Selected from arXiv
Authors: Adrian de Wynter, Daniel J. Perry
Translated by Machine Heart
Machine Heart Editorial Team
Extracting BERT subarchitectures is a highly worthwhile topic, but existing research has shortcomings in subarchitecture accuracy and selection. Recently, researchers from the Amazon Alexa team refined the process of extracting BERT subarchitectures and extracted an optimal subarchitecture called Bort, which is only 16% the size of BERT-large, yet improves CPU inference speed by eight times.

In the field of natural language processing, BERT represents a milestone advancement. With just a single-layer linear classifier and a simple fine-tuning strategy, it can achieve excellent performance across multiple tasks. However, BERT’s application also faces many issues, such as its large scale, slow inference speed, and complex pre-training process. Researchers have made numerous attempts to extract a simpler subarchitecture, hoping it can maintain the excellent performance of the original BERT while simplifying the pre-training process and shortening inference time. These studies have achieved varying degrees of success. However, the subarchitectures they extracted still show lower accuracy than the original architecture, and the selection of architectural parameter sets often appears arbitrary.
Although this problem is computationally difficult to solve, a recent study by de Wynter suggests that: there exists an approximation algorithm—more specifically, a Fully Polynomial-Time Approximation Scheme (FPTAS)—that can effectively extract such sets with optimal guarantees under certain conditions.
In this paper, researchers from the Amazon Alexa team refined the problem of extracting the optimal BERT subarchitecture parameter set into three metrics: inference latency, parameter size, and error rate. The study demonstrated that BERT possesses the strong AB^nC property, which can meet these conditions, allowing the above algorithm to behave like an FPTAS. Then, the researchers extracted an optimal subarchitecture from a high-performance variant of BERT, called Bort, which is 16% the size of BERT-large and improves CPU inference speed to eight times the original.

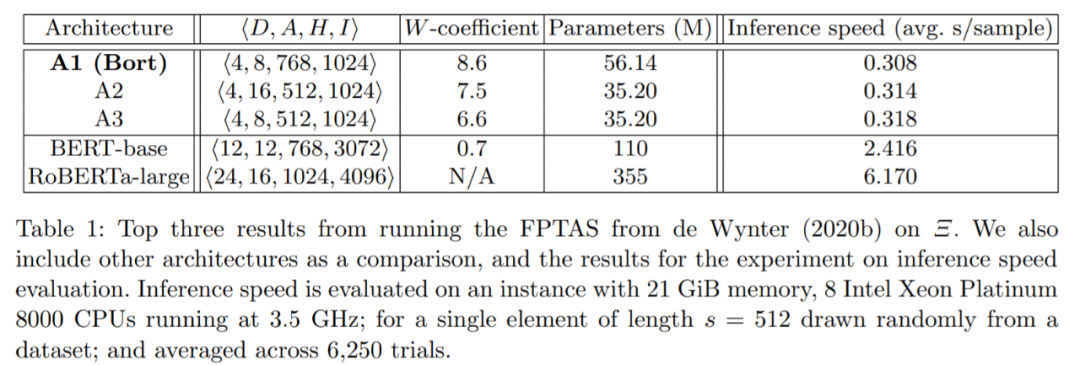
Although FPTAS can ensure finding the optimal performing architecture, it returns the optimal parameter set for architecture based on the three metrics above, without outputting a trained-to-convergence architecture. Therefore, the researchers pre-trained Bort and found a significant improvement in pre-training speed compared to the original training: under the same GPU and similar dataset size, Bort trained for 288 hours, BERT-large trained for 1153 hours, and RoBERTa-large trained for 24,576 hours.
The researchers alsoevaluated Bort on the GLUE, SuperGLUE, and RACE public NLU benchmarks. The results showed that compared to BERT-large, Bort achieved significant improvements across all these benchmarks, with increases ranging from 0.3% to 31%.
The researchers have open-sourced the training model and code on GitHub: https://github.com/alexa/bort/
Bort: The “Optimal” Subarchitecture of BERT
Bert is a transformer-based bidirectional fully connected architecture, which includes a vocabulary-dependent embedding layer (BERT’s vocabulary V = 28,996 tokens), D encoder layers containing Transformers, and an output layer. When BERT was first introduced, there were two variants:
-
BERT-large (D = 24 encoder layers, A = 16 attention heads, H = 1,024 hidden layer size, I = 4,096 intermediate layer size);
-
BERT-base (D = 12, A = 12, H = 768, I = 3072).
