Selected from arXiv
Author:Mohammad Shoeybi et al.
Translated by Machine Heart
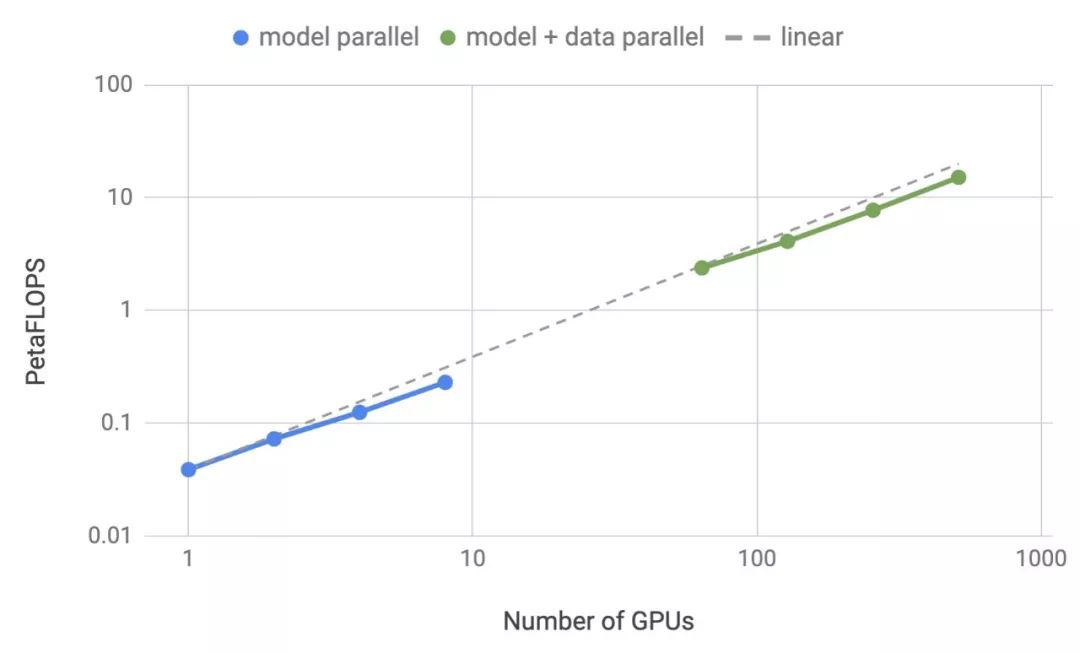
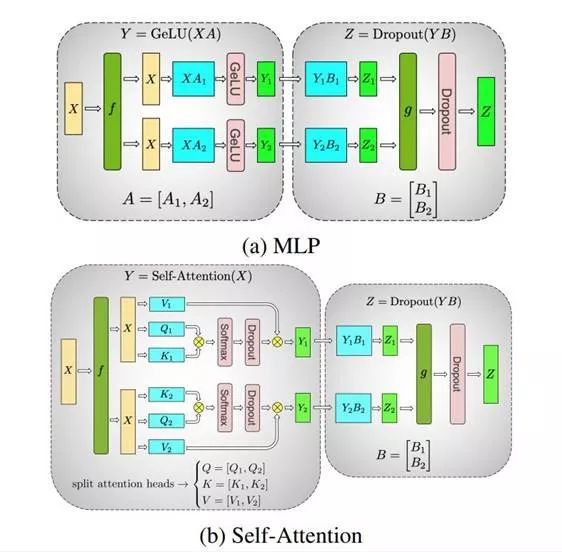
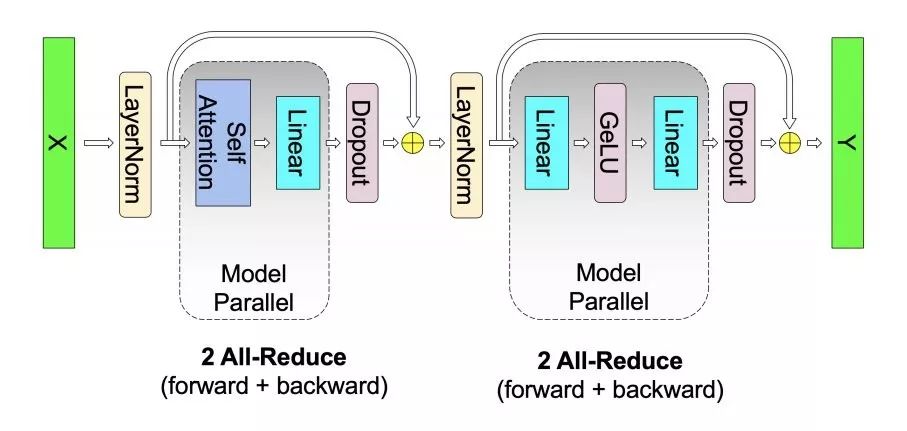
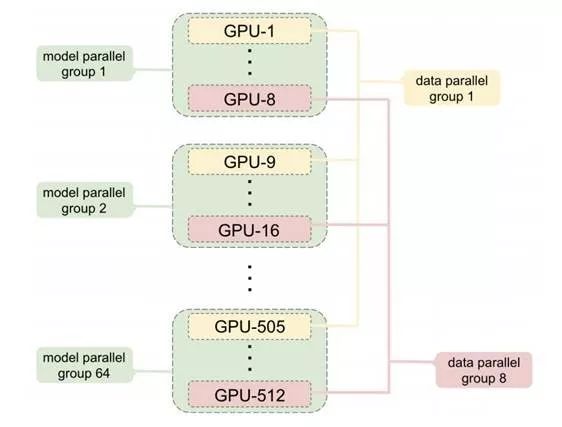
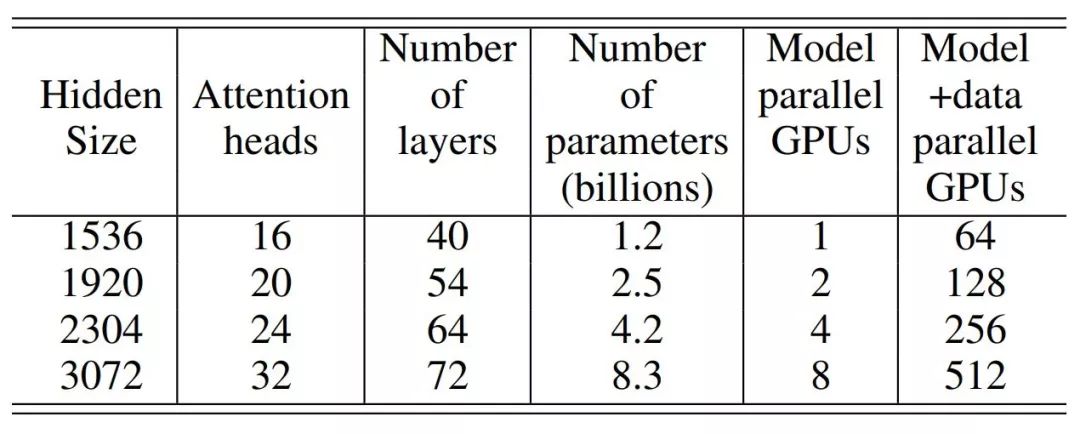
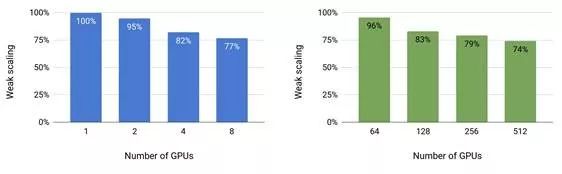
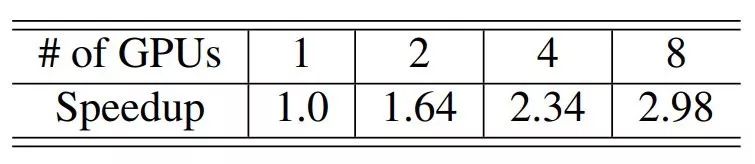
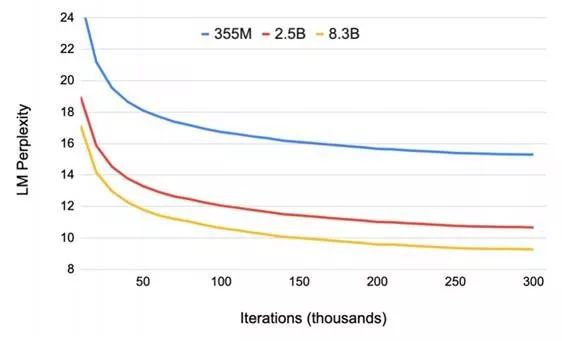
