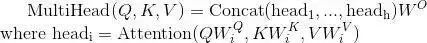This article shares a detailed blog post about the Transformer from Harvard University, translated by our lab.
The Transformer architecture proposed in the paper “Attention is All You Need” has recently attracted a lot of attention. The Transformer not only significantly improves translation quality but also provides a new structure for many NLP tasks. Although the original text is clearly written, many people find it difficult to implement correctly.Therefore, we wrote an annotated document for this article and provided line-by-line implementation code for the Transformer. This document removes some sections from the original text and rearranges them, adding appropriate annotations throughout the article. Additionally, this document is completed in Jupyter notebook format, which is itself directly runnable code, with a total of 400 lines of library code that can process 27,000 tokens per second on 4 GPUs.To run this work, you first need to install PyTorch. The complete notebook file and dependencies for this document can be found on GitHub or Google Colab.It is important to note that this annotated document and code are intended only as an introductory tutorial for researchers and developers. The code provided primarily relies on OpenNMT implementation, and for more information about other implementations of this model, you can check Tensor2Tensor (TensorFlow version) and Sockeye (MXNet version).
Content DirectoryPreparationBackgroundModel Structure– Encoder and Decoder– Encoder– Decoder– Attention– Application of Attention in the Model– Position-wise Feedforward Network– Embedding and Softmax– Positional Encoding– Complete Model(Due to the original text’s length, the remaining parts will be in the next article)Training– Batching and Masking– Training Loop– Training Data and Batching– Hardware and Training Progress– Optimizer– Regularization– Label SmoothingFirst Example– Data Generation– Loss Calculation– Greedy DecodingReal Example– Data Loading– Iterator– Multi-GPU Training– Additional Components for Training System: BPE, Search, AveragingResults– Attention VisualizationConclusionThe annotations in this document are all provided in citation form, with the main content coming from the original text.
1.Background
Reducing the computation cost of sequence processing tasks is an important issue and the motivation behind networks like Extended Neural GPU, ByteNet, and ConvS2S. These mentioned networks are all based on CNNs and compute hidden representations of all input and output positions in parallel.In these models, the number of operations required to relate signals from two arbitrary input or output positions grows with the distance between the positions; for example, ConvS2S grows linearly, while ByteNet grows logarithmically, making it more challenging to learn dependencies between positions that are far apart. In contrast, the Transformer reduces the number of operations to a constant level.Self-attention, sometimes referred to as Intra-attention, performs attention over different positions in a single sentence and obtains a representation of the sequence. It can be effectively applied to many tasks, including reading comprehension, summarization, text entailment, and task-independent sentence representation. End-to-end networks are generally based on recurrent attention mechanisms rather than sequence-aligned RNNs, and there is evidence that they perform well on simple language question answering and language modeling tasks.To our knowledge, the Transformer is the first model that relies entirely on self-attention without using sequence-aligned RNNs or convolutions to compute input-output representations.
2.Model Structure
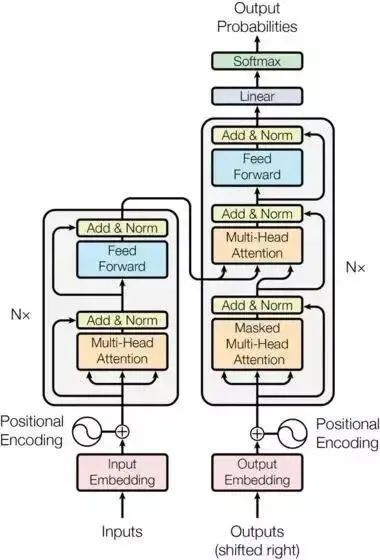
Currently, most popular neural sequence transformation models have an Encoder-Decoder structure. The Encoder maps the input sequence to a continuous representation sequence.For the encoded z, the Decoder generates one symbol at a time until the complete output sequence is generated. For each decoding step, the model is autoregressive, meaning it uses previously generated symbols as additional input when generating the next symbol.The overall structure of the Transformer is shown in the following diagram, where both the Encoder and Decoder use self-attention, point-wise, and fully connected layers. The general structure of the Encoder and Decoder is shown in the left and right halves of the diagram, respectively.
