Click the "Xiaobai Learns Vision" above, select to add "star" or "top"
Heavyweight content delivered to you first
Jishi Guide
Surpassing fine-tuning, LoRA, VPT, etc. with only a small number of parameters fine-tuned!

Paper link: https://arxiv.org/pdf/2305.15542
GitHub link: https://github.com/bfshi/TOAST
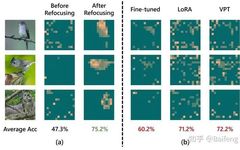
We found that when fine-tuning large models on a downstream task, current methods (fine-tuning, LoRA, prompt tuning, etc.) often fail to focus the model’s attention on information relevant to the downstream task. For example, in Figure 1(b) below, we transferred a pretrained ViT to a downstream bird classification task, but found that the attention obtained after fine-tuning is often very chaotic, which may affect the model’s performance on the downstream task.
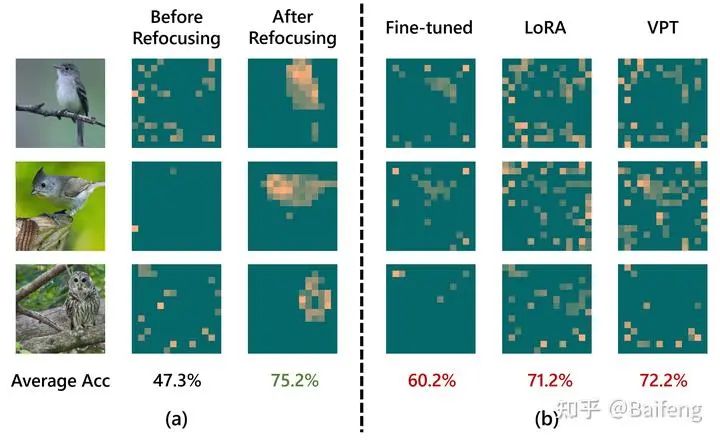
In this article, we found that by refocusing the model’s attention on information relevant to the downstream task (Figure 1(a)), we can greatly improve the model’s performance on downstream tasks. Our method builds on our previous work on top-down attention:
CVPR23 Highlight|Vision Transformer with Top-Down Attention Capability
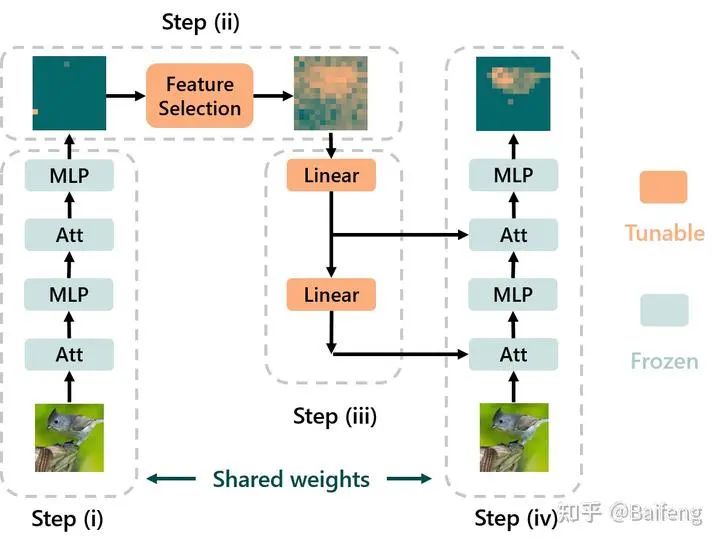
In simple terms, top-down attention is a mechanism that can adjust the model’s attention based on the task currently being performed. In this work, our method of refocusing attention involves first fixing the pretrained model, adding a top-down attention module on top, and then only fine-tuning this top-down attention module on the downstream task:
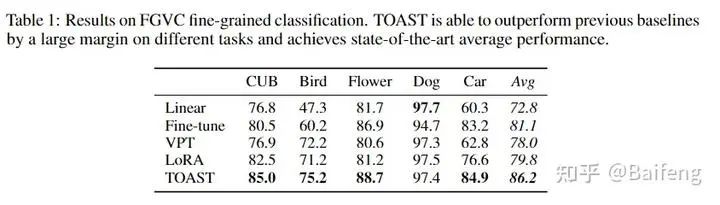
We conducted experiments on both visual and language tasks, and visually we can surpass fine-tuning, LoRA, VPT, etc. with only a small number of parameters fine-tuned:
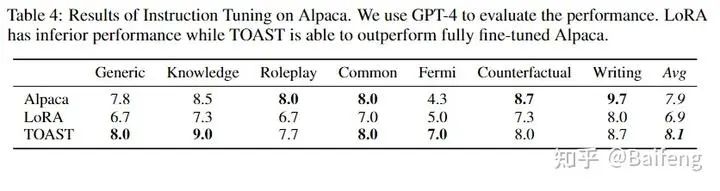
On language tasks, we can surpass the fine-tune or LoRA versions of Alpaca with only about 7% of the parameters fine-tuned:
Everyone is welcome to comment!
Download 1: Chinese Version Tutorial for OpenCV-Contrib Extension Module
Reply "Extension Module Chinese Tutorial" in the backend of "Xiaobai Learns Vision" public account to download the first Chinese version of the OpenCV extension module tutorial covering over twenty chapters including installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: 52 Lectures on Python Vision Practical Projects
Reply "Python Vision Practical Projects" in the backend of "Xiaobai Learns Vision" public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: 20 Lectures on OpenCV Practical Projects
Reply "OpenCV Practical Projects 20 Lectures" in the backend of "Xiaobai Learns Vision" public account to download 20 practical projects based on OpenCV for advanced learning of OpenCV.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat ID below to join the group, remark: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for remarks, otherwise, it will not be approved. After successful addition, invitations will be sent to relevant WeChat groups based on research direction. Please do not send advertisements in the group, otherwise, you will be removed. Thank you for your understanding~