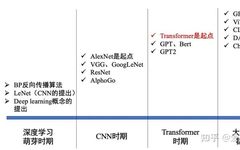
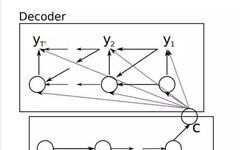
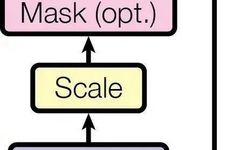
Understanding Attention Mechanisms in Deep Learning
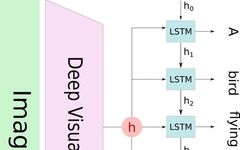
The attention mechanism is potentially a very useful method. In this issue, let’s understand the principles and methods behind the attention mechanism. The original text is in English from https://blog.heuritech.com/2016/01/20/attention-mechanism/ With the development of deep learning and artificial intelligence, many researchers are interested in the “attention mechanism” in neural networks. This article aims to provide … Read more