

Reprinted from | PaperWeekly
©PaperWeekly Original · Author | Li Luoqiu
School | Master’s Student at Zhejiang University
Research Direction | Natural Language Processing, Knowledge Graphs
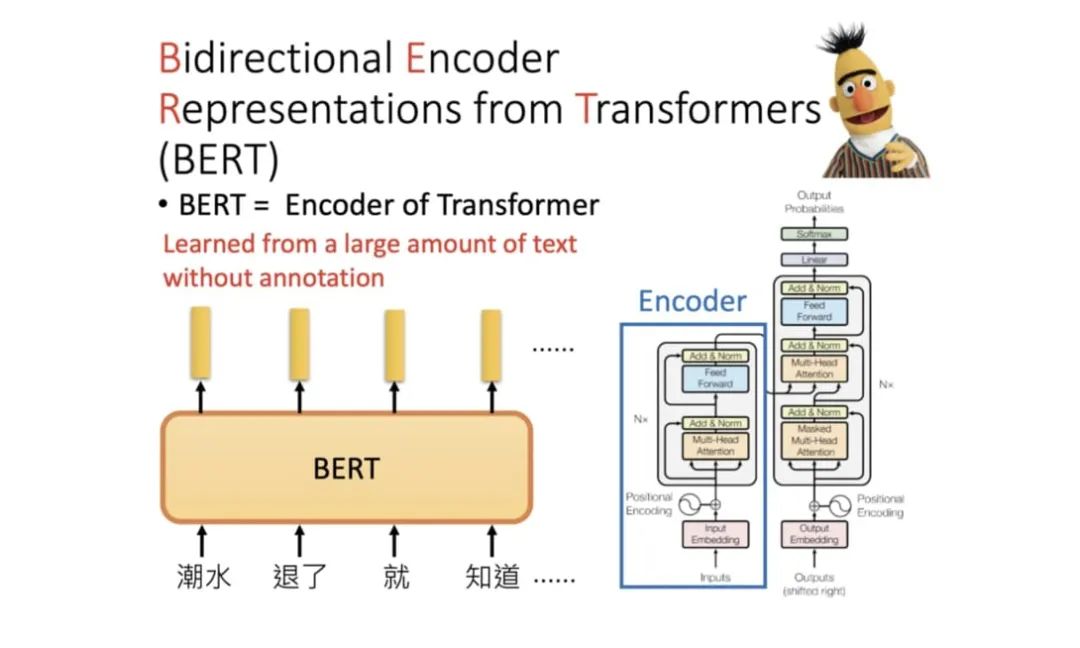
This article analyzes the code related to BERT in the PyTorch version of the Transformers project version 4.4.2 (released on March 19, 2021) from the perspectives of code structure, specific implementation and principles, as well as usage, including the following content:
1. BERT Tokenization Model (BertTokenizer)
2. BERT Model (BertModel)
2.1 BertEmbeddings

<span>/models/bert/tokenization_bert.py</span> and <span>/models/bert/tokenization_bert_fast.py</span>.
These two codes correspond to the basic <span>BertTokenizer</span> and the <span>BertTokenizerFast</span> that does not perform token to index mapping, focusing mainly on the first one.
class BertTokenizer(PreTrainedTokenizer):
"""
Construct a BERT tokenizer. Based on WordPiece.
This tokenizer inherits from :class:`~transformers.PreTrainedTokenizer` which contains most of the main methods.
Users should refer to this superclass for more information regarding those methods.
...
"""<span>BertTokenizer</span> is a tokenizer based on <span>BasicTokenizer</span> and <span>WordPieceTokenizer</span>:-
<span>BasicTokenizer</span>is responsible for the first step—splitting sentences by punctuation, spaces, etc., handling whether to lowercase, and cleaning illegal characters. -
For Chinese characters, it splits by characters through preprocessing (adding spaces);
-
It can also specify certain words not to be split through
<span>never_split</span>; -
This step is optional (default executed). -
<span>WordPieceTokenizer</span>further decomposes words into subwords on top of words. -
Subwords are between characters and words, preserving some meaning of words while addressing the vocabulary explosion and OOV (Out-Of-Vocabulary) issues caused by plural forms and tenses in English, by segmenting roots and tense affixes, thus reducing vocabulary and lowering training difficulty;
-
For example, the word tokenizer can be broken down into “token” and “##izer”, where the “##” indicates that the latter word follows the former.