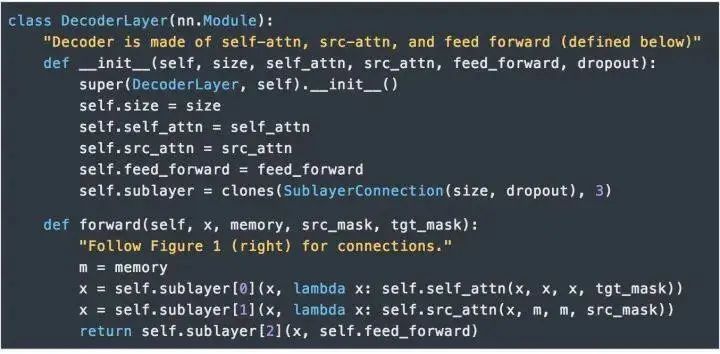
2.Encoder and Decoder
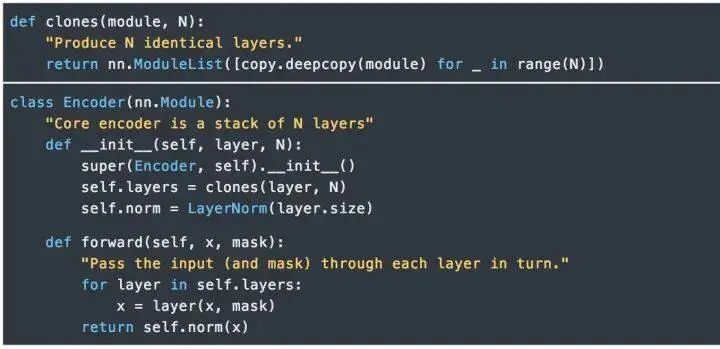
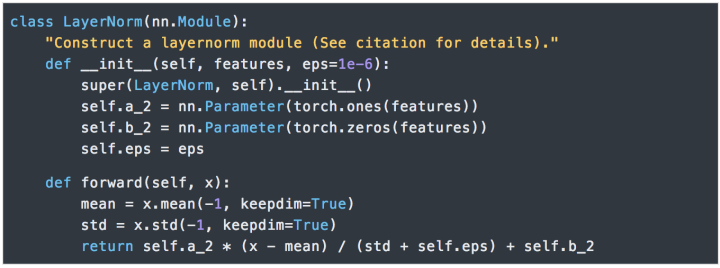
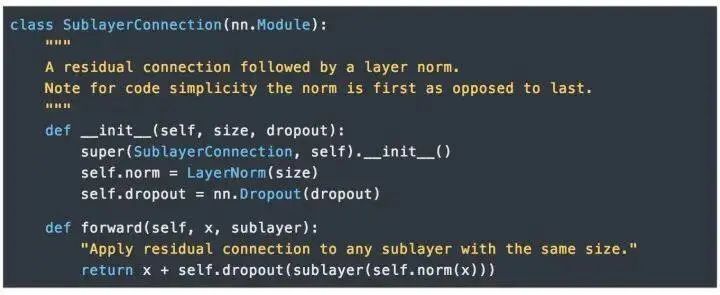
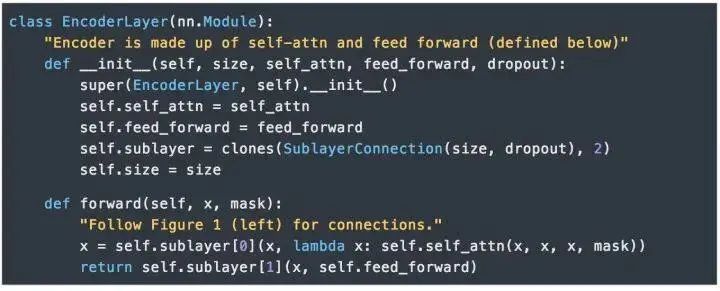
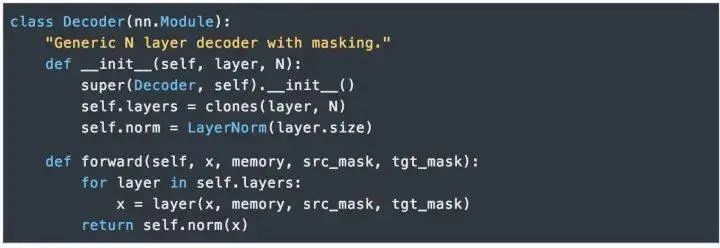
EncoderThe Encoder consists of N=6 identical layers.We use residual connections (Residual Connection) between every two sub-layers [11] and normalization [12].Each layer consists of two sub-layers. The first sub-layer implements “multi-head” self-attention, while the second sub-layer is a simple position-wise fully connected feedforward network.DecoderThe Decoder is also composed of N=6 identical layers.In addition to the two sub-layers in each encoder layer, the decoder also inserts a third sub-layer that performs “multi-head” attention on the output of the encoder stack. Similar to the encoder, we use residual connections on both ends of each sub-layer for shortcut connections, followed by layer normalization.
