
Authors: Wang Yun, Taiyuan University/Beijing Normal University; Zhang Zheng, Beijing Normal University
The digital age, also known as the bit age or post-information age, is characterized by multidimensional human-computer interconnection, rapid technology iteration and disruption, and changes in product and service models. Nicholas Negroponte described in his book “Being Digital” a new way of existence for humans applying digital technology to work, live, and learn in digital spaces (1995: 19-26), where rapid computation and processing of natural language, a non-numeric symbol, has become an inevitable trend in the digital age. The combination of mathematics and linguistics has given birth to computational linguistics, which establishes formal mathematical models to analyze and process natural languages using computer programs, simulating part or even all of human linguistic abilities (Wang Yun, Zhang Zheng, 2020: 81). “Due to the improvement of technical capabilities, everything can be translated. Online communication has created a language market where languages from all over the world can enter into communication” (Apter, 2006: 226). From online crowdsourced translation, translation subtitle groups, to platforms like Yiyuan Gutenberg and the widespread use of smartphone translation apps, the translation field is also undergoing a transformation triggered by digital technology. Translation is caught in the tension between the “broad universality form and the precise universality demand,” where the former promotes the globalization of the translation industry, while the latter emphasizes the difficulty and complexity of language and usage (Cronin, 2013: 129). The translation industry has significantly increased its productivity due to machine translation, making translation technology an essential skill for translators to enter the market, and related courses have become an indispensable part of the training system for translation professionals. However, as machine translation gradually embeds itself into human society, it inevitably has negative effects on human language and the subjects, objects, and organizational forms in translation activities. Therefore, it is necessary to analyze the potential risks brought by machine translation and propose targeted control measures to ensure the healthy development of machine translation in the digital age. This article discusses the risks of “machine translation,” which are not the conventional direct economic losses or safety accidents, but rather explores the negative impacts and irreversible consequences that technology may cause to the human ontology, text objects, and organizational forms of translation activities from the perspective of the philosophy of technology. Given this, we must face the risks triggered by “machine translation” in the real world and examine what fundamental impacts and meanings these risks have for human existence.
The interaction between humans and translation technology places translation to some extent within the knowledge and cultural development of “transhumanism.” “The continuous development of technology will significantly enhance human intelligence, physical strength, and psychological quality” (Cronin, 2013: 138). Kevin Kelly proposed the core concept of “machine biotization” (1994:145), where technology imitates the whole of humanity (including human consciousness), becoming a “humanoid” system with an inevitable trend of development, which will inevitably challenge the position of human subjectivity and blur the boundaries of translation subjects. Based on technology, translation activities have developed from machine-assisted human translation to human-assisted machine translation, and even to fully machine translation, making it difficult for users to determine which parts of the translation were completed by machines and which parts were intervened by human translators before and after (Ren Wen, 2019: 49). The challenges posed by machine translation to human translators are not isolated cases, but reflect the general status of human subjectivity in the digital age within the translation field, also illustrating the risk of distortion of human value caused by the over-amplification of its tool value.
(1) Translator Identity Alienation
“Alienation” comes from the Latin word alienus, meaning “other, different, foreigner.” Marxist philosophy holds that alienation is a social phenomenon where human production and its products dominate humans in turn (Marx, et al. 1988: 72). Max Horkheimer also believes that technological knowledge expands the range of human thought and activity, but is also accompanied by a process of dehumanization (2004: v). In alienation, individuals lose their mastery over themselves and are forced into another state of existence that deviates from their true nature, primarily manifested in the dissolution of the translator’s subject identity and the decline of human linguistic and cognitive abilities.
Human practical activities aim to transform the objective world and are a process of interaction between the subject of practice and the object, which must rely on certain means and tools, i.e., the mediators of practice (Marxism Basic Principles Writing Group, 2018: 58-59). In translation activities, the translator and the object of translation are the most common subjects and objects, and machine translation and its usage can be seen as mediators connecting the subject and object. The real-time online language conversion function enhances user autonomy, but this automation and immediacy obscure the essence of “translation,” creating an illusion that translation is an effortless alternative conversion (Cronin, 2013: 135). Some companies overly exaggerate the effectiveness of machine translation, asserting that “machine translation has reached the level of human translation.” Since 2016, conflicts between domestic translation technology research and development companies and practitioners in the language service industry have arisen, largely due to companies failing to adhere to basic principles of commercial ethics during product promotion and sales (Han Lintao, 2019: 55). This approach reflects the ideology of technological determinism (Zhang Zheng, Wang Yun, 2020: 148), positioning human translators in opposition to machine translation and technological development, thereby pushing machine translation, which should occupy a mediating position, into the role of dominating the translator’s subject status, leading to confrontational or inverted relationships in translation activities.