Formally, let Ξ represent the finite set of valid combinations of the quadruple <D, A, H, I> (i.e., architectural parameters). In agreement with de Wynter (2020b), this study describes the family of BERT architectures as the codomain of some function, as shown in Formula 1:

This study aims to find an architectural parameter set ξ = <D, A, H, I> that optimizes the three metrics: inference speed i(b(X; ·)), parameter quantity p(b(·; W), and error rate e(b(X; W^∗ ), Y ).
de Wynter (2020b) shows that this is an NP-Hard problem for any architecture. The FPTAS in de Wynter (2020b) is an approximation algorithm that relies on optimizing the proxy functions for i(·), p(·), and e(·, ·), represented as iˆ(·), pˆ(·), and eˆ(·, ·) respectively. During execution, they are represented as functions of Ξ, and scalarized by selecting an architecture T∈B (T is known as the maximum point) with the most parameters and the longest inference time, along with W – coefficient metrics, as shown in Formula 2:
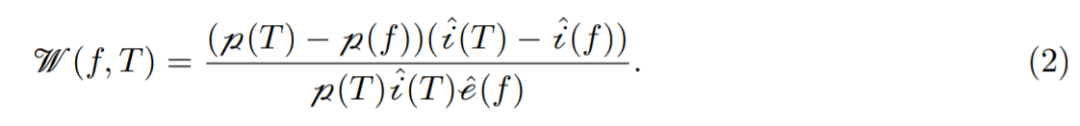
Finding proxies for i(·) and p(·) is relatively simple; in fact,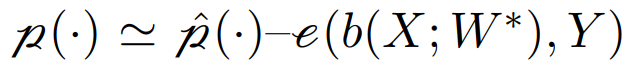 the proxy must be obtained through the loss function. Similarly, ensuring runtime and approximability depends on two additional input parameters: the selected maximum training step number n > 0 and the pre-training interval size 1 ≤ ϵ ≤ |Ξ|. The choice of ϵ directly affects the quality of the solution obtained by this approximation algorithm.
Pre-training with Knowledge Distillation
Although FPTAS can ensure we obtain a parameter set that describes the optimal subarchitecture, how to efficiently pre-train the parameterized model remains an unresolved issue.
According to previous research (see Chapter 2 of the paper), it can be concluded that using knowledge distillation (KD) to pre-train the aforementioned language model can achieve good performance on the aforementioned evaluation metrics. Given that the proxy error function eˆ(·, ·) is cross-entropy about the maximum point, it is natural to extend the above evaluation through KD.
The study also compared self-supervised pre-training of the Bort architecture with KD-based pre-training, finding that a simple cross-entropy between the last layer of the student model and the teacher model is sufficient to find an excellent model that can achieve higher masked language model (MLM) accuracy and faster pre-training speed compared to another method.
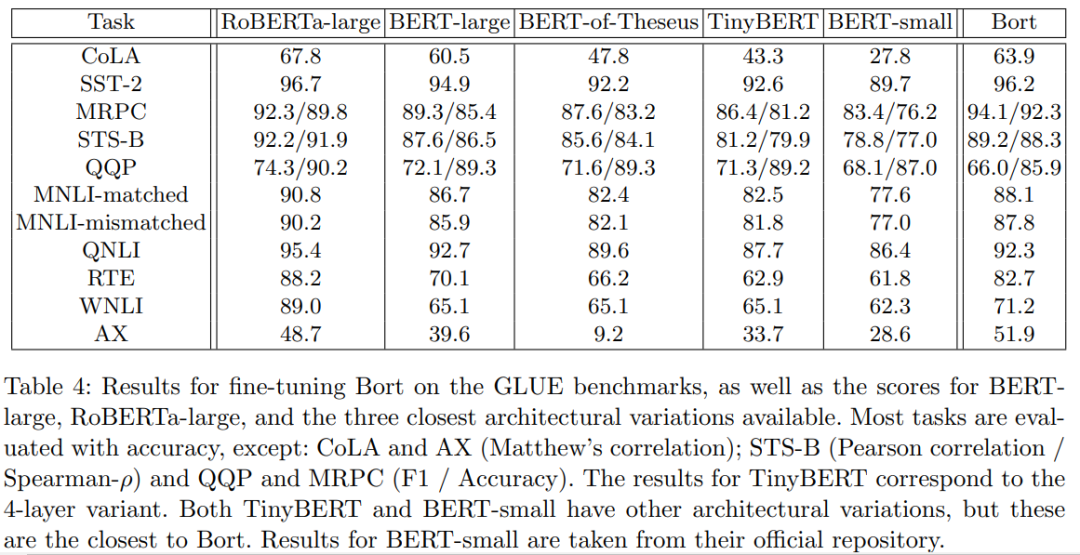
To verify whether Bort retains the strong generalization performance of BERT and RoBERTa after the optimal subarchitecture extraction process, the researchers fine-tuned Bort on the GLUE, SuperGLUE benchmarks, and the RACE dataset. The results indicate thatBort significantly outperforms other similar BERT compression models across multiple tasks.