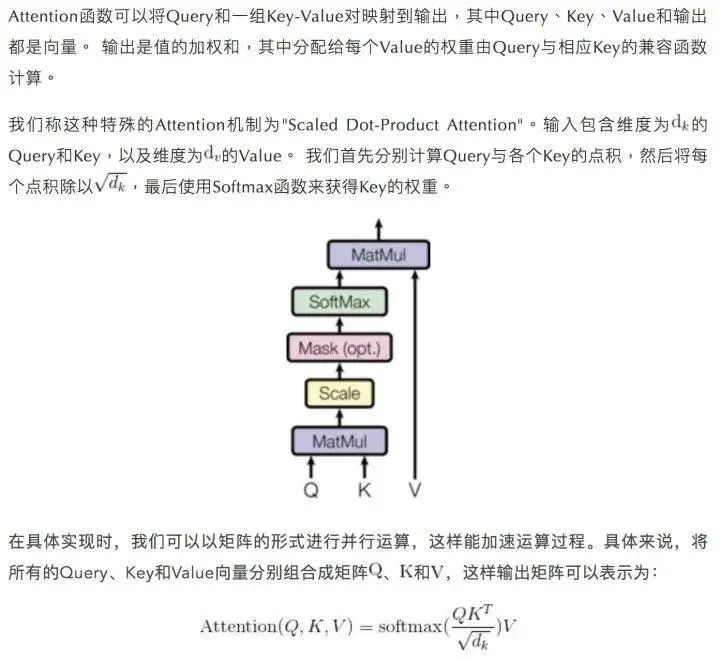
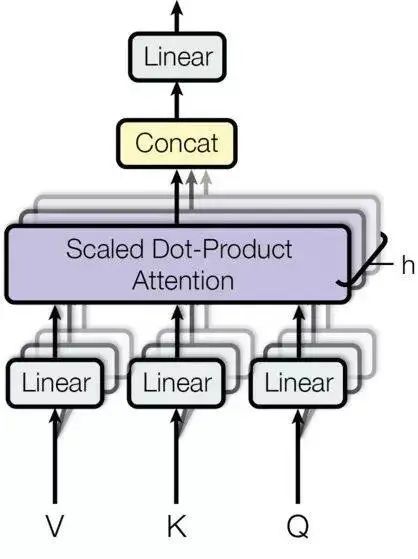
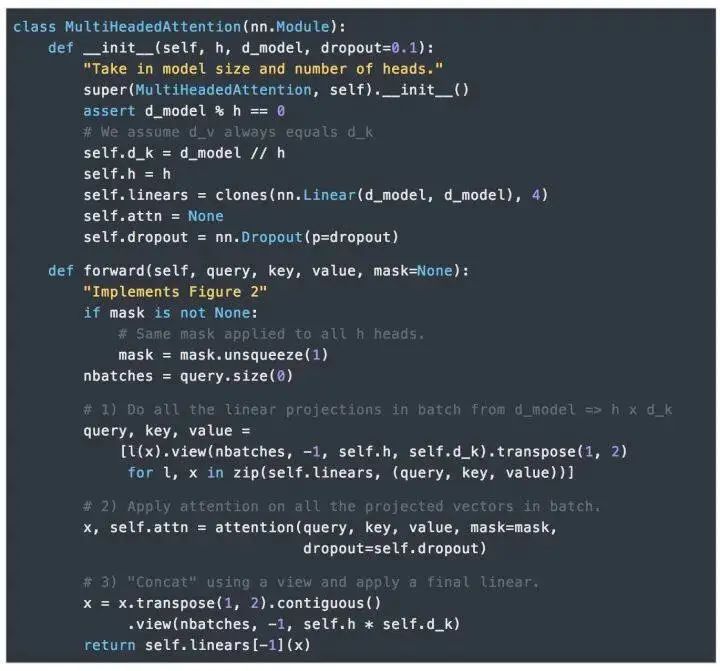
3.Attention
The “multi-head” mechanism allows the model to consider attention from different positions, and additionally, “multi-head” attention can represent different relational information in different subspaces. Using single-head attention generally does not achieve this effect.
4.Application of Attention in the Model
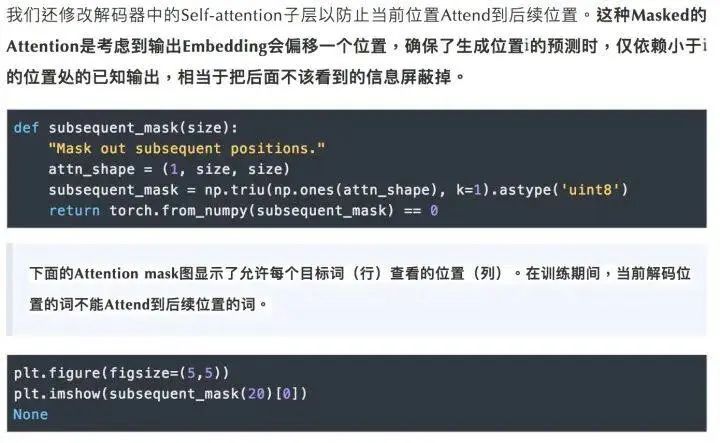
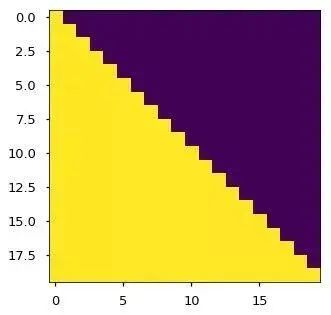
In the Transformer, “multi-head” attention is used in three different ways:1) In the “Encoder-Decoder Attention” layer, the Query comes from the previous decoder layer, while the Key and Value come from the output of the Encoder. Each position in the Decoder attends to all positions in the input sequence, which is consistent with the classic Encoder-Decoder attention mechanism in Seq2Seq models.2) In the self-attention layer of the Encoder. In the self-attention layer, all Keys, Values, and Queries come from the same place, which are the outputs from the previous layer in the Encoder. Each position in the current layer of the Encoder can attend to all positions in the previous layer.3) Similarly, the self-attention layer in the Decoder allows each position in the Decoder to attend to the current decoding position and all previous positions. Here, it is necessary to mask the leftward information flow in the Decoder to maintain the autoregressive property. The specific implementation method is to mask (set to negative infinity) all corresponding illegal connections in the inputs of the softmax of the scaled dot-product attention.