Martin Heidegger proposed that the “highest danger” in the technological age is not the adverse consequences of technology for humanity but the damage, distortion, and loss of the selfhood of humans and existence (Shaoyibo, 1993: 180). Language is the most fundamental structure of the human brain and the basic ability that distinguishes humans from other organisms, while translation is an act that combines rational thinking (observation, comparison, analysis, synthesis, abstraction, and generalization) and non-rational thinking (emotion, intuition, illusion, subconsciousness, inspiration, etc.). The translation ability of human translators must be acquired through extensive targeted training, while the “capability” of machine translation operates based on databases provided by humans according to certain rules. The French biologist Jean-Baptiste Lamarck first proposed the viewpoint of “use it or lose it,” where under the direct influence of a new environment, certain frequently used organs develop and enlarge, while organs that are not frequently used weaken or atrophy (1963: 113). Machine translation can reduce the labor burden on human translators, but the mechanized translation process will damage human language and cognitive abilities. As the “Sapir-Whorf Hypothesis” discusses the determining role of language on thought and culture, the background language system (i.e., grammar) is not only a tool for expressing thoughts but also a shaper of thoughts (Zhang Zheng, Wang Yun, 2018: 102).
The most notable feature of human language is semantic diversity and ambiguity, while the working principle of computers is “black or white” rule-based computation. The translations produced by computers may not necessarily conform to human semantic logic expressions, and choosing a computer translation model means that humans must communicate with the computational rules in some way. “Pre-editing” involves removing non-rule expressions of natural language in advance to approach the logical programming of computer language, which essentially is a collaborative method at the cost of erasing human language characteristics. Performing “post-editing” is akin to processing the semi-finished products produced by machine translation on a text production assembly line, suppressing the creativity of translators. Long-term processing of fragmented machine translations is highly likely to lead to the degradation of language abilities, a decrease in language aesthetic sensitivity, and result in mechanized, singular thinking patterns, distorting or devaluing the translator’s own worth in the process. Under the control of tools, individuals lose the ability to negate, critique, and transcend, making it unwilling and impossible to understand what is happening outside of predetermined rational influences, leading to a false consciousness. When humans are confined within the boundaries of technological production, they lose their essential diversity, entering a world of singular meaning, becoming “one-dimensional individuals” (Marcuse, 1964: 148-149).
(2) Uniformity of Translation Style
Machine translation lacks the capability to decode and recognize context and stylistic features, and the operational mechanisms behind different systems are largely similar, resulting in weak expression of stylistic features in the output translations, making it impossible to achieve “its own creativity.” For example, in the sentence from “Steve Jobs: A Biography” – “We’ve been through so much together and here we are right back where we started 20 years ago – older, wiser – with wrinkles on our faces and hearts” (Isaacson, 2011: 296), we compare the stylistic differences between four human translations (Lin Guoli, 2015: 79-80) and four machine translations, encoding them as MT (Machine Translation) or HT (Human Translation) plus numbers 1-4 (e.g., Table 1). This study selects four representative online translation platforms based on the location of the developer (domestic vs. foreign) and the launch time (over 10 years vs. within 10 years): Google Translate (MT1), DeepL (MT2), Youdao Translation (MT3), and Tencent Translation (MT4), with the text of the translations retained as is. Here, we focus on comparing the stylistic differences of the translations without evaluating the accuracy of the translations.