GLUE (Generalized Language Evaluation benchmark) contains a set of common natural language tasks, primarily focusing on natural language inference (NLI), consisting of ten datasets.
The researchers fine-tuned Bort by adding a single-layer linear classifier across all tasks, except for CoLA. In CoLA, the researchers found that adding an additional linear layer between Bort and the classifier improved convergence speed. The researchers used Agora to fine-tune all tasks.
The results are shown in Table 4.15. Except for QQP and QNLI, Bort performed excellently on almost all tasks, significantly outperforming other BERT-based models.Bort’s performance improved by 0.3%-31% compared to BERT-large. The researchers attribute this improvement to the fine-tuning of Agora, as it allows the model to better learn the target distribution of each task.
the proxy must be obtained through the loss function. Similarly, ensuring runtime and approximability depends on two additional input parameters: the selected maximum training step number n > 0 and the pre-training interval size 1 ≤ ϵ ≤ |Ξ|. The choice of ϵ directly affects the quality of the solution obtained by this approximation algorithm.
Pre-training with Knowledge Distillation
Although FPTAS can ensure we obtain a parameter set that describes the optimal subarchitecture, how to efficiently pre-train the parameterized model remains an unresolved issue.
According to previous research (see Chapter 2 of the paper), it can be concluded that using knowledge distillation (KD) to pre-train the aforementioned language model can achieve good performance on the aforementioned evaluation metrics. Given that the proxy error function eˆ(·, ·) is cross-entropy about the maximum point, it is natural to extend the above evaluation through KD.
The study also compared self-supervised pre-training of the Bort architecture with KD-based pre-training, finding that a simple cross-entropy between the last layer of the student model and the teacher model is sufficient to find an excellent model that can achieve higher masked language model (MLM) accuracy and faster pre-training speed compared to another method.
To verify whether Bort retains the strong generalization performance of BERT and RoBERTa after the optimal subarchitecture extraction process, the researchers fine-tuned Bort on the GLUE, SuperGLUE benchmarks, and the RACE dataset. The results indicate thatBort significantly outperforms other similar BERT compression models across multiple tasks.
GLUE (Generalized Language Evaluation benchmark) contains a set of common natural language tasks, primarily focusing on natural language inference (NLI), consisting of ten datasets.
The researchers fine-tuned Bort by adding a single-layer linear classifier across all tasks, except for CoLA. In CoLA, the researchers found that adding an additional linear layer between Bort and the classifier improved convergence speed. The researchers used Agora to fine-tune all tasks.
The results are shown in Table 4.15. Except for QQP and QNLI, Bort performed excellently on almost all tasks, significantly outperforming other BERT-based models.Bort’s performance improved by 0.3%-31% compared to BERT-large. The researchers attribute this improvement to the fine-tuning of Agora, as it allows the model to better learn the target distribution of each task.
SuperGLUE contains a set of common natural language tasks, consisting of ten datasets.
The researchers fine-tuned Bort by adding a single-layer linear classifier and running Agora to convergence across all tasks. The results are shown in Table 5:Bort achieved results that exceed or match BERT-large in all tasks except ReCoRD.
