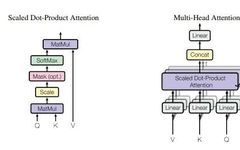
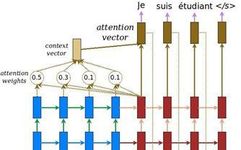
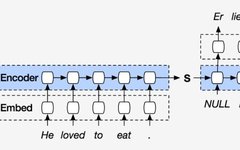
Research on CNN-BiLSTM Short-term Power Load Forecasting Model Based on Attention Mechanism and ResNet
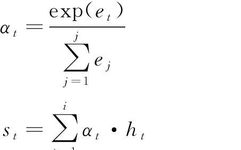
Research on CNN-BiLSTM Short-term Power Load Forecasting Model Based on Attention Mechanism and ResNet WANG Lize1,2, XIE Dong1,2*, ZHOU Lifeng1,2, WANG Hanqing1,2 (1.School of Civil Engineering, University of South China, Hengyang, Hunan 421001, China;2.Hunan Engineering Laboratory of Building Environmental Control Technology, University of South China, Hengyang, Hunan 421001, China) Abstract:Short term power load forecasting is … Read more