
1.The Essence of Attention
The core logic: from focusing on everything to focusing on key points
-
The Attention mechanism can grasp the key points when processing long texts, without losing important information.
-
The Attention mechanism is like how humans look at images; when we look at a picture, we do not see the entire content clearly but focus our attention on the focal point of the image.
-
Our visual system is a type of Attention mechanism, concentrating limited attention on key information to save resources and quickly obtain the most effective information.
The visual system is a type of Attention mechanism
Transformer: “Attention is All You Need”
-
The Transformer model is completely based on the Attention mechanism, avoiding traditional RNN or CNN structures.
-
It introduces the Self-Attention mechanism, allowing the model to model associations among all elements in the input sequence.
-
Multi-Head Attention enables the model to capture information from multiple perspectives within the input sequence.
-
It lays the foundation for subsequent large-scale pre-trained language models (such as BERT, GPT, etc.).
The Attention mechanism in AI: Attention -> Transformer -> BERT, GPT -> NLP
2.The Principle of Attention
The initial experience of the principle:A small story explaining the principle of Attention
-
The Attention mechanism is like having a large number of books in a library, each with specific numbers and content. When wanting to learn about a certain topic (like “Marvel”), one would look for books related to that topic.
-
Books that are directly related to “Marvel” (like comics and movies) would be read carefully (high weight), while books related to “Marvel” indirectly (like World War II books) would only need a quick glance (low weight).
-
This process embodies the core idea of the Attention mechanism: allocating attention based on the importance of information.
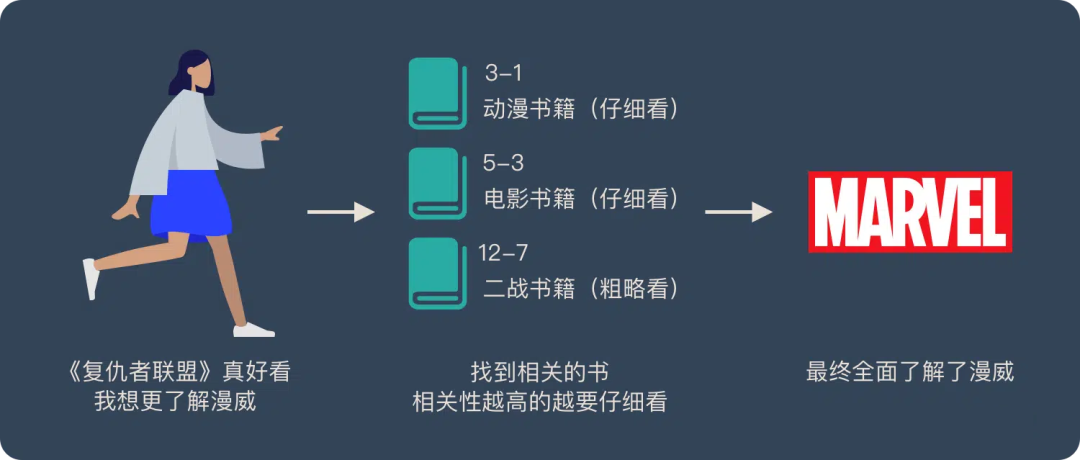
Attention mechanism:: understanding Marvel
Principle of Attention::3-stage breakdown
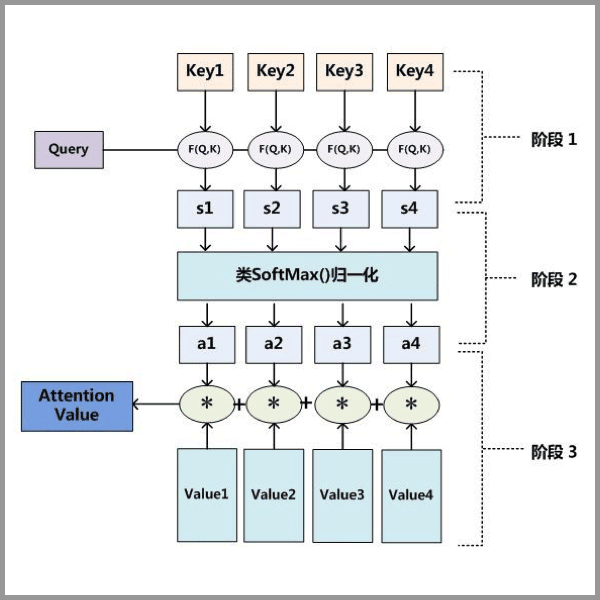
Diagram of the Attention mechanism principle
-
Step 1: Calculate the similarity between query and key to obtain weights.
-
Step 2: Normalize the weights to get directly usable weights.
-
Step 3: Perform a weighted sum of the weights and value.
During the RNN era, it was a period of rote memorization; the Attention mechanism learned to grasp the main points, evolved to the Transformer, integrating knowledge and demonstrating excellent expressive learning capabilities, and then to GPT and BERT, accumulating practical experience through large-scale multi-task learning, resulting in overwhelming combat effectiveness.
3.Applications of Attention
CNN + Attention:
The convolution operation of CNN can extract important features, which is also a form of the Attention idea. However, the convolution receptive field of CNN is local and needs to stack multiple convolution layers to expand the field of view.
The Attention approach for CNN is as follows:
-
Applying Attention before convolution: For example, Attention-Based BCNN-1 calculates feature vectors by applying Attention to two input sequence vectors, then concatenates them to the original vector as input for the convolution layer. -
Applying Attention after convolution: For example, Attention-Based BCNN-2 applies Attention to the outputs of the convolution layers of two texts as input for the pooling layer. -
Applying Attention in the pooling layer: For example, Attention pooling first uses LSTM to learn a good sentence vector as a query, then uses CNN to learn a feature matrix as a key, and finally uses the query to generate weights for the key to perform Attention, obtaining the final sentence vector.
LSTM + Attention:
LSTM has a gating mechanism, where the input gate selects which current information to input, and the forget gate selects which past information to forget, which is also a form of Attention to some extent. However, LSTM needs to capture sequential information step by step, and its performance on long texts will gradually decline with the increase in steps, making it difficult to retain all useful information.
LSTM usually needs to obtain a vector before performing tasks, common approaches include:
-
Directly using the last hidden layer (which may lose some previous information and make it difficult to express the entire text) -
Averaging hidden layers across all steps equally (treating all steps equally). -
The Attention mechanism weights the hidden layers across all steps, focusing attention on the most important hidden layer information from the entire text. This performs better than the previous two methods and facilitates visualization to observe which steps are important.