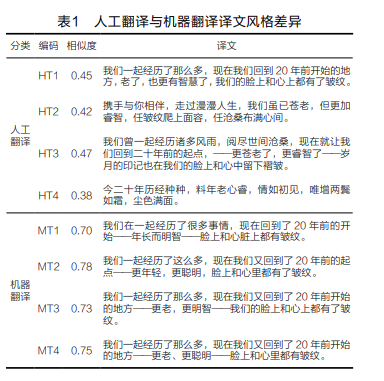
This article utilizes Python for text similarity calculation, based on the formula: , where and represent the two texts being compared, and represent the corresponding vectors of the texts (Hank Town, 2020). Using the cosine similarity algorithm of word vectors, we derive the similarity of each translation with any similar (human or machine) translation, then calculate the average to obtain the similarity index of that translation among similar translations, where the index ranges from 0 to 1, indicating the proportion between completely different and completely identical. The four human translations show considerable stylistic differences, with similarities ranging from 0.38 to 0.47, whether casual and simple, concise and elegant, or classical and profound, reflecting the diversified choices of human translators in presenting text style. The four machine translations show similarities ranging from 0.70 to 0.78, with word order and phrasing being highly similar, and no significant differences in expression. Machine translation prioritizes semantic matching and grammatical correctness, making it difficult to achieve stylistic selection and presentation within existing algorithms. Zhou Lingshun argues that as interpreters, translators must understand the author’s writing background, intent, and era before translation, particularly the author’s personal writing style, which is crucial for accurately understanding the author’s intent and grasping the writing style (2004: 31). However, machine translation cannot comprehend the author’s intent in the same way that human translators can; translations from any machine translation platform are highly mechanized products. George Steiner believes that “the loose and chaotic characteristics of natural language are essential factors that stimulate human imagination; the ambiguity, polysemy, vagueness, and even illogicality and rule-breaking of language are the essence of language” (1975: 246). To enhance accuracy, machine translation inevitably strives to eliminate linguistic ambiguities, reducing unnecessary synonyms, parts of speech, sentence structures, and concepts (Ye Zinan, 2017: 89). The highly automated nature of machines normalizes the mass production of translations, and the hidden risk of “one-size-fits-all” may undermine the “naturalness” of language, leading to a “machine tone” permeating the source language (Chen Jin, 2018: 94), gradually making humans sound like robots in their speech.
(1) Fragmentation of Translation Methods
According to Marxist technological ethics, workers in a machine context are merely a small part of the entire machine labor collaboration, with many rarely considering the driving mechanisms of overall collaboration. They do not need to know where they enter the entire production structure, nor do they need to care about the meaning of their actions (Li Sanhu, 2006: 122). For example, in crowdsourced translation, the emergence of this model not only raises discussions about translation quality, reasonable compensation, and the status of translators, but may also lead to the fragmentation of translation methods (Shao Lu, 2019: 127). Projects are driven by management, and after human translators are assigned tasks, they complete parts individually, making it difficult to maintain an overall grasp of the translation project. Participants have different identity backgrounds and translation purposes, adhering to the principle of obeying project unified decisions, losing the right to judge the rationality of the translations. Developers of translation technology prioritize how to accelerate production speed and reduce costs, neglecting the humanistic care for translators, leading translators to feel the lack of overall value and meaning in their work, and a sense of accomplishment (Li Yan, Xiao Weiqing, 2018: 4).
Heidegger believes that under the influence of technology, humanity is in a framework (Gestell) of coercion (Herausfordern), becoming a stored object, unable to recognize their true self. “Technology is in the realm of revealing and concealing, becoming its essence in the realm of truth” (Heidegger, 2005: 12). Machine translation is also a form of revealing, compelling humans to treat natural language as a stored object to be revealed. Natural language becomes an object to be studied and mined, incorporated into “corpora,” and manipulated through various algorithms to “customize” its equivalent in another language, deeply intruding on the thinking modes of human translators, preventing them from acting according to free will, thus obscuring their essence (Chen Jin, 2018: 93). This change profoundly impacts translators’ self-recognition and self-examination, reshaping the existence value of human translators in translation activities. Meanwhile, the changes in computer systems at both the technical and social levels are becoming increasingly complex, indicating that computer systems have transformed from a tool into an agent (Houwen et al., 2014: 223). The relationship between human translators and machine translation somewhat resembles that of a principal and an agent, where machine translation completes commissioned tasks within limited roles, involving varying degrees of automation and human participation. However, machine translation cannot take responsibility for its work results, nor can it confirm whether the translation quality meets the requirements, ultimately leaving human translators to decide whether adjustments are necessary and how to make them. The translation results are achieved through the combination of human autonomy and machine translation automation, led by human translators, and ultimately serving human interests. Over-reliance on machine translation may undermine this principal-agent relationship, leading to a situation where the agent exercises translation decision-making powers while the principal’s actions are constrained, fundamentally subverting and encroaching upon the subject status of human translators.
One of the core issues in the digital age is how to position human subjectivity, which can serve as a philosophical epistemological basis for reflecting on the value and risks of machine translation. Heidegger’s philosophy of technology has provided direction; humanity should let technology return to serving humans and return to their own “being”. Returning to “being” itself is fundamental to escaping technological alienation (Zhang Tianyong, 2015: 66). The relationship between technology and humans in the digital age is an intersecting conjugate relationship within a pluralistic network (as shown in Figure 1), and the control of machine translation risks can be achieved through the combination of the following three sets of concepts, where the factors highlighting human subjective agency reflect the humanistic values in machine translation activities, while the non-human-controlled factors reflect its technological values.
