
Source: | Zhihu
Link: | https://zhuanlan.zhihu.com/p/40920384
Author: | Yuanche.Sh
Editor: | Machine Learning Algorithms and Natural Language Processing WeChat account
This article is for academic sharing only. If there is any infringement, please contact us to delete it.
Understand the seq2seq attention model in five minutes.
This article uses images to detail the entire process of the seq2seq + attention model, helping everyone to understand the important model for tasks like machine translation without pain.
seq2seq is a network with an Encoder-Decoder structure, where the input is a sequence, and the output is also a sequence. The Encoder transforms a variable-length signal sequence into a fixed-length vector representation, while the Decoder converts this fixed-length vector into a variable-length target signal sequence. –Jianshu
Alright, let’s stop talking and start looking at the images.
Main Framework
Formulas (best to skip to the images)
Input: 
Output: 
(1)  , The Encoder accepts the word embedding of each word and the hidden state from the previous time step. The output is the hidden state at this time step.
, The Encoder accepts the word embedding of each word and the hidden state from the previous time step. The output is the hidden state at this time step.
(2)  , The Decoder accepts the word embedding of the words in the target sentence and the hidden state from the previous time step.
, The Decoder accepts the word embedding of the words in the target sentence and the hidden state from the previous time step.
(3)  , The context vector is a weighted average of the hidden states output by the encoder.
, The context vector is a weighted average of the hidden states output by the encoder.
(4)  , Each encoder’s hidden states correspond to the weights.
, Each encoder’s hidden states correspond to the weights.
(5)  , A score is calculated using the hidden states from the decoder and the hidden states from the encoder to compute the weights (4).
, A score is calculated using the hidden states from the decoder and the hidden states from the encoder to compute the weights (4).
(6)  , The context vector and the hidden states from the decoder are concatenated.
, The context vector and the hidden states from the decoder are concatenated.
(7)  , The final output probability is calculated.
, The final output probability is calculated.
Detailed Diagram
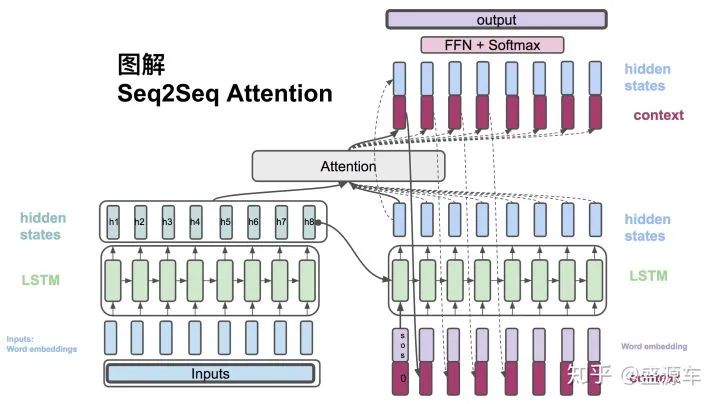
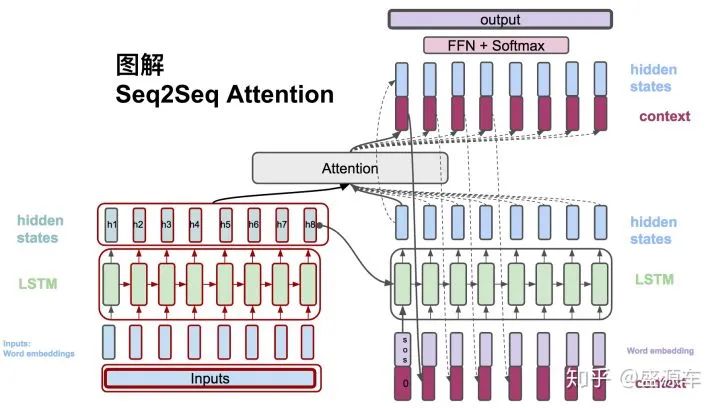
(1)  , The Encoder accepts the word embedding of each word and the hidden state from the previous time step. The output is the hidden state at this time step.
, The Encoder accepts the word embedding of each word and the hidden state from the previous time step. The output is the hidden state at this time step.
(2)  , The Decoder accepts the word embedding of the words in the target sentence and the hidden state from the previous time step.
, The Decoder accepts the word embedding of the words in the target sentence and the hidden state from the previous time step.