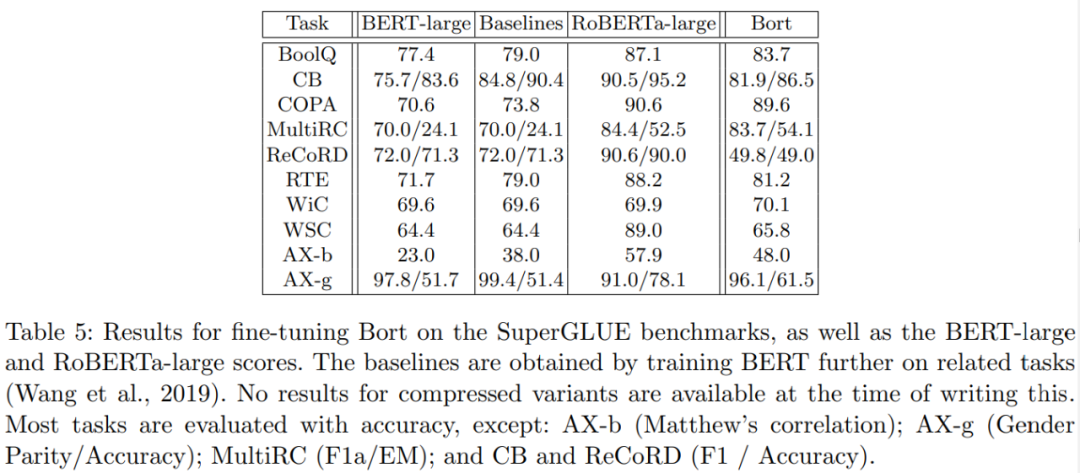
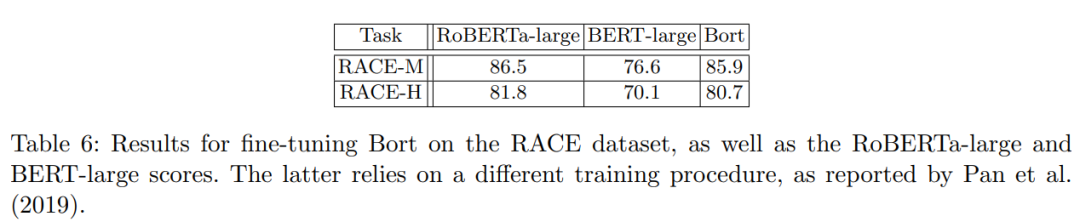
The RACE dataset is a multiple-choice question dataset for text reading, annotated by professionals, divided into two datasets: RACE-H (extracted from high school exam questions) and RACE-M (extracted from middle school exam questions).
As in previous experiments, the researchers fine-tuned Bort by adding a single-layer linear classifier and running Agora for convergence.
The results are shown in Table 6. Overall,Bort achieved good results, outperforming BERT-large by 9-10% on both tasks.
Amazon SageMaker Practical Tutorial (Video Review)
Amazon SageMaker is a fully managed service that helps machine learning developers and data scientists quickly build, train, and deploy models. Amazon SageMaker completely eliminates the heavy lifting of various steps in the machine learning process, making it easier to develop high-quality models.
From October 15 to October 22, Machine Heart collaborated with AWS to hold three online sessions,the full review is as follows:

First Lecture: Detailed Explanation of Amazon SageMaker Studio
Huang Debin (AWS Senior Solutions Architect) mainlyintroduced related components of Amazon SageMaker, such as studio, autopilot, etc., and demonstrated online how these core components improve AI model development efficiency.
Video review link:https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715443e4b005221d8ea8e3
Second Lecture: Building a Sentiment Analysis “Robot” with Amazon SageMaker
Liu Junyi (AWS Application Scientist) mainlyintroduced the background of sentiment analysis tasks, training a BERT-based sentiment analysis model using Amazon SageMaker, and deploying the model based on containers using AWS digital asset revitalization solutions.
Video review link:https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715d38e4b0e95a89c1713f
Third Lecture: DGL Graph Neural Networks and Their Practice on Amazon SageMaker
Zhang Jian (AWS Shanghai AI Research Institute Senior Data Scientist) mainlyintroduced graph neural networks, the role of DGL in graph neural networks, the applications of graph neural networks and DGL in fraud detection, and using Amazon SageMaker to deploy and manage graph neural network models for real-time inference.
Video review link:https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715d6fe4b005221d8eac5d
© THE END
Please contact this public account for authorization
Submission or seeking coverage: [email protected]