<span>BertTokenizer</span> has the following common methods:
-
<span>from_pretrained</span>: Initializes a tokenizer from a directory containing a vocabulary file (vocab.txt); -
<span>tokenize</span>: Decomposes text (words or sentences) into a list of subwords; -
<span>convert_tokens_to_ids</span>: Converts a list of subwords into a list of corresponding indices; -
<span>convert_ids_to_tokens</span>: The opposite of the previous one; -
<span>convert_tokens_to_string</span>: Joins the subword list back into a word or sentence by “##”; -
<span>encode</span>: For a single sentence input, decomposes words and adds special tokens to form the structure “[CLS], x, [SEP]” and converts it to a list of indices corresponding to the vocabulary; for two sentence inputs (multiple sentences only take the first two), decomposes words and adds special tokens to form the structure “[CLS], x1, [SEP], x2, [SEP]” and converts it to a list of indices; -
<span>decode</span>: Can convert the output of the encode method back into a complete sentence.
Additionally, the class itself has methods:
>>> from transformers import BertTokenizer
>>> bt = BertTokenizer.from_pretrained('./bert-base-uncased/')
>>> bt('I like natural language progressing!')
{'input_ids': [101, 1045, 2066, 3019, 2653, 27673, 999, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}

Model (BertModel)
<span>/models/bert/modeling_bert.py</span>, which contains over a thousand lines, including the basic structure of the BERT model and fine-tuning models based on it.class BertModel(BertPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in `Attention is
all you need <https://arxiv.org/abs/1706.03762>`__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as a decoder the model needs to be initialized with the :obj:`is_decoder` argument of the configuration
set to :obj:`True`. To be used in a Seq2Seq model, the model needs to initialized with both :obj:`is_decoder`
argument and :obj:`add_cross_attention` set to :obj:`True`; an :obj:`encoder_hidden_states` is then expected as an
input to the forward pass.
""" -
<span>embeddings</span>, which is the entity of the<span>BertEmbeddings</span>class, corresponding to word embeddings; -
<span>encoder</span>, which is the entity of the<span>BertEncoder</span>class; -
<span>pooler</span>, which is the entity of the<span>BertPooler</span>class, this part is optional.
Note: BertModel can also be configured as a Decoder, but this part is not discussed here.
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
): ...-
<span>input_ids</span>: The list of indices corresponding to the subwords after tokenization; -
<span>attention_mask</span>: During the self-attention process, this mask is used to distinguish between the subwords in the sentence and padding, filling the padding part with 0; -
<span>token_type_ids</span>: Marks the current sentence of the subword (first sentence/second sentence/padding); -
<span>position_ids</span>: Marks the index of the current word in the sentence; -
<span>head_mask</span>: Used to invalidate certain layers’ attention calculations; -
<span>inputs_embeds</span>: If provided, then it does not need<span>input_ids</span>, directly enters the Encoder computation as Embedding; -
<span>encoder_hidden_states</span>: This part is effective when BertModel is configured as a decoder, performing cross-attention instead of self-attention; -
<span>encoder_attention_mask</span>: Similar to the above, used to mark the padding of the encoder input during cross-attention; -
<span>past_key_values</span>: This parameter seems to pass the pre-computed K-V product to reduce the overhead of cross-attention (as this part is originally repeated computation); -
<span>use_cache</span>: Saves the previous parameters and returns them to speed up decoding; -
<span>output_attentions</span>: Whether to return the attention output of each intermediate layer; -
<span>output_hidden_states</span>: Whether to return the output of each intermediate layer; -
<span>return_dict</span>: Whether to return the output in key-value pair form (ModelOutput class, also can be treated as a tuple), defaults to true.
Note: Here, the invalidation of head_mask on attention calculations is different from the pruning of attention heads mentioned later, and simply multiplies the results of certain attention calculations by this coefficient.
The return part is as follows:
# BertModel's forward propagation return part
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)<span>encoder_outputs[1:]</span>), making it convenient to use: # BertEncoder's forward propagation return part, i.e., the above encoder_outputs
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)In addition, BertModel also has the following methods, allowing BERT users to perform various operations:
-
<span>get_input_embeddings</span>: Extracts the word_embeddings from the embedding; -
<span>set_input_embeddings</span>: Assigns values to the word_embeddings in the embedding; -
<span>_prune_heads</span>: Provides a function to prune attention heads, with input as<span>{layer_num: list of heads to prune in this layer}</span>dictionary, allowing pruning of certain attention heads in specified layers.