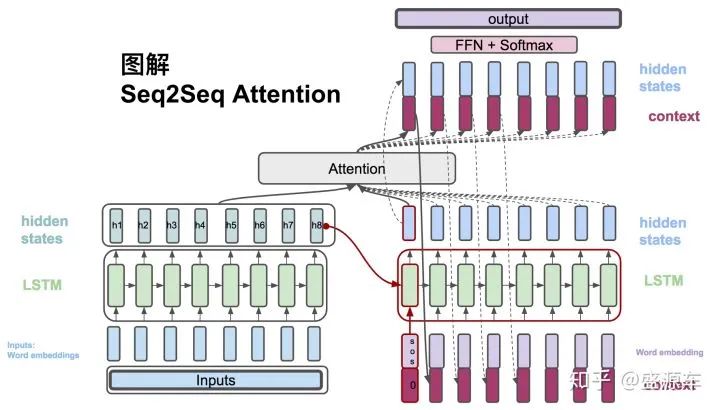
(3)  , The context vector is a weighted average of the hidden states output by the encoder.
, The context vector is a weighted average of the hidden states output by the encoder.
(4)  , Each encoder’s hidden states correspond to the weights.
, Each encoder’s hidden states correspond to the weights.
(5)  , A score is calculated using the hidden states from the decoder and the hidden states from the encoder to compute the weights (4).
, A score is calculated using the hidden states from the decoder and the hidden states from the encoder to compute the weights (4).
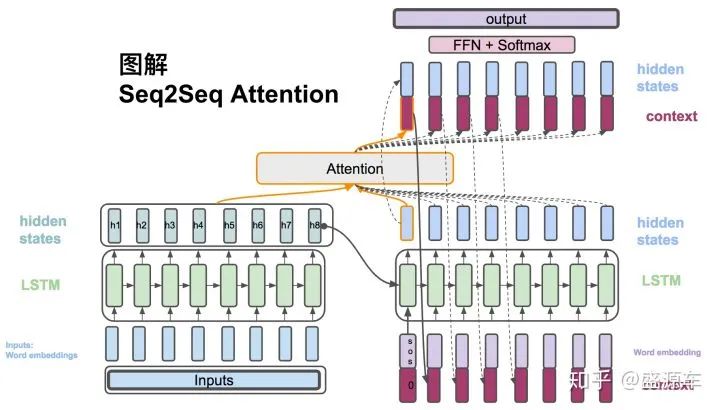
Next Time Step
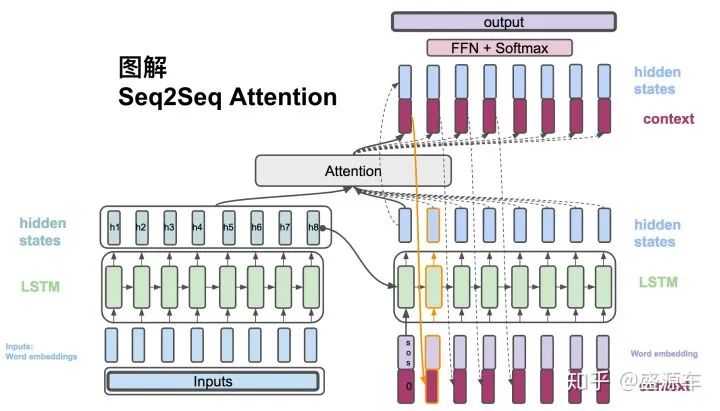
(6)  , The context vector and the hidden states from the decoder are concatenated.
, The context vector and the hidden states from the decoder are concatenated.
(7)  , The final output probability is calculated.
, The final output probability is calculated.
