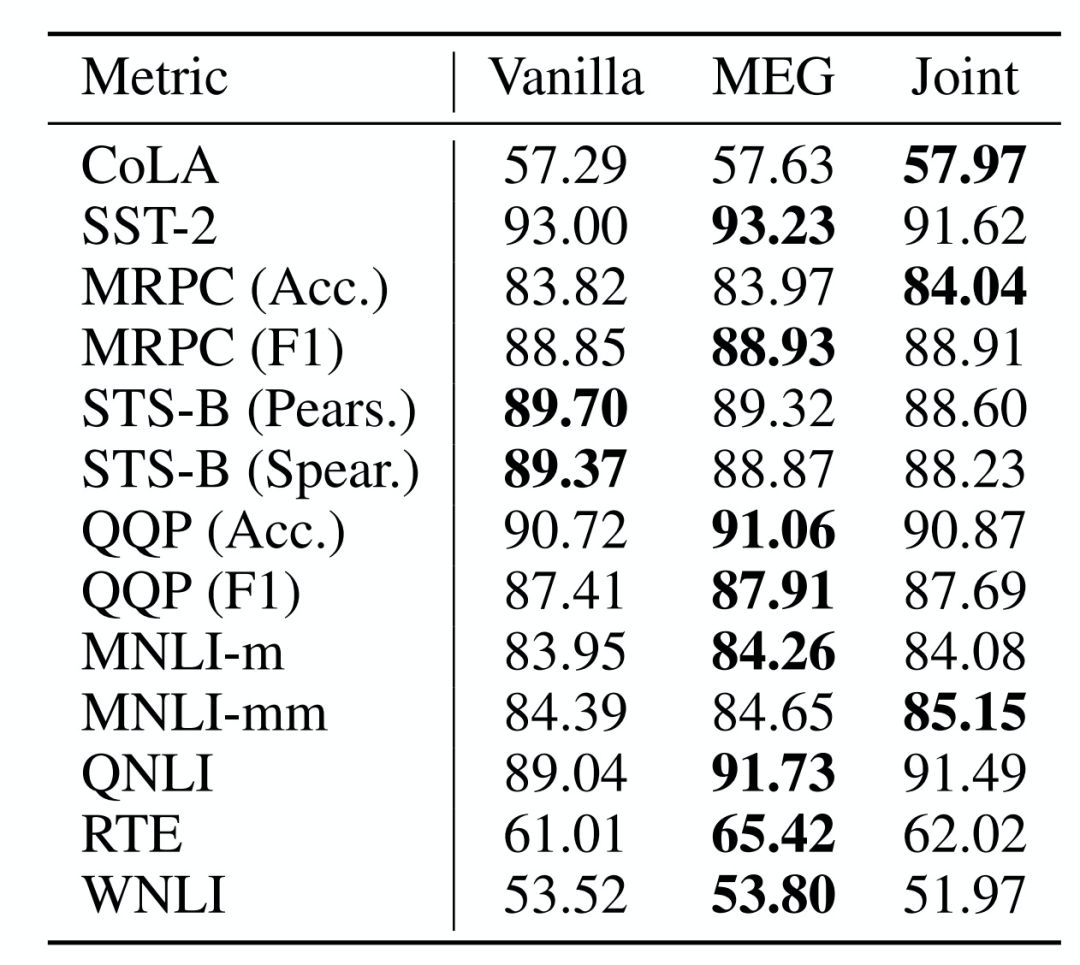
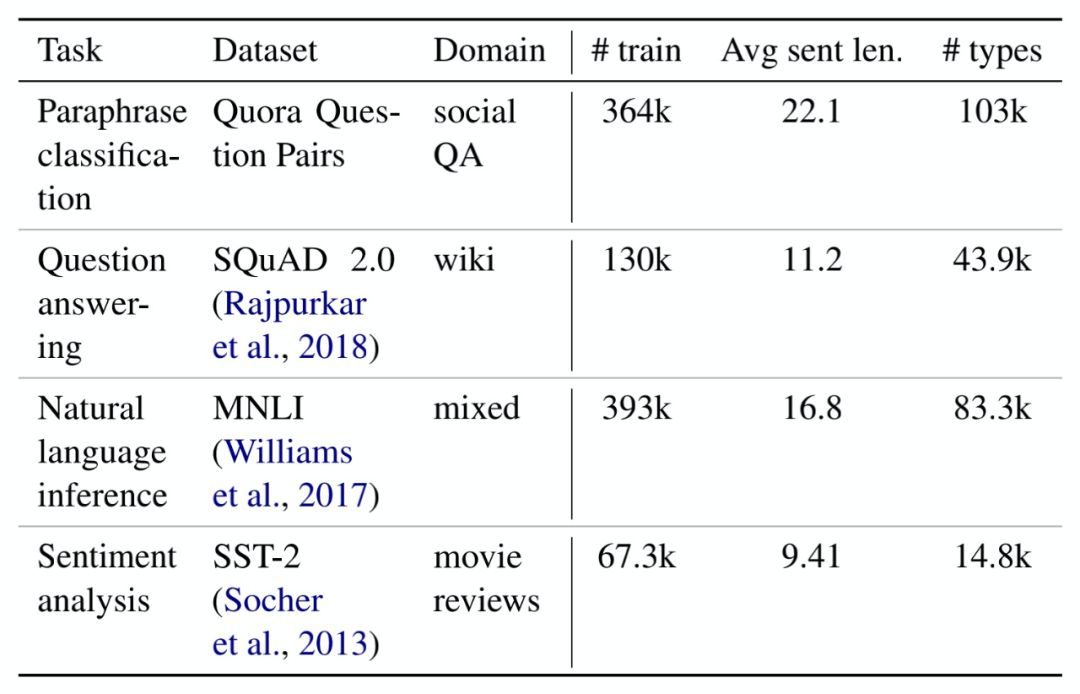
Custom fine-tuning tasks: Each task is a modified version of the standard cloze language modeling task, highlighting a specific aspect of language representation through these modifications.
-
Disordered language modeling: Two language modeling tasks are designed to target fine-grained grammatical representations of the input by scrambling words from the samples used for language modeling. The first task, LM-scrambled, scrambles words in sentences; the second task, LM-scrambled-para, scrambles words in paragraphs. Through this input scrambling, the cloze task can effectively be transformed into a language processing task involving a set of words.
-
Part-of-speech language modeling: LM-pos targets the fine-grained semantic representation of input by requiring a model to predict only the part of speech of a masked word instead of the word itself.
-
Language modeling control: As a control, we continue to use text from the Books Corpus to retrain the original BERT modeling objectives.