<span>BertAttention</span> part’s <span>prune_heads</span> method.
-
word_embeddings, the embeddings corresponding to the subwords mentioned above. -
token_type_embeddings, used to represent the sentence where the current word is located, assisting in distinguishing between sentences and padding, and differences between sentence pairs. -
position_embeddings, the position embeddings for each word in the sentence, used to distinguish the order of words. Unlike the design in the transformer paper, this part is trained rather than calculated through a sinusoidal function to obtain fixed embeddings. It is generally believed that this implementation is not conducive to scalability (difficult to transfer directly to longer sentences).
The three embeddings are summed without weights, and output after a LayerNorm + dropout layer, with a size of<span>(batch_size, sequence_length, hidden_size)</span>.
It consists of multiple layers of BertLayer, and there is nothing particularly noteworthy here, but one detail is worth noting:
Utilizes gradient checkpointing technology to reduce GPU memory usage during training.
Note: Gradient checkpointing reduces the number of computation graph nodes saved to compress model memory usage, but during gradient computation, it requires recomputing the unsaved values, refer to the paper “Training Deep Nets with Sublinear Memory Cost”, the process is illustrated as follows:
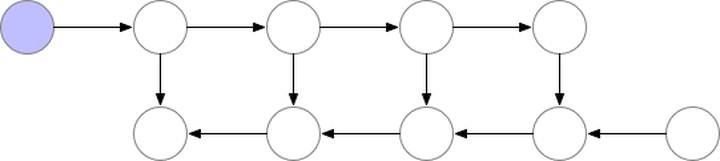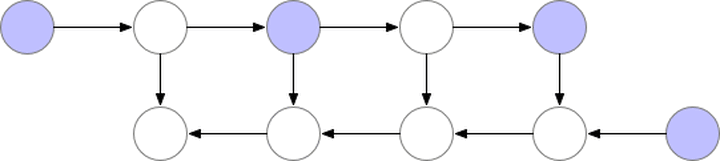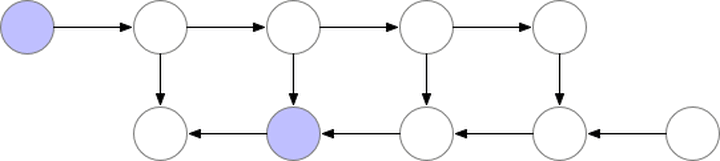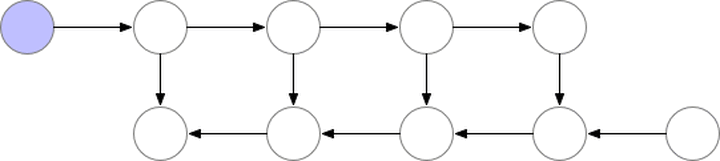
This mechanism’s specific implementation is complex (not fully understood), and will not be elaborated here.
This layer wraps BertAttention and BertIntermediate + BertOutput (the attention part and the FFN part), as well as the cross-attention part that is ignored here (involving BERT as a Decoder).
Theoretically, calling the three sub-modules in order is sufficient, and there is nothing particularly noteworthy here.

# This is part of forward
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
# ...<span>apply_chunking_to_forward</span> and <span>feed_forward_chunk</span>? (Why make it so complex? Isn’t it more straightforward to call it directly?)<span>apply_chunking_to_forward</span>? Let’s take a closer look:def apply_chunking_to_forward(
forward_fn: Callable[..., torch.Tensor], chunk_size: int, chunk_dim: int, *input_tensors
) -> torch.Tensor:
"""
This function chunks the :obj:`input_tensors` into smaller input tensor parts of size :obj:`chunk_size` over the
dimension :obj:`chunk_dim`. It then applies a layer :obj:`forward_fn` to each chunk independently to save memory.
If the :obj:`forward_fn` is independent across the :obj:`chunk_dim` this function will yield the same result as
directly applying :obj:`forward_fn` to :obj:`input_tensors`.
...
"""<span>chunk_size</span> is the size of the chunk, and <span>chunk_dim</span> is the size of the dimension for a single computation, and finally concatenates and returns.However, in the default operation, these two values are not specifically set (default to 0 and 1 in the source code), so it will directly equate to the normal forward process.