5.Position-wise Feedforward Network
6.Embedding and Softmax
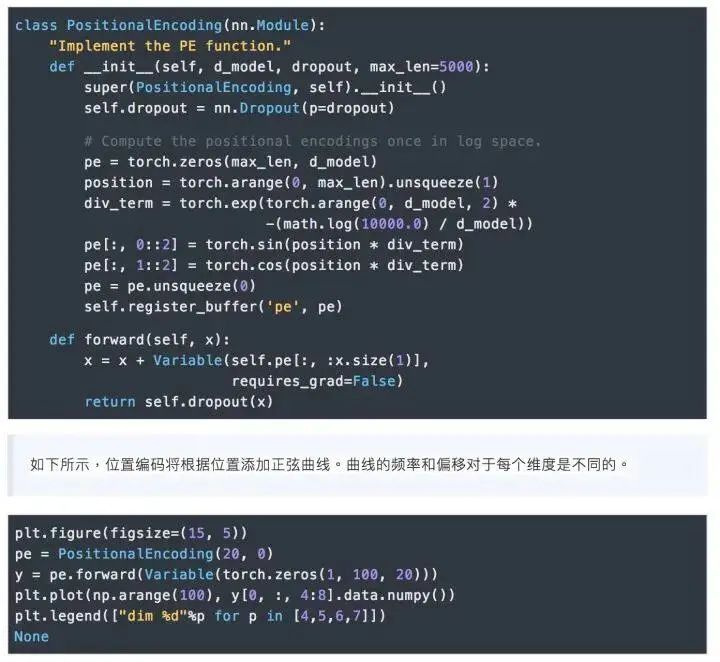
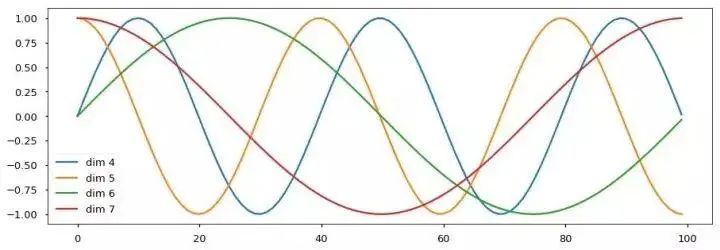
7.Positional Encoding
We also tried using pre-trained positional embeddings, but found that the results of both versions were basically the same. We chose the sine curve version of the implementation because this version allows the model to handle sequences longer than the maximum sequence length in the training corpus.
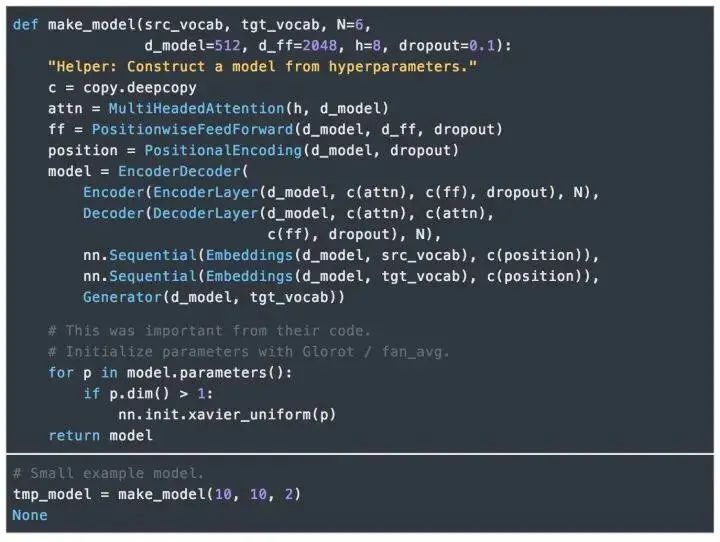
8.Complete Model
The following defines a function to connect the complete model and set hyperparameters.