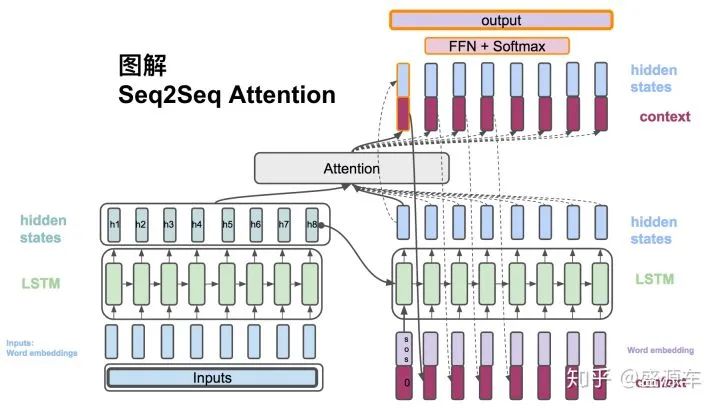
Luong mentioned three methods for calculating the score. Here are the first two illustrated:
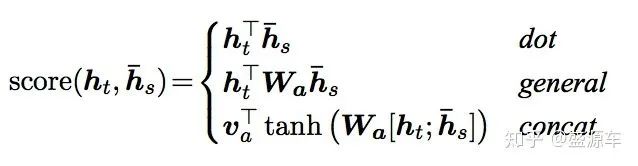
Attention score function: dot
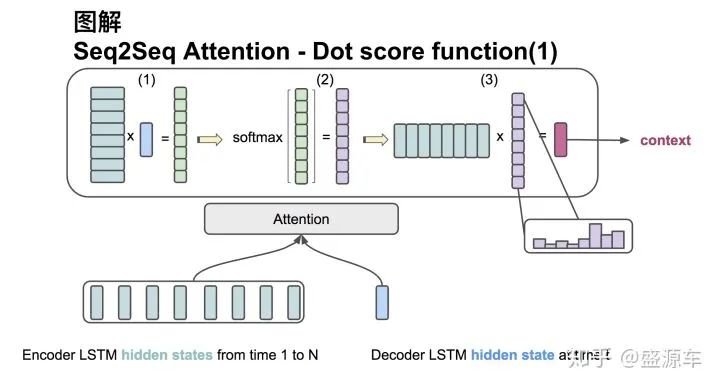
The input is all hidden states from the encoder H: size (hid dim, sequence length). The hidden state at one time point of the decoder, s: size (hid dim, 1).
Step One: Rotate H to (sequence length, hid dim) and perform a dot product with s to obtain a score of size (sequence length, 1).
Step Two: Apply softmax to the score to get weights that sum to 1.
Step Three: Multiply H by the weights obtained in Step Two to get a context vector of size (hid dim, 1).
Attention score function: general
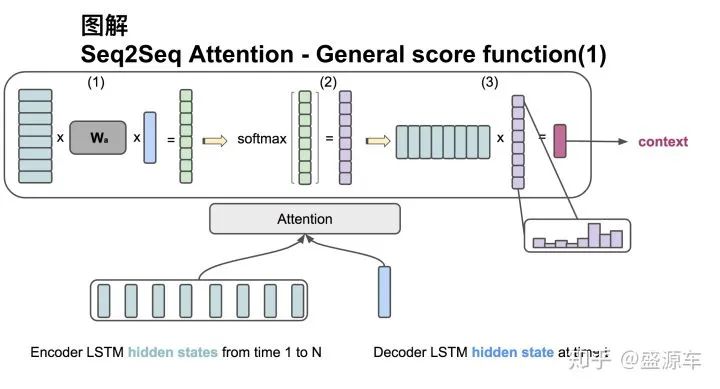
The input is all hidden states from the encoder H: size (hid dim1, sequence length). The hidden state at one time point of the decoder, s: size (hid dim2, 1). The dimensions of the two hidden states are not the same.
Step One: Rotate H to (sequence length, hid dim1) and perform a dot product with Wa [size hid dim1, hid dim 2], then do a dot product with s to obtain a score of size (sequence length, 1).
Step Two: Apply softmax to the score to get weights that sum to 1.
Step Three: Multiply H by the weights obtained in Step Two to get a context vector of size (hid dim, 1).
Conclusion
The best way to understand a model is to mentally walk through each step from input to model to output, observing how tensors flow. I hope this helps everyone ~ please give it a thumbs up!
Postscript
It has been almost a year since I wrote this illustration, and I want to respond to some detail questions in the comments here:
This article mainly introduces an idea of the Attention mechanism, which is essentially a weighted average of hidden states. As for how to use c, s, and calculate it, there are many methods. If you don’t understand the basic concept, you can refer to this article. If you have questions about the details, the correct approach is to look at the open-source code. After all, it all comes down to practical experience.
Exciting news! The WeChat group for Natural Language Processing is now established.
You can scan the QR code below, and the assistant will invite you to join the group for discussions.
Note: Please modify your remarks to [School/Company + Name + Field] when adding.
For example —— Harbin Institute of Technology + Zhang San + Dialogue System.
Account owner, please avoid business promotions. Thank you!

Recommended Reading:
【Long Article Detailed Explanation】From Transformer to BERT Model
Sai Er Translation | Understanding Transformer from Scratch
Seeing is Believing! A Step-by-Step Guide to Building a Transformer with Python