2.2.1.1 BertAttention
I thought the attention implementation was here, but it turns out to be another layer down… Here, the self member is the implementation of multi-head attention, while the output member implements a series of operations including fully connected + dropout + residual + LayerNorm after attention.
class BertAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.self = BertSelfAttention(config)
self.output = BertSelfOutput(config)
self.pruned_heads = set()First, let’s return to this layer. Here, the pruning operation mentioned earlier appears, namely the <span>prune_heads</span> method:
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)-
<span>find_pruneable_heads_and_indices</span>is used to locate the heads to be pruned and the indices of the dimensions to be retained; -
<span>prune_linear_layer</span>is responsible for transferring the weight matrices (along with bias) of Wk/Wq/Wv, retaining the dimensions that have not been pruned to a new matrix.
2.2.1.1.1 BertSelfAttention
Warning: This part can be considered the core area of the model and is the only place involving formulas, so a lot of code will be provided.
Initialization part:
class BertSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads)
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
self.is_decoder = config.is_decoder-
In addition to the familiar query, key, value weights and a dropout, there is also a mysterious position_embedding_type, and a decoder flag (of course, I do not intend to introduce the cross-attention part); -
Note that hidden_size and all_head_size are the same at first. The reason for seemingly unnecessary additional setting of this variable is obviously due to the pruning function above, where after pruning several attention heads, all_head_size naturally becomes smaller;
-
hidden_size must be a multiple of num_attention_heads; for example, in bert-base, each attention head contains 12 heads, and hidden_size is 768, so the size of each head is attention_head_size=768/12=64;
-
What is position_embedding_type? Keep reading to find out…
Next is the key point, which is the forward propagation process.
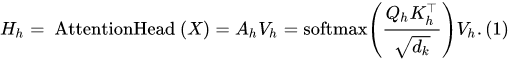
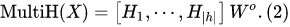
These attention heads, as we all know, are computed in parallel, so the query, key, and value weights above are unique—not all heads share weights, but are “concatenated”.
Note: The reason for multi-head in the original paper is that Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this. Another reliable analysis is: Why does the Transformer need to perform Multi-head Attention?[4]
Let’s look at the forward method:
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
mixed_query_layer = self.query(hidden_states)
# ...Here, the <span>transpose_for_scores</span> is used to reshape hidden_size into the output shape of multiple heads, and transpose the middle two dimensions for matrix multiplication;
<span>(batch_size, num_attention_heads, sequence_length, attention_head_size)</span>;The shape of attention_scores here is:<span>(batch_size, num_attention_heads, sequence_length, sequence_length)</span>, which conforms to the shape of the attention map obtained through independent calculations of multiple heads.
At this point, the K and Q multiplication to obtain the raw attention scores has been implemented, according to the formula, the next step should be scaling by dk and performing softmax. However—
<span>positional_embedding</span>, along with a bunch of Einstein summations: # ...
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
# ...Note: The <span>positional_embedding</span> here introduces position embeddings into the attention map—why is this done? I currently don’t understand…
For different <span>positional_embedding_type</span>, there are three operations:
-
<span>absolute</span>: Default value, this part does not need to be processed; -
<span>relative_key</span>: Processes the key_layer, multiplying it with the<span>positional_embedding</span>and the key matrix; -
<span>relative_key_query</span>: Processes both key and value by multiplying them with the position encoding.
For now, let’s skip this confusing part and return to the normal attention flow:
# ...
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask # Why is this + instead of *?
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
# ...
return outputsattention_scores = attention_scores + attention_mask? Shouldn’t it be multiplied by the mask?Because here, the attention_mask has already been “manipulated”, turning the originally 1 parts into 0, while the originally 0 parts (i.e., padding) into a large negative number, so adding it results in a large negative value:
(Pdb) attention_mask
tensor([[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]],
[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]],
[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]],
...,
[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]],
[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]],
[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]]],
device='cuda:0')<span>modeling_bert.py</span>, but I found a special class in <span>modeling_utils.py</span>: <span>class ModuleUtilsMixin</span>, and in its <span>get_extended_attention_mask</span> method, I discovered the clue: def get_extended_attention_mask(self, attention_mask: Tensor, input_shape: Tuple[int], device: device) -> Tensor:
"""
Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
Arguments:
attention_mask (:obj:`torch.Tensor`):
Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
input_shape (:obj:`Tuple[int]`):
The shape of the input to the model.
device: (:obj:`torch.device`):
The device of the input to the model.