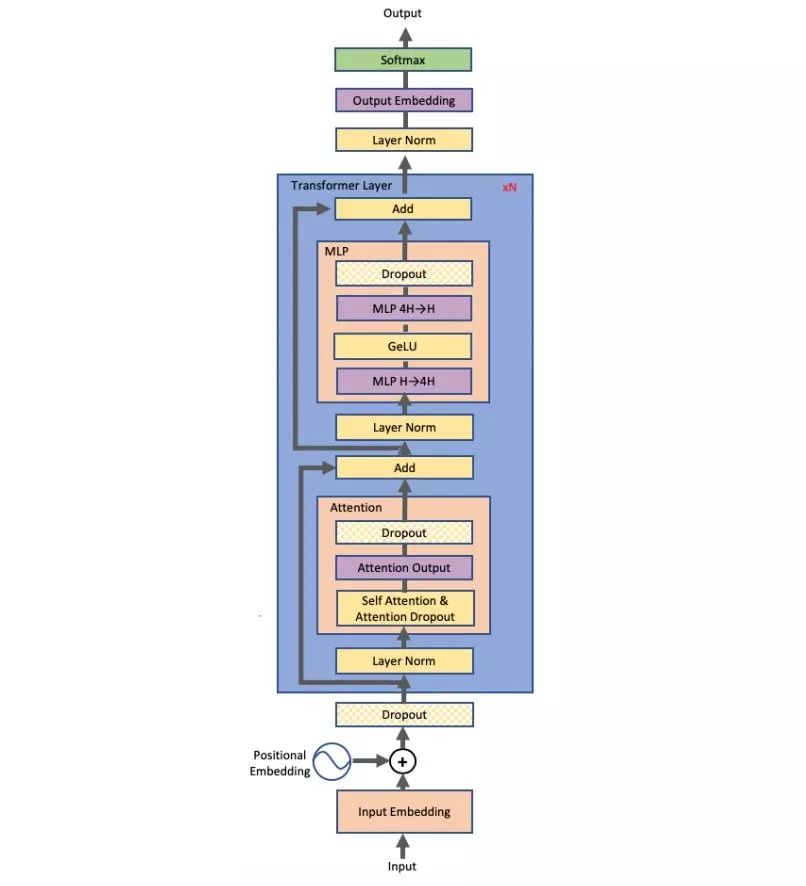
Previously, Machine Heart introduced a study by NVIDIA that broke three records in the NLP field: reducing BERT’s training time to 53 minutes; reducing BERT’s inference time to 2.2 milliseconds; and increasing the parameter count of GPT-2 to 8 billion (previously, GPT-2 had a maximum of 1.5 billion parameters). Many attributed this achievement to NVIDIA’s superior hardware conditions, as GPUs are abundant. However, NVIDIA’s recent paper revealed the model parallelism method used in this research: intra-layer model parallelism. This method does not require new compilers or library changes; it can be fully implemented by embedding a few communication operations in PyTorch.
-
Paper link:https://arxiv.org/abs/1909.08053v1
-
Code link: https://github.com/NVIDIA/Megatron-LM