(1) Combining Subject Agency with Object Constraints
The self-realization perspective emphasizes the freedom and independence of the human subject and its constructive role in society (Lü Jun, 2007: 72). Human translators exercise subject agency, not only issuing commands or providing feedback at the application level but, more importantly, deeply training the machine at the technical level. Human translators will transition from being mere users of translation technology to becoming comprehensive subjects who integrate corpus providers, algorithm correctors, and quality critics. “Under strictly limited scenarios, machine translation can achieve good practical effects in specific fields” (Feng Zhiwei, 2018: 40). The working principle of machine translation is based on binary logic options and is constrained by the quality and quantity of existing data; its optimized development requires more vertical domain language data resource holders to join machine translation development, promoting corpus updates and a virtuous cycle based on optimizing data or improving algorithms to address the object constraints faced by machine translation.
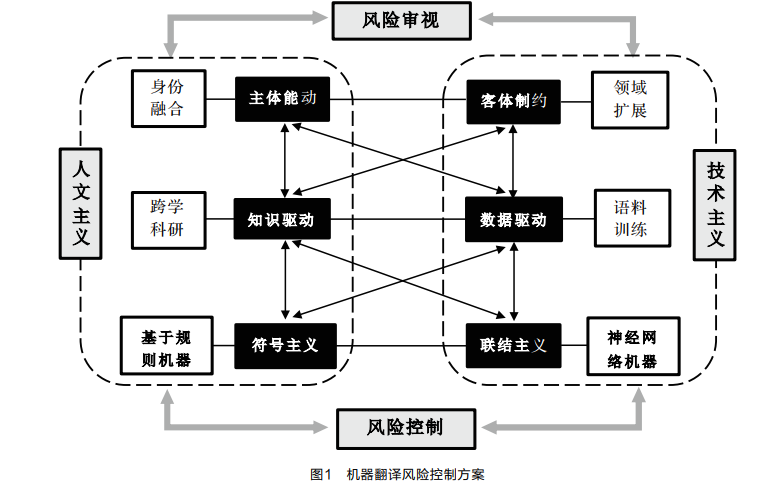
(2) Combining Knowledge-Driven and Data-Driven Approaches
Machine translation possesses interdisciplinary attributes encompassing linguistics, mathematics, computer science, and philosophy. Human translators can leverage linguistic knowledge to diagnose and analyze issues in machine translation, converting them into mathematical expressions that are easier for computers to understand and correct, thereby improving machine translation quality. Alternatively, research can be conducted on the deep mechanisms and operational paradigms of machine translation from both technical and humanistic perspectives, providing humanistic care and ethical guidance for its developers and users to promote the deep development of machine translation and interdisciplinary progress. On the other hand, it is necessary to strengthen domain adaptation training for neural machine translation, enabling the domain-sensitive network to make more accurate judgments by constructing a systematic integration mechanism (Tan Min et al., 2019: 56), utilizing language-rich domains to assist resource-scarce domains in enhancing machine translation quality.
(3) Combining Symbolism and Connectionism
Symbolism is reflected in simulating the human brain using symbolic calculations, while connectionism constructs the brain through parallel computing of artificial neural networks (Xu Yu, 2016: 37-38). Both have significant impacts on the technological development and application of machine translation, forming their respective representative characteristics in cooperation and competition (as shown in Table 2). Rule-based machine translation embodies symbolic thought, modeling translation problems, processing input data, and eliminating alternative values that do not conform to specific models, featuring dynamic debugging, verifiability, and interpretability. However, it requires human revision methods to address semantic understanding and grammatical rule differences between different languages. As natural language processing transitions to the deep learning stage, the field of machine translation is also shifting towards connectionist thought, using electronic devices to mimic human brain neural network models, employing regression models during data training to adjust intermediate variable weight coefficients without requiring users to set rules. Based on sufficient sample data, neural networks can deduce the translation model with the least error. Meanwhile, artificially set rules for interlingual feature matching of new terms can improve the accuracy of named entities. The combination of symbolism and connectionism is complementary and can promote the optimized development of machine translation.

The “invisible revolution” triggered by technological concepts in the digital age is ubiquitous, and the translation technology field is gradually transitioning from fully manual to human-machine interaction, and then to dehumanization. Under the impact of rapid iterations in machine translation technology, human translators need to consciously exercise their correction, judgment, and feedback functions from the perspective of subject agency, embracing and transforming technology to avoid becoming mere appendages to technology. The development of machine translation is a process of merging human natural language with computer language under the care of humanism, as well as a process of mutual shaping and improvement between humans and technology. Following the path of combining subject agency with object constraints, knowledge-driven with data-driven approaches, and symbolism with connectionism will help to better achieve a relationship model of interdependence and conjugate coexistence between humans and technology.