Returns:
:obj:`torch.Tensor` The extended attention mask, with a the same dtype as :obj:`attention_mask.dtype`.
"""
# ...
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
return extended_attention_mask<span>BertModel</span>?OK, this involves the inheritance details of BertModel:<span>BertModel</span> inherits from <span>BertPreTrainedModel</span>, which inherits from <span>PreTrainedModel</span>, and <span>PreTrainedModel</span> inherits from <span>[nn.Module, ModuleUtilsMixin, GenerationMixin]</span>three base classes. —A complex encapsulation!
BertModel must call the original attention_mask in some step, invoking get_extended_attention_mask, leading to attention_mask changing from [1, 0] to [0, -1e4] values.
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape, device)
In addition, noteworthy details include:
-
Scaling is performed based on each head’s dimension, for bert-base, this is 8, which is the square root of 64; -
attention_probs not only performs softmax but also applies dropout, which might seem unusual, but this is taken from the original Transformer paper;
-
head_mask is the mask for multi-head calculations mentioned earlier; if not set, it defaults to all 1’s, and thus does not take effect here;
-
context_layer is the product of the attention matrix and the value matrix, originally sized as:
<span>(batch_size, num_attention_heads, sequence_length, attention_head_size)</span>; -
After transposing and viewing, the shape of context_layer returns to <span>(batch_size, sequence_length, hidden_size)</span>.
class BertSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_statesNote: This part also features the combination of LayerNorm and Dropout, but here, dropout occurs first, followed by residual connection and then LayerNorm. The reason for this residual connection is primarily to reduce the training difficulty caused by the depth of the network, making it more sensitive to the original input.
2.2.1.2 BertIntermediate
class BertIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states-
The fully connected layer performs an expansion; in the case of bert-base, the expansion dimension is 3072, which is four times the original dimension of 768;
Note: Why go through a FFN? I don’t know… Google’s recent paper seems to indicate that models with only attention are ineffective:
Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Deptharxiv.org
-
The activation function here defaults to gelu (Gaussian Error Linear Units (GELUS): ; of course, it cannot be computed directly, and can be approximated with an expression containing tanh (omitted).
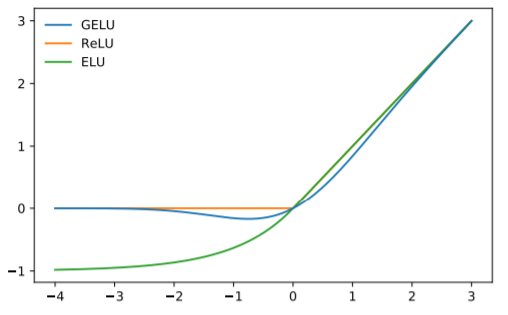
As for why this activation function is used in the transformer…

class BertOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states[CLS], then passes it through a fully connected layer and an activation function to output: (this part is optional as pooling can have many different operations)class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
Takeaways·Summary
In the HuggingFace implementation of the Bert model, various memory-saving techniques are employed:
-
Gradient checkpointing, which does not retain forward propagation nodes, only computes when needed; -
apply_chunking_to_forward, which computes the FFN part in small batches and low dimensions
-
In total, <span>Dropout</span>appears<span>1+(1+1+1)x12=37</span>times; -
In total, <span>LayerNorm</span>appears<span>1+(1+1)x12=25</span>times; -
In total, <span>dense</span>layers appear<span>(1+1+1)x12+1=37</span>times, and not every<span>dense</span>has an accompanying activation function…

References

[1] https://github.com/huggingface/transformers
[2] https://www.zhihu.com/question/395811291/answer/1260290120
[3] https://pytorch.org/docs/stable/checkpoint.html
[4] https://www.zhihu.com/question/341222779/answer/814111138
[5] https://pytorch.org/docs/stable/generated/torch.einsum.html
Recommended Reading:
Visual Enhanced Word Vectors: I Am Word Vectors, I Opened My Eyes!
Transformers Grew Up, What About Its Siblings? (Including Detailed Knowledge Points about Transformers)
ERICA: A Unified Framework for Enhancing Entity and Relation Understanding in Pre-trained Language Models
Click the card below to follow the public account “Machine Learning Algorithms and Natural Language Processing” for more information: